最新

一种已证实的方法,可以让你记住数据科学概念,直到你需要它们。
自学数据科学的问题 每次我想用Anaconda安装一个库时,命令中的“-c”部分总是在移动。所以,像大多数人一样,我会在一天中搜索3-4次: conda install -c conda-forge library_name 这很熟悉吗? 这个小例子暗示了我们今天学习数据科学和机器学习的一个根本性缺陷:数据科学知识比空气还便宜,所以我们没有认真对待学习它。 我们看到大

发布于 2023-5-24 下午3:12 阅读数 2505
Python中的自动特征工程
机器学习 | Python | 数据科学 图片来自 Unsplash,摄影师 Alina Grubnyak 任何数据科学家或机器学习专业人员最关键的技能之一,就是从给定的数据集中提取更深入、更有意义的特征。这个概念,更常被称为特征工程,可能是在建模机器学习算法时掌握的最强大的技术之一。 从数据中学习需要很多工程。尽管现代高级工具(如sklearn)已经将

发布于 2023-5-24 下午2:22 阅读数 2289
新版Scikit-Learn更适合进行数据分析
Scikit-Learn(Scikit-learn)于去年12月份发布了一个重大稳定更新(v.1.2.0-1),终于可以尝试一些新功能了。现在它与Pandas更加兼容,一些新功能也将有助于回归和分类任务。下面,我将通过一些新的更新及其使用示例进行介绍。让我们开始吧! 与Pandas兼容: 在使用回归或神经网络等机器学习模型之前,对一些数据进行标准化是一种常见
发布于 2023-5-24 下午1:15 阅读数 1771
可扩展的注释服务 — Marken
简介 在 Netflix,我们有数百个微服务,每个服务都有自己的数据模型或实体。例如,我们有一个存储电影实体元数据的服务或一个存储图像元数据的服务。所有这些服务在以后都想要注释它们的对象或实体。我们的团队 Asset Management Platform 决定创建一个名为 Marken 的通用服务,允许 Netflix 的任何微服务注释它们的实体。 注释 有

发布于 2023-5-24 下午1:5 阅读数 1629
激光雷达技术发展(第一部分:未来技术)
使用学习改进RADAR和LIDAR之间的外参校准(arXiv) 作者:Peng Jiang,Srikanth Saripalli 摘要:LIDAR和RADAR是自动驾驶系统中常用的两种传感器。两者之间的外参校准对于有效的传感器融合至关重要。由于RADAR测量的低精度和稀疏信息,这种校准面临挑战。本文提出了一种用于自动驾驶系统中3D RADAR-LIDAR校准的新方法。该方法采用简

发布于 2023-5-24 中午12:28 阅读数 1849
JAX和可组合的程序转换
https://github.com/google/jax 的“关于”部分如下所述。 Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more “可组合变换”是什么意思?在 NeurIPS2020: JAX 生态系统 Meetup 的视频中,DeepMind 的一位工程师进行了解释。 举个例子,考虑以下函数。 def fn(x, y): return

发布于 2023-5-24 上午11:15 阅读数 1610
如何设置自动GPT:自主GPT-4人工智能
图片由 Jim Clyde Monge 提供 AI开发的惊人速度已经快速加速了我们对人工通用智能(或AGI)的方法,发布了一个名为 Auto-GPT 的开源Python应用程序。 Auto-GPT是什么? Auto-GPT是一个实验性的开源应用程序,是完全自主GPT-4实现的早期实例。 将其视为一个助手,它可以自行决策以实现目标,而不是您指定下一步要做什么。 Auto-GPT配

发布于 2023-5-24 上午11:9 阅读数 2408
理解LLMOps:大语言模型操作
“抱歉,我们无法像这样发货。它太大了……”——生产中的大型语言模型(LLMs)(图片作者绘制) 本文最初发表在Weights & Biases的“Fully Connected”博客上,发布日期为2023年4月21日。 OpenAI的ChatGPT发布似乎打开了生产中大型语言模型(LLMs)的潘多拉魔盒。不仅邻居们现在会跟你闲聊人工智能(AI),而且机器学习(ML)社区正在讨论另一

发布于 2023-5-23 下午5:52 阅读数 3987
6种建立数据科学团队最佳实践的方法
Marvin Meyer 在 Unsplash 上的照片 数据科学是一门将传统的数学和统计学与大规模计算和现代机器学习和深度学习技术相结合,从数据中生成洞见的领域。 数据科学学科是复杂的,本质上是实验性的,并且存在大量不确定性。与软件工程等相关领域一样,数据科学家团队需要以受控的方式处理代码开发。然而,除了这些,数据科学家还需要处

发布于 2023-5-23 下午4:49 阅读数 1522
在Python中对随机森林进行超参数调整
改进随机森林的第二部分 我们已经构建了一个随机森林模型来解决我们的机器学习问题(也许是通过遵循这个端到端指南),但我们对结果并不太满意。我们有哪些选择?正如我们在这个系列的第一部分中看到的那样,我们的第一步应该是收集更多数据并进行特征工程。收集更多数据和进行特征工程通常在时间投入与性能改善之间具有最大的回报

发布于 2023-5-23 下午2:9 阅读数 3921
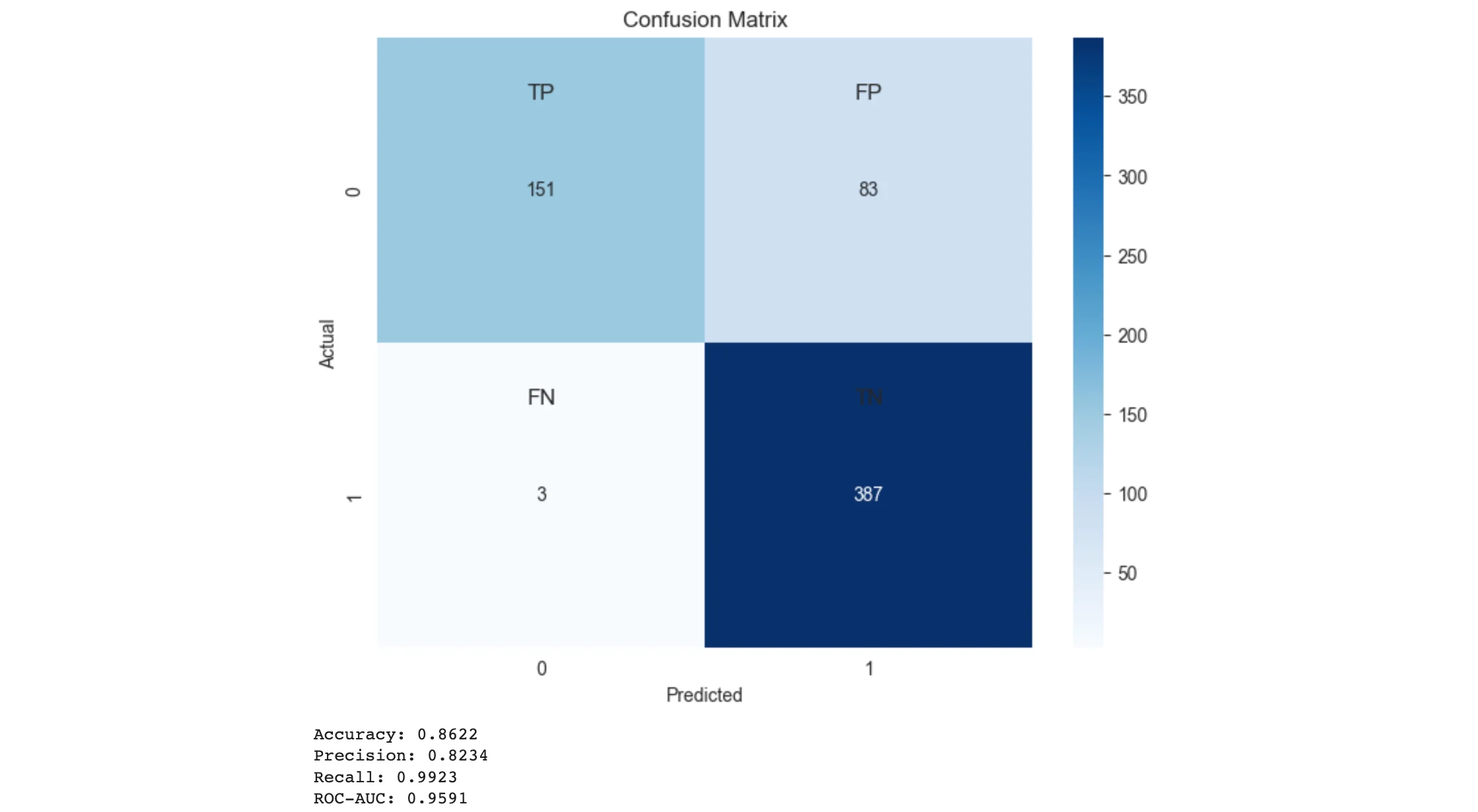
超越准确性:使用混淆矩阵探索分类器的性能
我的CNN模型检测肺炎的混淆矩阵,图片来源:作者 介绍 准确率通常是最常用的指标,它通过考虑正确预测结果的比例来衡量分类器的整体正确性。虽然准确率提供了一个有用的概述,但在不平衡的数据集中,其中正和负结果的发生率有显著差异,它可能会误导。在这种情况下,必须考虑精度、召回率和其他指标,以全面了解分类器的性能。 混淆矩
发布于 2023-5-23 中午12:36 阅读数 1840
每周我会访问10个惊人的网站,以保持在数据世界的最前沿。
现如今,数据内容无处不在,无论是 Medium、Twitter 还是 Substack。如果你想知道目前被认可的知识,你应该继续阅读所有这些内容。但如果你想知道未来的主题,你需要跨出去。 Zhamak Dehghani 没有在 Medium 上发布她的开创性的 Data Mesh 专著,我也没有看到她在 Twitter 上宣传。它存在于主流之外,几乎一年之久,直到 Twitter、Medium

发布于 2023-5-22 下午8:6 阅读数 1990
开始使用 Bloom
图片由 Patrick Tomasso 在 Unsplash 上提供。 目录 什么是 Bloom?一些注意事项 设置环境 下载预训练的分词器和模型 运行推理:更好的响应策略 结论和下一步 参考文献 Bloom 是什么,我们为什么应该谨慎对待 Bloom 是来自 BigScience 的一个新的 176B 参数的多语言 LLM(Large Language Model)。BigScience 是一个由全球数百名

发布于 2023-5-22 下午7:54 阅读数 2904
介绍 PivotUI:再也不用 Pandas 来对数据进行 GroupBy 和 Pivot 操作了
动机 Pivot 和 Grouping 操作是每个典型表格数据分析过程中的基本操作。pivot_table() 和 groupby() 方法是 Pandas 中最常用的方法之一。 Grouping 主要用于理解分类数据,让你可以计算数据中各个组的统计量。 Grouping 的表示(图片由作者提供) 另一方面,Pivot 表允许你交叉表格化数据,以进行精细的分析。 Pivot 表的表示(图片由

发布于 2023-5-22 下午7:40 阅读数 2517
两个绝妙的Jupyter技巧,肯定能为你节省数小时的工作时间
Jupyter Notebooks以其简单、流畅、适合初学者、时尚的设计,几乎是今天任何面向Python的任务所必需的。回想起来,没有交互式Python(IPython)工具像Jupyter那样,我甚至无法想象我的生活会是什么样子。 Jupyter(作者创建的图像) 实际上,IPython最显著的优点是通过在内存中保留对象,只要内核处于活动状态,就可以减少重新运行脚本的摩

发布于 2022-11-10 上午8:0 阅读数 1854
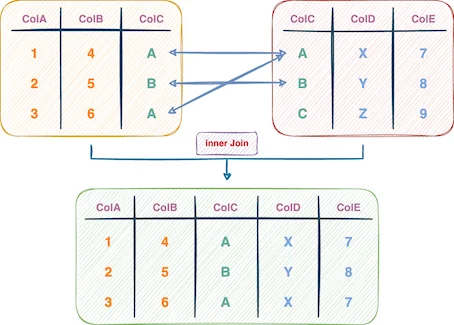
是时候告别 Pandas 中的 Merge 方法了
Photo by Alain Pham on Unsplash Pandas 中的 merge() 方法无疑是数据科学家在数据科学项目中最常用的方法之一。 该方法源自 SQL 中的表连接概念,并扩展到了 pythonic 环境中的表连接,基于一个或多个列的匹配值将两个 Pandas 数据帧合并。 下图展示了这一过程: 连接表的图形概述(作者提供) merge() 方法的直观性使其成为 Pa
发布于 2022-10-4 上午8:0 阅读数 1821
MLops:我最喜欢的数据科学项目Github模板
简述: 本文介绍了一个我常用的 Git 项目结构,这个结构可以作为数据科学项目的起点,并讨论了一些有助于组织代码的包。我还实现了一个基本的 CI 流水线,可以自动化代码质量分析。 引言 从头开始设置 Github 存储库始终是一个需要反思的主题。在我的数据科学家之旅中,我遇到了一些包和结构,它们使我的工作生活更加轻松。它们保证了

发布于 2022-9-4 上午8:0 阅读数 1659
如何打造一个强大的数据科学作品集
建立一个数据科学项目集是一个很好的学习机会,同时也非常有效地展示你的技术专长。 图片来自 Alex Padurariu 的 Unsplash 在规划如何成为数据科学家时,其中最重要的一步就是决定如何展示你的技能、成就和知识。 一个专业的项目集对于数据科学家来说是建立联系的重要手段,为了开始,评估你已经掌握(或正在学习)的技能。基于这些技

发布于 2022-7-20 上午8:0 阅读数 1837
度量和损失函数有什么区别?
与人工智能交朋友 你有没有使用你的损失函数来评估你的机器学习系统的性能?这是一个错误,但别担心,你不是孤单的。 这是一个普遍的误解,可能与软件默认值、大学课程格式和决策者缺席在人工智能方面有关。 在本文中,我将解释为什么你需要两个独立的模型评分函数进行评估和优化...可能还需要第三个用于统计测试。 图片来自Unsplash

发布于 2022-6-18 上午8:0 阅读数 1871
任何学习数据科学的人都应该了解的6种机器学习算法
机器学习是数据科学学习者应该掌握的领域之一。如果你是数据科学新手,你可能听过“算法”或“模型”这些词,但不知道它们与机器学习有什么关系。 机器学习算法被分类为监督学习或非监督学习。 监督学习算法对标记的输入和输出数据(也称为目标)之间的关系进行建模。然后使用这个模型来预测使用新标记的输入数据的标签的新观察结果。如

发布于 2022-6-15 上午8:0 阅读数 1851

