
直观的Transformer系列NLP
这是我关于Transformer系列的第三篇文章。我们按自上而下的方式介绍它的功能。在之前的文章中,我们了解了Transformer是什么,它的架构以及它的工作原理。
在本文中,我们将进一步深入探讨多头注意力,它是Transformer的大脑。
以下是系列文章的简要概述。我的目标是不仅了解事物的工作方式,还要了解它为什么以这种方式工作。
-
功能概述 (Transformer的用途以及它为什么比RNN更好。架构的组成部分,以及在训练和推断期间的行为)
-
工作原理 (内部运作端到端。数据流动和执行的计算,包括矩阵表示)
-
多头注意力——本文 (在Transformer中关于注意力模块的内部工作)
-
为什么注意力提高性能 (不仅了解注意力的作用,还要了解为什么它能如此有效。注意力如何捕捉句子中单词之间的关系) 如果你对NLP应用有兴趣,我还有一些其他的文章可以推荐。
-
束搜索 (语音转文字和NLP应用常用的算法,以提高预测精度)
-
Bleu分数 (Bleu分数和单词错误率是NLP模型的两个重要指标)
注意力在Transformer中的使用
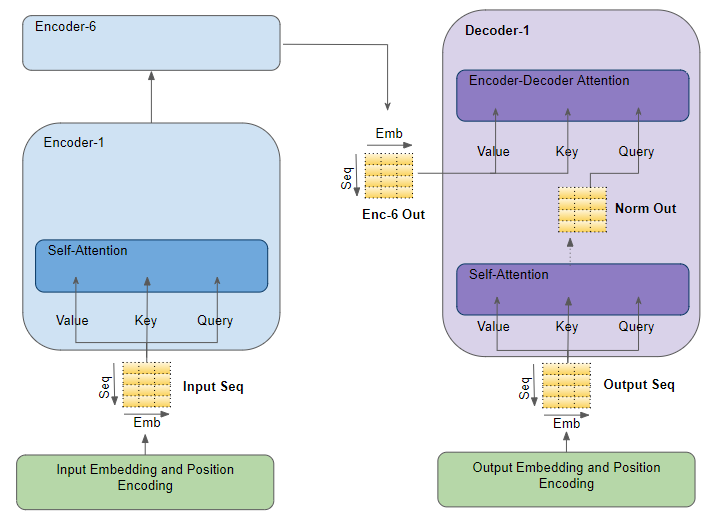
正如我们在第二部分中所讨论的,注意力在Transformer中有三个使用场景:
- 编码器中的自注意力——输入序列关注自身
- 解码器中的自注意力——目标序列关注自身
- 解码器中的编码器-解码器注意力——目标序列关注输入序列

(作者提供的图片)
注意力输入参数——查询、键和值
注意力层以三个参数的形式接收输入,称为查询(Query)、键(Key)和值(Value)。
这三个参数的结构相似,序列中的每个单词都由一个向量表示。
编码器自注意力
输入序列被馈送到输入嵌入和位置编码中,为输入序列中的每个单词产生一个编码表示,捕捉每个单词的含义和位置。这被馈送到自注意力中的第一个编码器中的所有三个参数(Query, Key和Value)中,然后也为输入序列中的每个单词产生一个编码表示,该表示现在还包括每个单词的注意力分数。随着它通过堆栈中的所有编码器,每个自注意力模块也将自己的注意力分数添加到每个单词的表示中。
(作者提供的图片)
解码器自注意力
对于解码器堆栈,目标序列被馈送到输出嵌入和位置编码中,为目标序列中的每个单词产生一个编码表示,捕捉每个单词的含义和位置。这被馈送到自注意力中的第一个解码器中的所有三个参数(Query, Key和Value)中,然后也为目标序列中的每个单词产生一个编码表示,该表示现在还包括每个单词的注意力分数。
在通过层归一化后,它被馈送到第一个解码器中的编码器-解码器注意力的查询参数中。
编码器-解码器注意力
除此之外,堆栈中的最终编码器的输出也被传递到编码器-解码器注意力的值和键参数中。
因此,编码器-解码器注意力同时获得目标序列(来自解码器自注意力)和输入序列(来自编码器堆栈)的表示。因此,它产生一个表示,其中包括每个目标序列单词的注意力分数,该表示捕捉输入序列的注意力分数的影响。
随着它通过堆栈中的所有解码器,每个自注意力和每个编码器-解码器注意力也将自己的注意力分数添加到每个单词的表示中。
多重注意头
在Transformer中,注意力模块并行地重复多次计算。其中每一个被称为一个注意头(Attention Head)。注意力模块将其查询、键和值参数N分为多个部分,并将每个分割独立地通过一个单独的头部传递。所有这些相似的注意力计算然后组合在一起,产生最终的注意力分数。这被称为多头注意力,使得Transformer能够更好地编码每个单词的多个关系和细微差别。

(作者提供的图片)
为了确切了解数据在内部是如何处理的,让我们在训练Transformer解决翻译问题时,走过一遍注意力模块的工作方式。我们将使用训练数据的一个样本,其中包括一个输入序列(英文中的“你很受欢迎”)和一个目标序列(西班牙语中的“De nada”)。# 注意力超参数
有三个超参数决定了数据的维度:
- 嵌入向量的宽度 — 嵌入向量的宽度(我们在示例中使用宽度为6)。该维度在Transformer模型中被沿用,并且有时被称为其他名称,例如“模型大小”等。
- 查询大小(等于键和值大小)— 用于生成查询、键和值矩阵的三个线性层的权重大小(我们在示例中使用查询大小为3)
- 注意力头数(我们在示例中使用2个头)
此外,我们还有批量大小,给我们一个样本数量的维度。
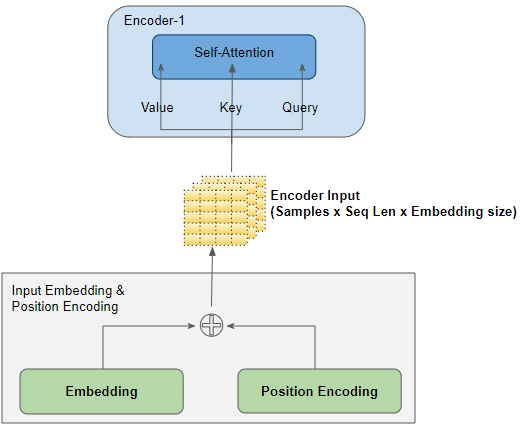
输入层
输入嵌入和位置编码层产生一个形状为(样本数量,序列长度,嵌入大小)的矩阵,该矩阵被馈送到堆栈中的第一个编码器的查询、键和值。
(作者提供的图片)
为了简单可视化,我们将在图片中省略批量维度,并专注于剩余维度。

(作者提供的图片)
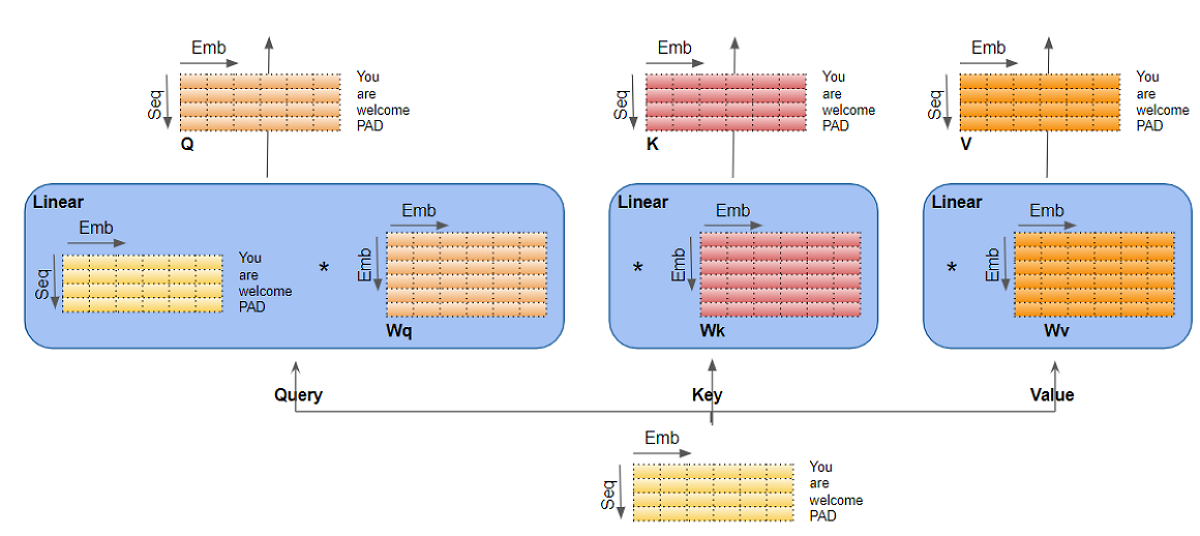
线性层
查询、键和值有三个独立的线性层。每个线性层都有自己的权重。输入通过这些线性层传递以生成Q、K和V矩阵。
(作者提供的图片)
在注意力头之间分割数据
现在数据被分割到多个注意力头中,以便每个头都可以独立处理它。
然而,重要的是要理解这只是一个逻辑分割。查询、键和值并没有被物理分割成单独的矩阵,每个注意力头都有一个。一个单独的数据矩阵用于查询、键和值,分别有逻辑上不同的矩阵部分用于每个注意力头。同样,没有单独的线性层,每个注意力头都有一个线性层。所有的注意力头共享同一个线性层,但仅在其‘自己’数据矩阵的逻辑部分上操作。
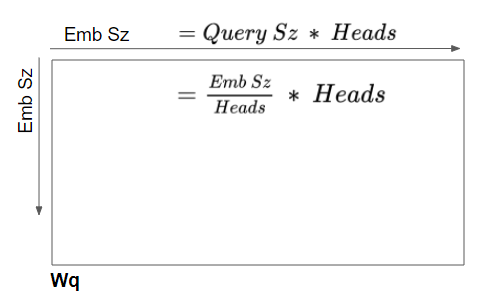
每个头的线性层权重被逻辑上分区
这种逻辑分割是通过均匀地在注意力头之间分割输入数据以及线性层权重来实现的。我们可以通过选择如下的查询大小来实现:
查询大小 = 嵌入大小 / 注意力头数
(作者提供的图片)
在我们的示例中,这就是为什么查询大小=6/2=3。即使层权重(和输入数据)是一个单独的矩阵,我们也可以将其视为为每个头‘堆叠在一起’的单独的层权重。
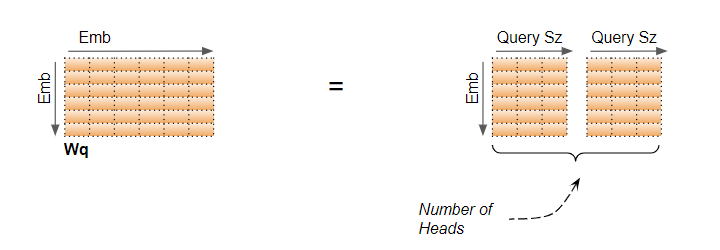
(作者提供的图片)
因此,所有头的计算可以通过单个矩阵操作来完成,而不需要N个单独的操作。这使得计算更加高效,同时保持模型简单,因为只需要较少的线性层,就能实现独立注意力头的强大功能。
重塑Q、K和V矩阵
由线性层输出的Q、K和V矩阵被重塑以包括一个显式的头维度。现在每个‘切片’对应于每个头的矩阵。
然后通过交换头和序列维度再次重塑该矩阵。虽然批量维度没有绘制,但是Q的维度现在为(批量、头、序列、查询大小)。

Q矩阵通过增加头维度进行重塑,然后通过交换头和序列维度再次重塑。 (作者提供的图片)
在下图中,我们可以看到我们的示例Q矩阵在经过线性层之后被分割的完整过程。
最后一个阶段仅用于可视化 — 即使Q矩阵是一个单独的矩阵,我们也可以将其视为每个头逻辑上独立的Q矩阵。
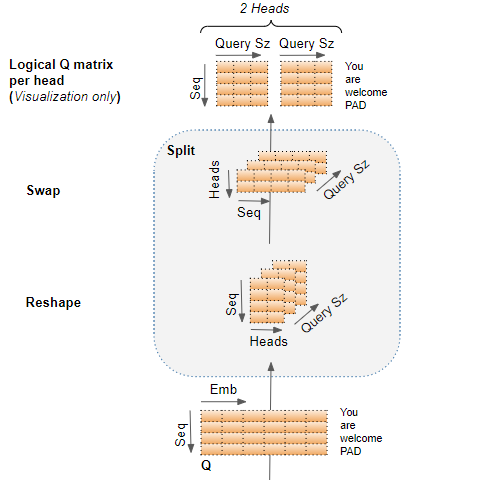
Q矩阵分割到注意力头中(作者提供的图片)
我们现在可以计算注意力分数。
为每个头计算注意力分数
现在,Q、K和V三个矩阵被分割到头部。它们被用于计算注意力分数。
我们将展示单个头的计算,仅使用最后两个维度(序列和查询大小),并跳过前两个维度(批量和头)。实质上,我们可以想象我们正在查看的计算对于每个头和每个批次中的每个样本都被‘重复’(尽管显然,它们是作为单个矩阵操作而不是循环发生的)。
第一步是在Q和K之间进行矩阵乘法。
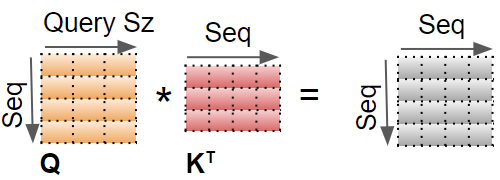
(作者提供的图片)
现在将掩码值添加到结果中。在编码器自我注意力中,掩码用于掩盖填充值,以便它们不参与注意力分数的计算。
在解码器自我注意力和解码器编码器注意力中应用不同的掩码,稍后我们将在流程中介绍。
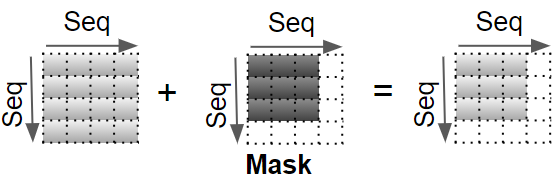
(作者提供的图片)
现在将结果缩放,即除以查询大小的平方根,然后应用Softmax。
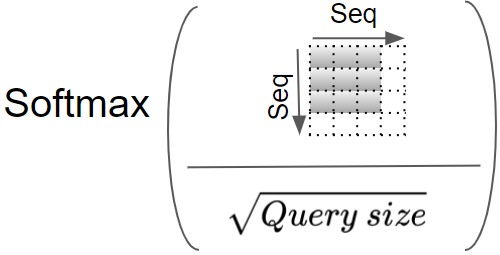
(图片来自作者)
将 Softmax 的输出和 V 矩阵进行另一次矩阵乘法运算。
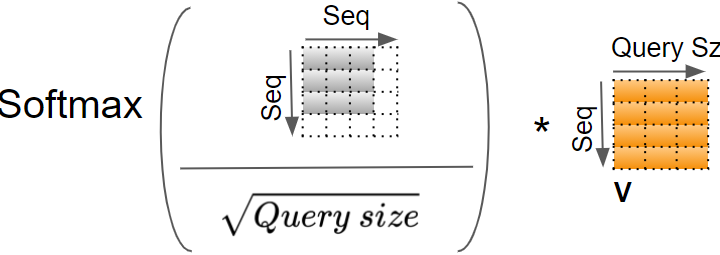
(图片来自作者)
编码器自注意力中 Attention Score 的完整计算如下:
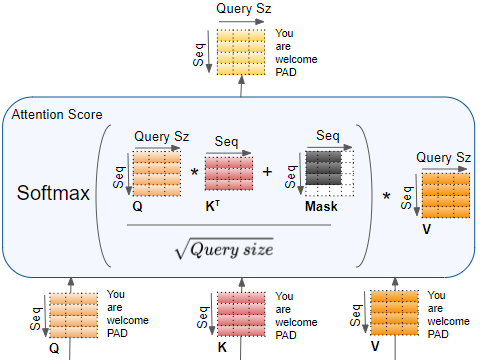
(图片来自作者)
将每个头部的 Attention Scores 合并
现在,我们已经有了每个头部的独立 Attention Scores,需要将它们合并成一个单一的分数。这个合并操作本质上是分割操作的反向过程。
它通过简单地重塑结果矩阵来消除头部维度完成。步骤如下:
- 通过交换头部和序列维度重塑 Attention Score 矩阵。换句话说,矩阵形状从 (Batch, Head, Sequence, Query size) 变为 (Batch, Sequence, Head, Query size)。
- 通过重塑到 (Batch, Sequence, Head * Query size) 来折叠头部维度。这将每个头部的 Attention Score 向量有效地连接成一个合并的 Attention Score。
由于嵌入大小 = Head * Query size,合并后的 Score 是 (Batch, Sequence, Embedding size)。在下面的图片中,我们可以看到示例 Score 矩阵的完整合并过程。

(图片来自作者)
端到端的多头注意力
将所有内容组合在一起,这就是多头注意力的端到端流程。
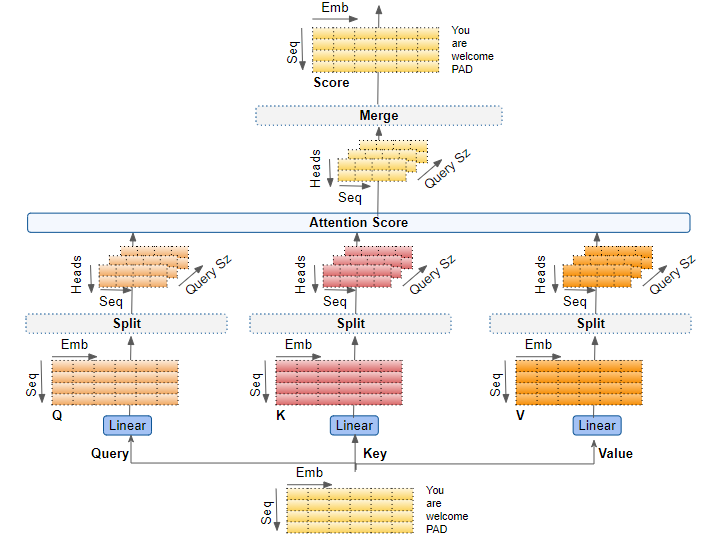
(图片来自作者)
多头分割可以捕获更丰富的解释
嵌入向量捕获单词的含义。在多头注意力的情况下,正如我们所见,输入(和目标)序列的嵌入向量在多个头部上逻辑上被分割。这意味着什么?
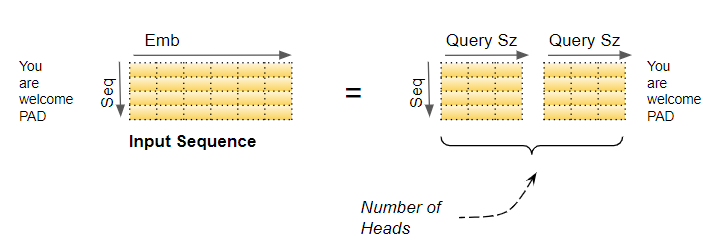
(图片来自作者)
这意味着嵌入的不同部分可以学习与序列中的其他单词相关的单词含义的不同方面。这允许 Transformer 捕获更丰富的序列解释。
这可能不是一个现实的例子,但它可能有助于建立直觉。例如,一个部分可以捕获名词的“性别”(男性,女性,中性),而另一个部分可以捕获名词的“数量”(单数 vs 复数)。在许多语言中,这可能很重要,因为需要使用的动词取决于这些因素。
解码器自注意力和掩码
解码器自注意力的工作方式与编码器自注意力相同,只是它对目标序列的每个单词进行操作。

(图片来自作者)
同样,掩码掩盖了目标序列中的填充单词。
解码器编码器注意力和掩码
编码器-解码器注意力从两个来源获取其输入。因此,与计算每个输入单词与其他输入单词之间的交互的编码器自注意力和计算每个目标单词与其他目标单词之间的交互的解码器自注意力不同,编码器-解码器注意力计算每个目标单词与每个输入单词之间的交互。

(图片来自作者)
因此,结果注意力分数中的每个单元格对应于一个 Q(即目标序列单词)与所有其他 K(即输入序列)单词和所有 V(即输入序列)单词之间的交互。
同样,掩码掩盖了目标输出中的后续单词,如本系列的第二篇文章中所详细解释的那样。
结论
希望这让你对 Transformer 中的 Attention 模块有了很好的了解。当与我们在第二篇文章中概述的 Transformer 的端到端流程结合在一起时,我们现在已经覆盖了整个 Transformer 架构的详细操作。
我们现在确切地了解了 Transformer 所做的事情。但我们还没有完全回答 Transformer 的注意力为什么执行它所做的计算的问题。为什么它使用查询、键和值的概念,为什么它执行我们刚刚看到的矩阵乘法?
我们有一个模糊的直觉,即它“捕获每个单词与其他单词之间的关系”,但这到底意味着什么?这如何使 Transformer 的注意力具有理解序列中每个单词细微差别的能力?













评论(0)