

Scikit-Learn(Scikit-learn)于去年12月份发布了一个重大稳定更新(v.1.2.0-1),终于可以尝试一些新功能了。现在它与Pandas更加兼容,一些新功能也将有助于回归和分类任务。下面,我将通过一些新的更新及其使用示例进行介绍。让我们开始吧!
与Pandas兼容:
在使用回归或神经网络等机器学习模型之前,对一些数据进行标准化是一种常见的技术,以确保不同范围的特征在预测时得到平等的重要性(如果或者必要时)。Scikit-Learn提供了各种预处理API,例如StandardScaler、MaxAbsScaler等。新版本中,即使在预处理之后,也可以保持数据框架的格式,请看下面:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
########################
X, y = load_wine(as_frame=True, return_X_y=True)
# available from version >=0.23; as_frame
########################
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,
random_state=0)
X_train.head(3)

数据集Wine的一部分,以数据框架格式呈现
新版本包括一个选项,即使在标准化之后也可以保持此数据框架格式:
############
# v1.2.0
############
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().set_output(transform="pandas")
## change here
scaler.fit(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled.head(3)

数据框架格式保持不变,即使是在标准化之后。
以前,它会将格式更改为Numpy数组:
###########
# v 0.24
###########
scaler.fit(X_train)
X_test_scaled = scaler.transform(X_test)
print (type(X_test_scaled))
>>> <class 'numpy.ndarray'>
由于数据框架格式保持不变,因此我们不需要关注列,就像我们在Numpy数组格式下所需要的那样。分析和绘图变得更加容易:
fig = plt.figure(figsize=(8, 5))
fig.add_subplot(121)
plt.scatter(X_test['proline'], X_test['hue'],
c=X_test['alcohol'], alpha=0.8, cmap='bwr')
clb = plt.colorbar()
plt.xlabel('Proline', fontsize=11)
plt.ylabel('Hue', fontsize=11)
fig.add_subplot(122)
plt.scatter(X_test_scaled['proline'], X_test_scaled['hue'],
c=X_test_scaled['alcohol'], alpha=0.8, cmap='bwr')
# pretty easy now in the newer version to see the effect
plt.xlabel('Proline (Standardized)', fontsize=11)
plt.ylabel('Hue (Standardized)', fontsize=11)
clb = plt.colorbar()
clb.ax.set_title('Alcohol', fontsize=8)
plt.tight_layout()
plt.show()

图1:标准化前后的特征依赖性!(来源:作者的笔记本)
即使在管道中构建时,管道中的每个转换器都可以配置为返回数据框架,如下所示:
from sklearn.pipeline import make_pipeline
from sklearn.svm import SVC
clf = make_pipeline(StandardScaler(), SVC())
clf.set_output(transform="pandas") # change here
svm_fit = clf.fit(X_train, y_train)
print (clf[:-1]) # StandardScaler
print ('check that set_output format indeed remains even after we build a pipleline: ', '\n')
X_test_transformed = clf[:-1].transform(X_test)
X_test_transformed.head(3)
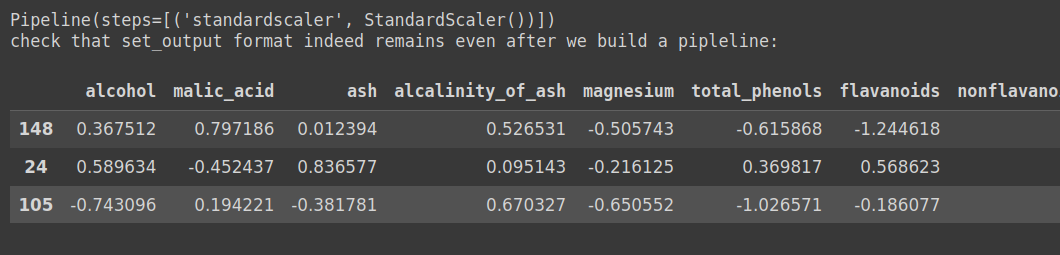
数据框架格式可以保持不变,即使在管道内部!
获取数据集更快,更高效:
OpenML是一个共享数据集的开放平台,Sklearn中的数据集API提供了fetch_openml函数来获取数据。通过更新后的Sklearn,此步骤在内存和时间上更加高效。
from sklearn.datasets import fetch_openml
start_t = time.time()
X, y = fetch_openml("titanic", version=1, as_frame=True,
return_X_y=True, parser="pandas")
# # parser pandas is the addition in the version 1.2.0
X = X.select_dtypes(["number", "category"]).drop(columns=["body"])
print ('check types: ', type(X), '\n', X.head(3))
print ('check shapes: ', X.shape)
end_t = time.time()
print ('time taken: ', end_t-start_t)
使用parser='pandas'可以大大提高运行时和内存消耗。可以使用psutil库轻松检查内存消耗情况,如下所示:
print(psutil.cpu_percent())
部分依赖图:分类特征
部分依赖图以前也存在,但仅适用于数值特征,现在已扩展到分类特征。
如Sklearn文档所述:
部分依赖图显示了目标和一组感兴趣的输入特征之间的依赖关系,通过边缘化所有其他输入特征(“补集”特征)的值。从直观上讲,我们可以将部分依赖解释为感兴趣的输入特征的函数的预期目标响应。
使用上面的“titanic”数据集,我们可以轻松绘制分类特征的部分依赖性:
使用上面的代码块,我们可以得到以下部分依赖图:
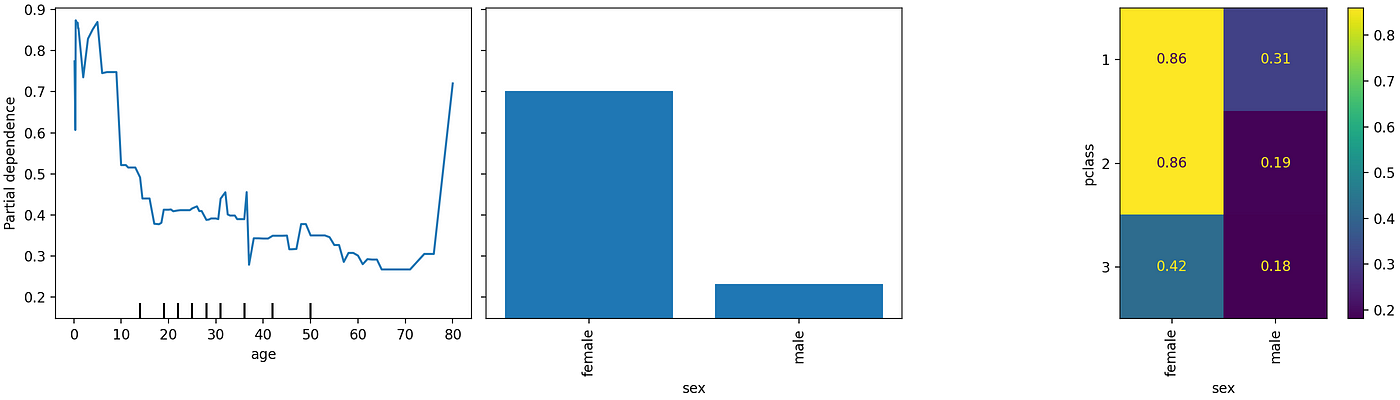
图2:分类变量的部分依赖图。(来源:作者的笔记本)
在0.24版本中,我们将获得针对分类变量的值错误:
>>> ValueError: could not convert string to float: ‘female’
直接绘制残差(回归模型):
对于分析分类模型的性能,在Sklearn度量API中,旧版本(0.24)中存在着像PrecisionRecallDisplay、RocCurveDisplay之类的绘图例程。在新的更新中,可以对回归模型执行类似操作。让我们看一个例子:
可以使用Sklearn直接绘制线性模型拟合及其对应的残差。(来源:作者的笔记本)
虽然始终可以使用matplotlib或seaborn绘制拟合线和残差,但是在我们确定了最佳模型之后,直接在Sklearn环境中快速检查结果非常有用。
新的Sklearn还有一些其他的改进和新增功能,但我发现这4个主要改进对于标准数据分析而言通常特别有用。
参考文献:
[1] Sklearn Release Highlights: V 1.2.0
[2] Sklearn Release Highlights: Video
[3] 所有的绘图和代码:我的GitHub
译自:https://towardsdatascience.com/new-scikit-learn-is-more-suitable-for-data-analysis-8ca418e7bf1c


评论(0)