
机器学习 | Python | 数据科学

图片来自 Unsplash,摄影师 Alina Grubnyak
任何数据科学家或机器学习专业人员最关键的技能之一,就是从给定的数据集中提取更深入、更有意义的特征。这个概念,更常被称为特征工程,可能是在建模机器学习算法时掌握的最强大的技术之一。
从数据中学习需要很多工程。尽管现代高级工具(如sklearn)已经将大多数复杂性抽象化了,但仍然需要完全理解数据,并将其塑造成你想要解决的问题。
提取更好的特征有助于为模型提供更多(可能更强)的关于业务领域及其影响因素的基础关系。
不用说,特征工程非常耗时和繁琐。它需要很多创造力、技术专长,还需要在大多数情况下进行尝试和错误。
最近,我发现了一个新的工具,Upgini。Upgini符合大语言模型(LLM)的当前趋势,利用OpenAI的GPT LLM的强大能力,自动化了我们数据集的整个特征工程过程。
在本文中,我们将介绍Upgini包并讨论其功能。
为了本文的目的,我们将使用亚马逊美食评论数据集(根据CC0:公共领域许可)。
有关Upgini包的更多信息,你可以访问其GitHub页面:
GitHub - upgini/upgini: Data search library for Machine Learning → Easily find and add relevant…
开始使用Upgini
首先,我们可以直接通过pip安装Upgini:
pip install upgini
我们还要加载我们的数据集:
import pandas as pd
import numpy as np
# read full data
df_full = pd.read_csv("/content/Reviews.csv")
# convert Time to datetime column
df_full['Time'] = pd.to_datetime(df_full['Time'], unit='s')
# re-order columns
0df_full = df_full[['Time', 'ProfileName', 'Summary', 'Text', 'HelpfulnessNumerator', 'HelpfulnessDenominator', 'Score' ]]

结果数据片段 — 图片来自作者
我们还要筛选我们的数据集,只包括在2011年1月1日之后发布并具有超过10个有用性的评论。
df_full = df_full[(df_full['HelpfulnessDenominator'] > 10) &
(df_full['Time'] >= '2011-01-01')]
我们还将Helpfulness转换为二进制变量,比率为0.50。
df_full.loc[:, 'Helpful'] = np.where(df_full.loc[:, 'HelpfulnessNumerator'] / df_full.loc[:, 'HelpfulnessDenominator'] > 0.50, 1, 0)
最后,我们创建一个新列——combined——将摘要和文本连接成一个单独的列。我们还利用这个机会删除任何重复项。
df_full["combined"] = f"Title: {df_full['Summary'].str.strip()} ; Content: {df_full['Text'].str.strip()}"
df_full.drop(['Summary', 'Text', 'HelpfulnessNumerator', 'HelpfulnessDenominator' ], axis=1, inplace=True)
df_full.drop_duplicates(subset=['combined'], inplace=True)
df_full.reset_index(drop=True, inplace=True)
使用Upgini进行特征搜索和增强
我们现在已经准备好开始搜索新特征了。
根据Upgini文档,我们可以使用FeaturesEnricher对象开始特征搜索。在FeaturesEnricher中,我们可以指定一个SearchKey(即我们要搜索的列)。
我们可以搜索以下列类型:
- hem
- IP
- phone
- date
- datetime
- country
- post code
让我们将它们导入Python。
from upgini import FeaturesEnricher, SearchKey
我们现在可以开始特征搜索了。
enricher = FeaturesEnricher(search_keys={'Time': SearchKey.DATE})
enricher.fit(df_full[['Time', 'ProfileName', 'Score', 'combined']], df_full['Helpful'])
经过一段时间后,Upgini向我们展示了一系列搜索结果——可能与我们的数据集相关的特征,以增强我们的数据集。
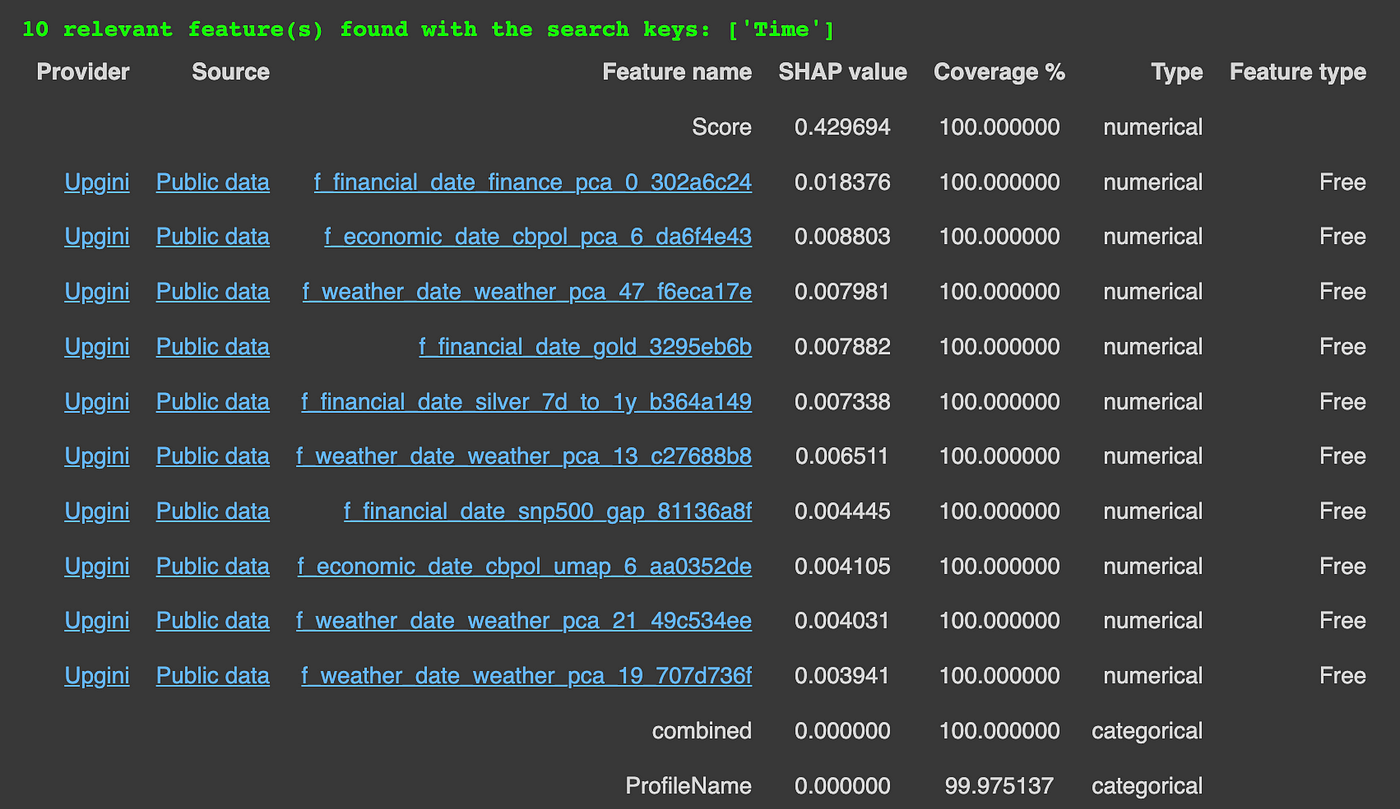
找到的特征片段。图片来自作者
看起来Upgini计算了每个找到的特征的SHAP值,以衡量该特征对数据和模型质量的整体影响。
对于每个返回的特征,我们还可以看到并直接访问其来源。
该软件包还评估了原始和丰富数据集上模型的性能。
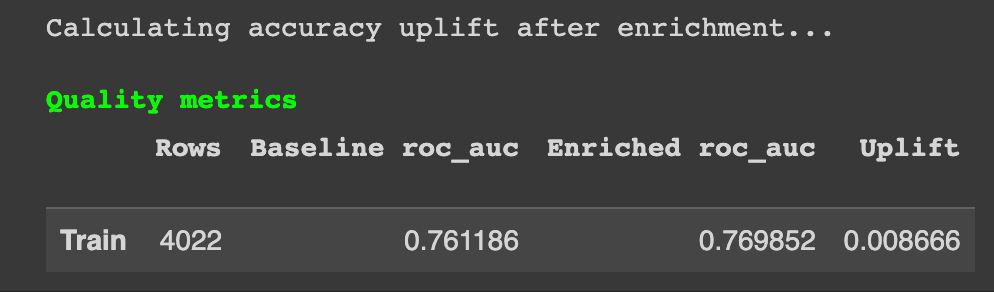
丰富后获得的结果。图片来自作者
在这里,我们可以看到通过添加丰富的特征,我们设法稍微提高了模型的性能。不可否认,这种性能提升微不足道。
使用GPT模型生成特征
深入研究文档后,似乎FeaturesEnricher还接受另一个参数——generate_features。
generate_features允许我们搜索并生成文本列的特征嵌入。这听起来非常有前途。我们确实有文本列——combined和ProfileName。
Upgini连接了两个LLM与搜索引擎——来自Upgini文档的GPT-3.5和GPT-J。
我们来运行一下这个丰富操作,好吗?
enricher = FeaturesEnricher(
search_keys={'Time': SearchKey.DATE},
generate_features=['combined', 'ProfileName']
)
enricher.fit(df_full[['Time','ProfileName','Score','combined']], df_full['Helpful'])
Upgini为我们找到了222个相关特征。同样,每个特征我们都会得到一个关于它们的SHAP值、来源和其在我们数据上的覆盖率的报告。
这次,我们还可以注意到我们有一些生成的特征(即文本GPT嵌入特征)。
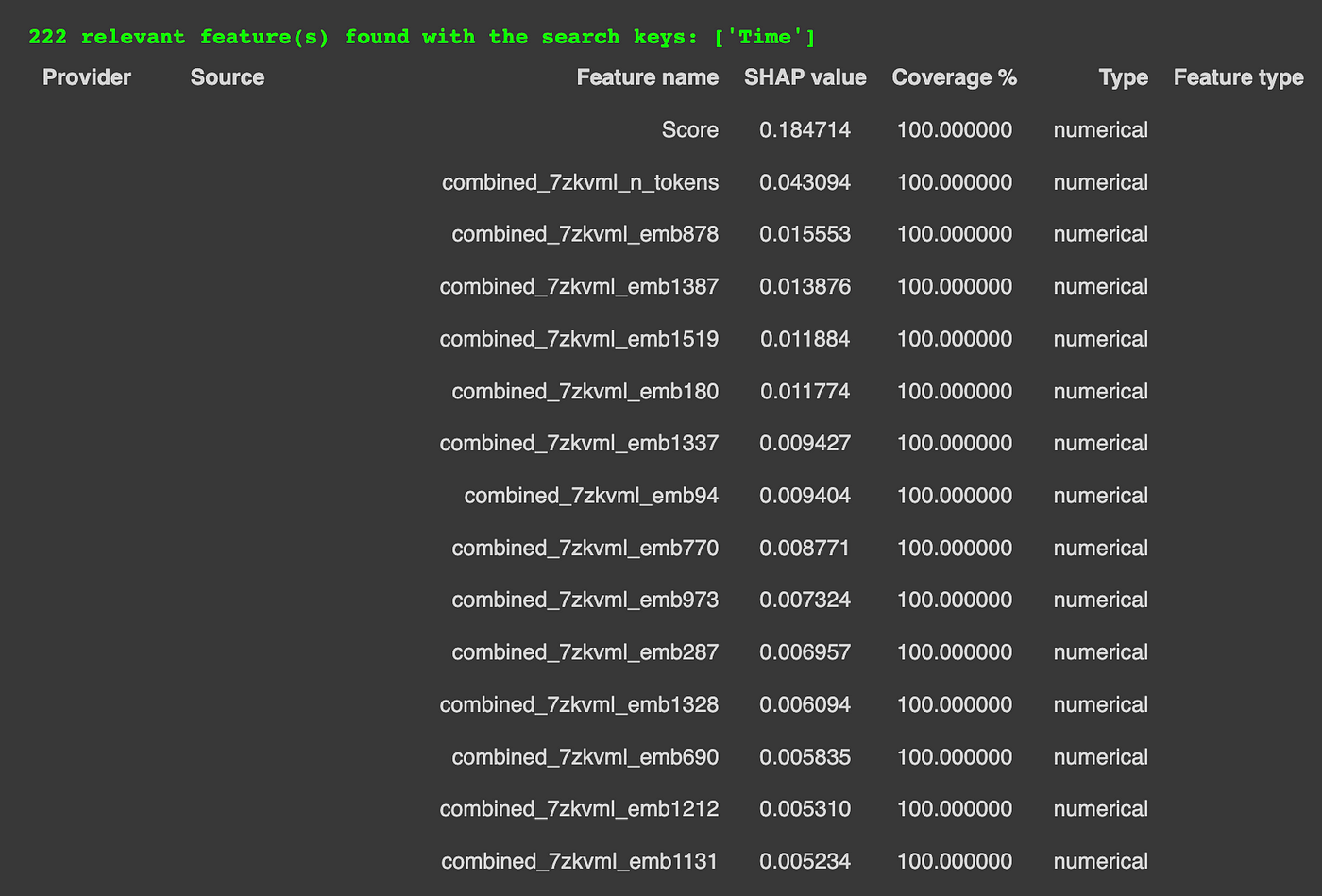
生成的文本嵌入特征示例。图片来自作者
评估性能如何?
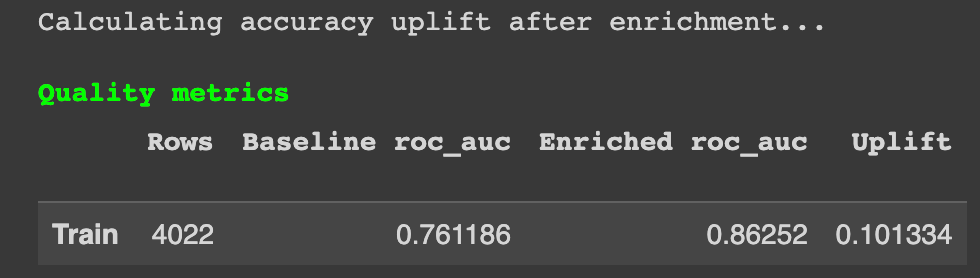
评估指标。图片来自作者。
通过新生成的特征,我们看到了巨大的预测性能提升——提升了0.1。最好的部分是,所有这些都是完全自动化的!
考虑到我们观察到的巨大性能提升,我们绝对想保留这些特征。我们可以按如下方式操作:
df_full_enrich = enricher.transform(df_full)
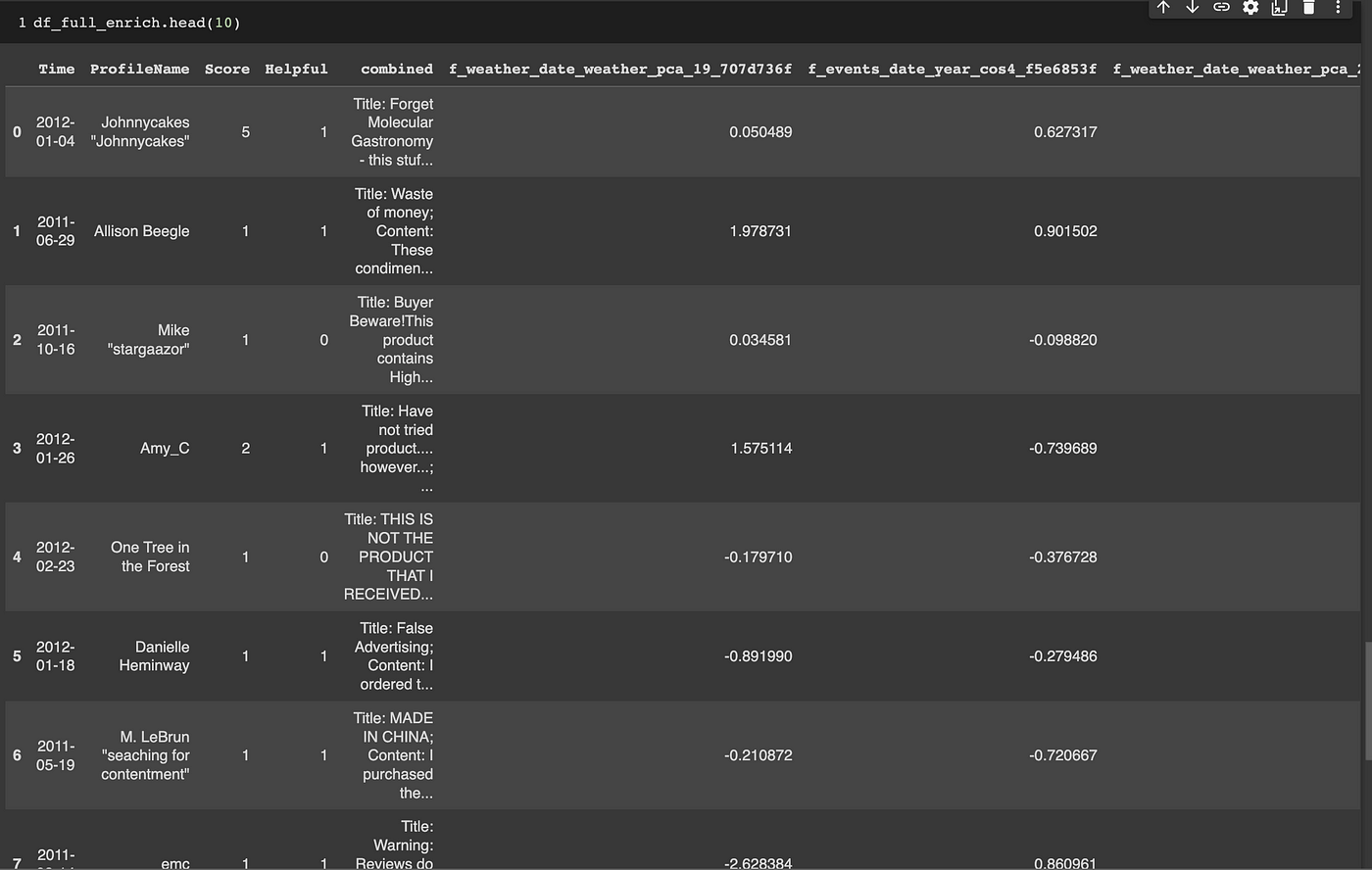
生成的数据集。图片由作者提供。
结果是一个由11个特征组成的数据集。从这一点开始,我们可以像处理其他任何机器学习任务一样进行处理。
总结
Upgini提供了很多潜力。我仍在尝试它的功能并熟悉它的不同功能,但到目前为止,它被证明是非常有用的,特别是那个GPT功能生成器!
让我知道你的结果!
参考文献
Stanford Network Analysis Project在Kaggle上提供的Amazon Fine Food Reviews数据集-根据CC0:公共领域许可。
译自:https://towardsdatascience.com/automated-feature-engineering-in-python-5733426530bf




评论(0)