最新

一种使用机器学习进行分层时间序列预测的简单方法
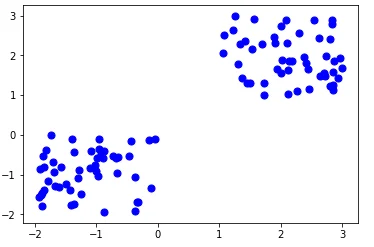
Kaggle 蓝图 分层时间序列预测(作者绘制的图像) 欢迎来到另一期的“Kaggle 蓝图”系列,我们将分析Kaggle竞赛中的获胜解决方案,以便我们可以将其应用到我们自己的数据科学项目中。 本期将回顾2020年6月底结束的“M5 Forecasting — Accuracy”竞赛中的技术和方法。 问题陈述:分层时间序列预测 “M5 Forecasting — Accuracy”竞赛的目

发布于 2023-5-24 下午4:33 阅读数 3750
Python中的自动特征工程
机器学习 | Python | 数据科学 图片来自 Unsplash,摄影师 Alina Grubnyak 任何数据科学家或机器学习专业人员最关键的技能之一,就是从给定的数据集中提取更深入、更有意义的特征。这个概念,更常被称为特征工程,可能是在建模机器学习算法时掌握的最强大的技术之一。 从数据中学习需要很多工程。尽管现代高级工具(如sklearn)已经将

发布于 2023-5-24 下午2:22 阅读数 2290
第53课——机器学习:时间序列异常检测(直觉)
异常检测的统计方法 在时间序列的异常检测中,统计方法通常是第一道防线。它们可以利用历史数据建立“正常”行为,然后将任何偏离此行为的情况标记为潜在的异常。技术可能包括移动平均值、标准差或更复杂的模型,如ARIMA。 直觉: 想象一条有速度限制的道路。行驶速度显著快于或慢于平均速度的汽车可能被认为是“异常”。这类似于异常检

发布于 2023-5-24 上午11:13 阅读数 1541

15本完全免费的机器学习和深度学习书籍
互联网上有很多书籍和课程可以帮助你掌握Python和数据科学。之前我在这篇文章中列出了掌握Python的22个最佳资源。 掌握Python的22个最佳资源 然而,如果你正在寻找可以帮助你学习数据科学主题的细节和理论的书籍,那么之前的文章并没有涵盖这些内容。 因此,在本文中,我将尝试填补这个空白。幸运的是,有很多完全免费的电子书可以

发布于 2022-12-18 上午8:0 阅读数 2921
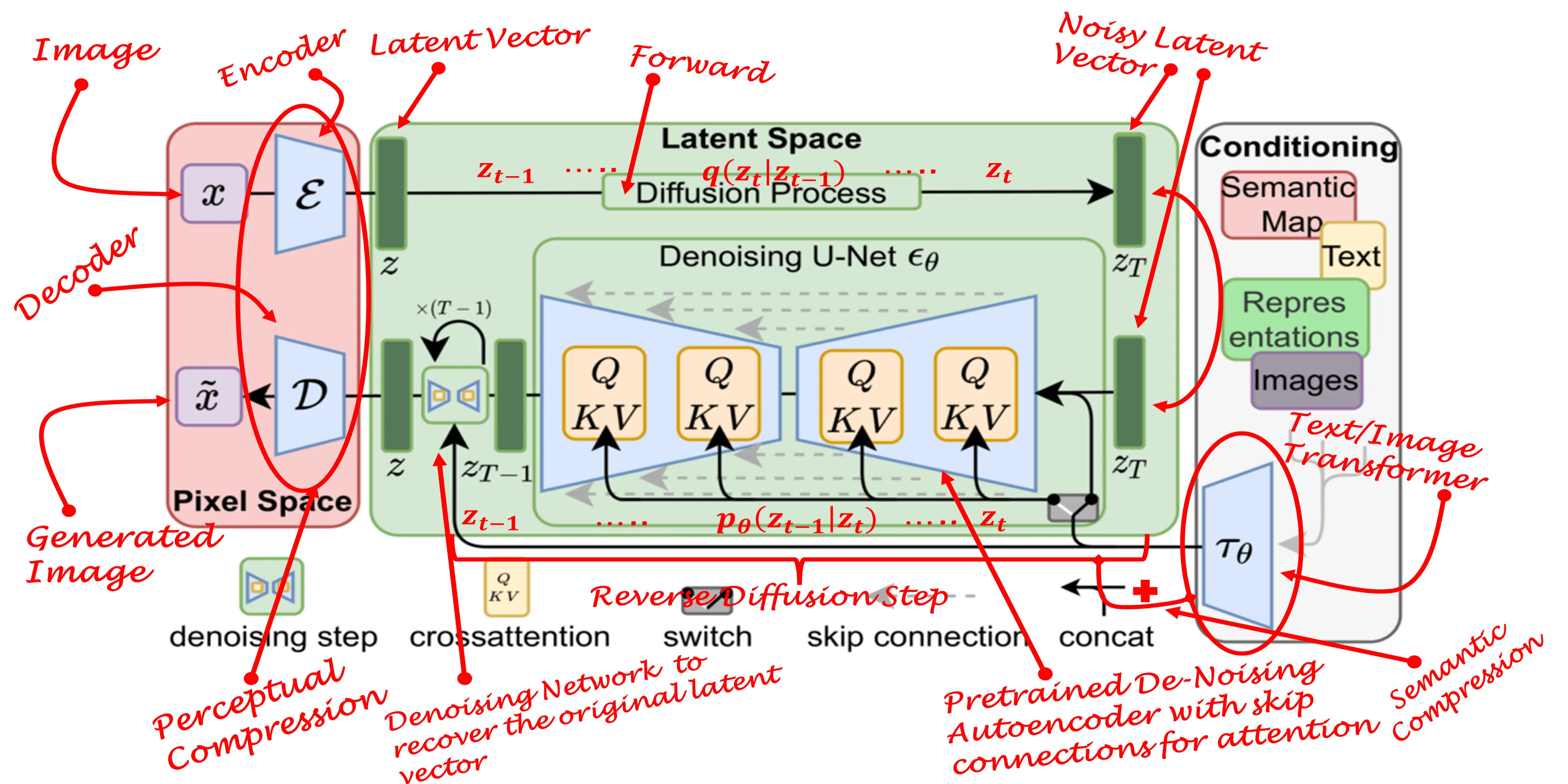
什么是稳定扩散模型,为什么它们是图像生成的一大进步?
本文将介绍图像生成领域的最新进展——潜在扩散模型(Latent Diffusion Models,LDM)及其应用。本文将基于生成对抗网络(GANs)、扩散模型和Transformer的概念。如果您想深入了解这些概念,请随时查看我之前关于这些主题的文章。 也许过去十年计算机视觉和机器学习领域的突破是GANs的发明——一种引入了超越数据现有内容的可能性的方法,
发布于 2022-9-20 上午8:0 阅读数 2165
稳定的扩散算法终于向公众发布了
稳定 AI 公布了其开源的人工智能文本到图像模型 Stable Diffusion 的公共发布。这是一件大事。该公司的首席执行官和创始人 Emad Mostaque 昨天在 Twitter 上公开发表了一份声明。 “我为每个参与发布这一技术的人感到骄傲,这是一系列模型中的第一个,旨在激发人类的创造潜力,”他说。 为什么你应该关注这个? 它是开源的。这意味着你

发布于 2022-8-25 上午8:0 阅读数 1992
博士生机器学习第一年推荐的前五本书(意外之选)
如果你想进入迷人的学术世界,最主要的途径是攻读博士学位。然而,这是一条非常艰难的道路,尤其是因为相对于其他工作而言所经历的孤独和开始撰写高质量机器学习论文所需的知识量。 但是,如果你认为这两个问题不是问题,因为你热爱学习(特别是机器学习),并且你不介意孤独,那么你可能是攻读博士学位的完美候选人! 既然你已经决定了

发布于 2022-8-20 上午8:0 阅读数 1502
“前 20 个机器学习算法,每个算法不到 10 秒钟的简单解释”
20个最重要的机器学习算法的简单解释,每个算法不超过10秒钟。 来自 Pexels 的 Mike B 机器学习是一种数据分析方法,可以自动化模型开发过程。它是基于系统能够从数据中学习、识别模式并进行最小用户干预的决策的人工智能分支 [2]。 机器学习算法被广泛应用于各种应用程序中,包括电子邮件过滤、检测欺诈性信用卡交易、股票交易、计算

发布于 2022-8-2 上午8:0 阅读数 1543
2022年机器学习的五大趋势
照片由 Markus 提供的 Unsplash 机器学习领域相对较新,但它正在以快速的速度发展,对机器学习和人工智能技术的需求似乎日益增长。作为机器学习工程师,我们必须寻求更有效和更有效的方式来准备数据和构建模型。 无论您是机器学习的专家还是新手,都必须对该领域的最新发展保持开放的态度。以下是一些最新的机器学习技术。所有这些

发布于 2022-7-27 上午8:0 阅读数 2096
任何学习数据科学的人都应该了解的6种机器学习算法
机器学习是数据科学学习者应该掌握的领域之一。如果你是数据科学新手,你可能听过“算法”或“模型”这些词,但不知道它们与机器学习有什么关系。 机器学习算法被分类为监督学习或非监督学习。 监督学习算法对标记的输入和输出数据(也称为目标)之间的关系进行建模。然后使用这个模型来预测使用新标记的输入数据的标签的新观察结果。如

发布于 2022-6-15 上午8:0 阅读数 1852
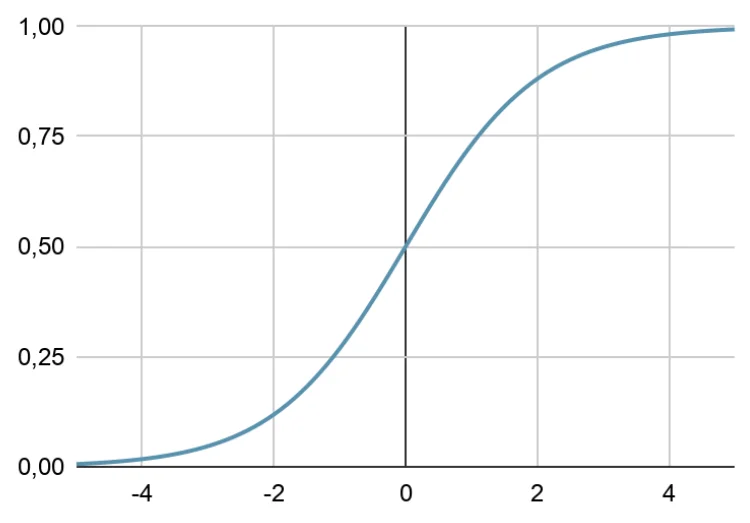
哪些模型需要归一化的数据?
数据预处理是每个机器学习项目的重要组成部分。对数据进行归一化是一种非常有用的转换。一些模型要求进行归一化以正常工作。让我们来看看一些这样的模型。 什么是归一化? 归一化是与变量缩放相关的通用术语。缩放将一组变量转换为一组新变量,这些变量具有相同的数量级。通常是线性变换,因此不会影响特征的相关性或预测能力。 为什
发布于 2022-6-13 上午8:0 阅读数 1611
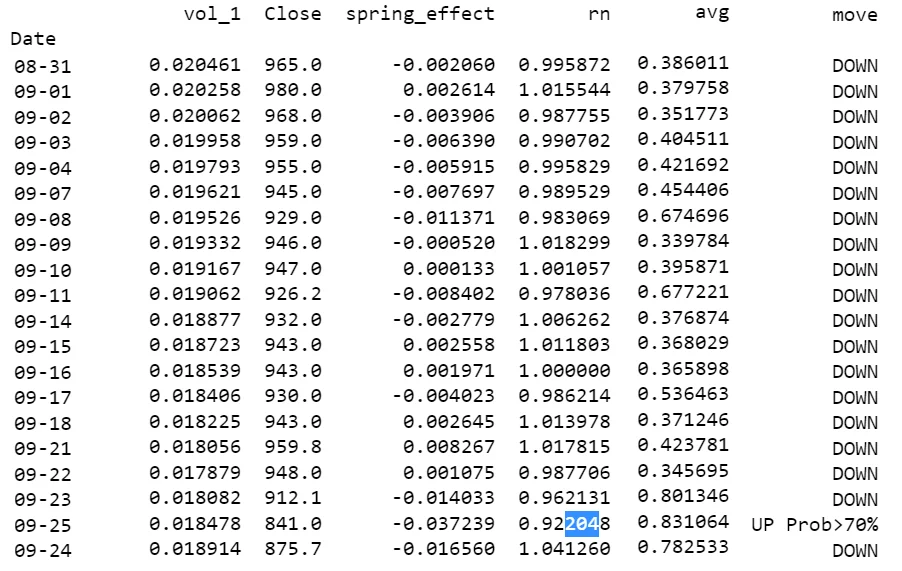
有效利用机器学习进行股票交易
在我上一篇文章的结尾,我提到了我渴望通过机器学习的眼镜“看到”股票市场。更具体地说,我想找到一种方法,通过历史数据学习,预测未来的演变。通过阅读几乎所有关于机器学习和金融市场交叉点的可用公共文章,我偶然发现了洛佩兹·德·普拉多的书《金融机器学习进展》。我对作者的科学正统感到印象深刻,这肯定有助于缩短我的学习曲线。然
发布于 2022-6-8 上午8:0 阅读数 1585

随机森林回归
几周前,我写了一篇文章演示了随机森林分类模型。在本文中,我们将演示使用sklearn的RandomForrestRegressor()模型的随机森林回归案例。 与上一篇文章类似,我将从突出一些定义和术语开始,这些术语涉及和组成随机森林机器学习的主干。本文的目标是描述随机森林模型,并演示如何使用sklearn包应用它。我们的目标不是解决最优解,而是

发布于 2022-3-3 上午8:0 阅读数 2016
在生产环境中部署机器学习模型的三种方法
部署机器学习模型到生产环境 处理数据是一回事,但是将机器学习模型部署到生产环境则是另一回事。 数据工程师一直在寻找新的方式来部署他们的机器学习模型到生产环境中。他们想要最佳性能,同时也关心成本。 现在,你可以同时兼得! 让我们来看看部署过程,并了解如何成功地进行部署! 为 Python API 和 ML 模型创建 Web UI 如何在生

发布于 2021-11-9 上午8:0 阅读数 2349
2021年你应该了解的11种降维技术
在统计学和机器学习中,数据集中属性、特征或输入变量的数量被称为其维度。例如,我们来看一个非常简单的数据集,包含2个属性,分别为_身高_和_体重_。这是一个2维数据集,该数据集的任何观察结果都可以在2D图中绘制。 如果我们在同一数据集中添加另一个维度,比如_年龄_,它就变成了一个3维数据集,其中任何观察结果都位于3维空间中。

发布于 2021-4-14 上午8:0 阅读数 2983

Java中的机器学习
图片来自 Mike Kenneally 在 Unsplash 机器学习(ML)在学术界和工业界的不同领域带来了重大的改变。ML日益增长的参与度,应用于诸如图像、语音识别、模式识别、优化、自然语言处理、推荐等广泛的应用中。 编程让计算机从经验中学习,最终应该可以消除大部分详细的编程工作。——Arthur Samuel 1959。 机器学习可分为四种主要技术:回归、分

发布于 2020-10-13 上午8:0 阅读数 1714
7种处理机器学习中缺失值的方法
Photo by Kevin Ku on Unsplash 现实世界的数据通常存在许多缺失值。导致缺失值的原因可能是数据损坏或未能记录数据。在数据集的预处理过程中,处理缺失数据非常重要,因为许多机器学习算法不支持缺失值。 本文介绍了处理数据集中缺失值的七种方法: 删除具有缺失值的行 为连续变量填补缺失值 为分类变量填补缺失值 其他插补方法

发布于 2020-7-24 上午8:0 阅读数 4066
您的多类别机器学习模型的混淆矩阵
混淆矩阵是一种表格化的方式,用于可视化预测模型的性能。混淆矩阵中的每个条目表示模型分类正确或错误的类别预测次数。 已经熟悉混淆矩阵的人都知道,它通常是针对二元分类问题进行解释的。但是,这篇文章不是针对二元分类的解释。今天,我们将看看混淆矩阵在多类机器学习模型上的工作原理。但是,我们将从二元分类开始,以便更好地了

发布于 2020-5-29 上午8:0 阅读数 2423