
数据预处理是每个机器学习项目的重要组成部分。对数据进行归一化是一种非常有用的转换。一些模型要求进行归一化以正常工作。让我们来看看一些这样的模型。
什么是归一化?
归一化是与变量缩放相关的通用术语。缩放将一组变量转换为一组新变量,这些变量具有相同的数量级。通常是线性变换,因此不会影响特征的相关性或预测能力。
为什么需要对数据进行归一化?因为一些模型对特征的数量级敏感。例如,如果一个特征的数量级等于1000,而另一个特征的数量级等于10,一些模型可能会“认为”第一个特征比第二个特征更重要。这显然是一种偏见,因为数量级不提供有关预测能力的任何信息。因此,我们需要通过将变量转换为具有相同数量级来消除这种偏见。这就是缩放转换的作用。
这样的转换可以是归一化(将每个变量转换为0-1区间)和标准化(将每个变量转换为0均值和单位方差变量)。我在另一篇文章中详细讨论了这些转换。根据我的经验,标准化效果更好,因为如果存在异常值,归一化会缩小变量的概率分布。因此,我将在整篇文章中谈论标准化。
需要归一化的模型
让我们看看一些需要在训练之前进行缩放的模型。对于以下示例,我将使用Python代码和scikit-learn的Pipeline对象,在应用模型之前执行一系列转换,并返回可以像模型本身一样调用的对象。
我要使用的缩放函数是标准化,由_StandardScaler_对象执行。
线性模型
除线性回归外,所有线性模型都需要归一化。Lasso、Ridge和Elastic Net回归是强大的模型,但它们需要归一化,因为惩罚系数对所有变量都是相同的。
lasso = make_pipeline(StandardScaler(), Lasso()) ridge = make_pipeline(StandardScaler(), Ridge()) en = make_pipeline(StandardScaler(), ElasticNet())
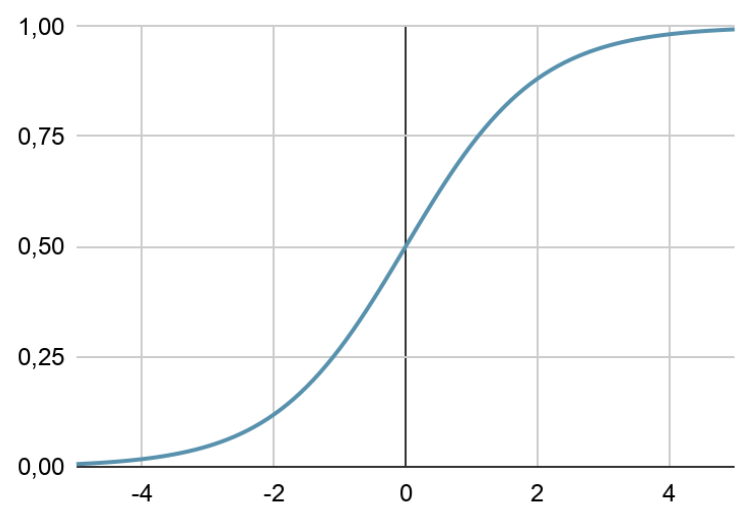
逻辑回归也需要归一化,以避免在训练阶段出现梯度消失问题。

逻辑回归。作者的图片
logistic = make_pipeline(StandardScaler(), LogisticRegression())
如果你没有进行先前的归一化训练线性回归,你不能使用系数作为特征重要性的指标。如果你需要执行特征重要性(例如,为了降维),则必须提前归一化数据集,即使你使用简单的线性回归。
lr = make_pipeline(StandardScaler(), LinearRegression())
支持向量机
支持向量机是基于距离的强大模型。它们尝试在特征向量空间中找到一个超平面,该超平面能够根据目标变量的值将训练记录进行线性分离。

SVM示例。作者的图片
通过一些改变,SVM甚至可以用于非线性函数和回归目的。
由于距离非常敏感于特征的数量级,因此对于SVM也需要应用缩放转换。
svm_c = make_pipeline(StandardScaler(), LinearSVC()) # For classification svm_r = make_pipeline(StandardScaler(), LinearSVR()) # For regression
k-近邻
KNN是一种非常流行的基于距离(通常是欧几里得距离)的算法。预测考虑了空间中给定点的k个最近邻居。

k-近邻。作者的图片
就像SVM一样,甚至KNN也需要使用归一化数据。
knn_c = make_pipeline(StandardScaler(), KNeighborsClassifier()) # For classification knn_r = make_pipeline(StandardScaler(), KNeighborsRegressor()) # For regression
神经网络
最后,神经网络对特征的数量级非常敏感。激活函数总是需要归一化的数据,否则训练阶段将遭受梯度消失问题,就像逻辑回归一样。

神经网络。作者的图片
nn_c = make_pipeline(StandardScaler(), MLPClassifier()) # For classification nn_r = make_pipeline(StandardScaler(), MLPRegressor()) # For regression
结论
缩放是一种非常重要的预处理转换,可以极大地影响训练阶段。如果没有正确执行,模型的结果肯定是不可靠的。这就是为什么在模型要求时使用适当的归一化技术非常重要。
如果你对本文中提到的模型感兴趣,我在我的Python监督学习在线课程中对它们进行了广泛讨论。
本文最初发表于 https://www.yourdatateacher.com,发布于2022年6月12日。
译自:https://towardsdatascience.com/which-models-require-normalized-data-d85ca3c85388



评论(0)