
Kaggle 蓝图

分层时间序列预测(作者绘制的图像)
欢迎来到另一期的“Kaggle 蓝图”系列,我们将分析Kaggle竞赛中的获胜解决方案,以便我们可以将其应用到我们自己的数据科学项目中。
本期将回顾2020年6月底结束的“M5 Forecasting — Accuracy”竞赛中的技术和方法。
问题陈述:分层时间序列预测
“M5 Forecasting — Accuracy”竞赛的目标是预测42,840个分层销售数据时间序列的未来28天。
分层时间序列——与常见的多元时间序列问题不同,分层时间序列可以按不同的级别进行聚合:例如,按商品级别、店铺级别和州级别。在本次比赛中,竞争者们获得了来自3个不同类别的3,000种单品在3个州的10家商店中超过40,000个时间序列。
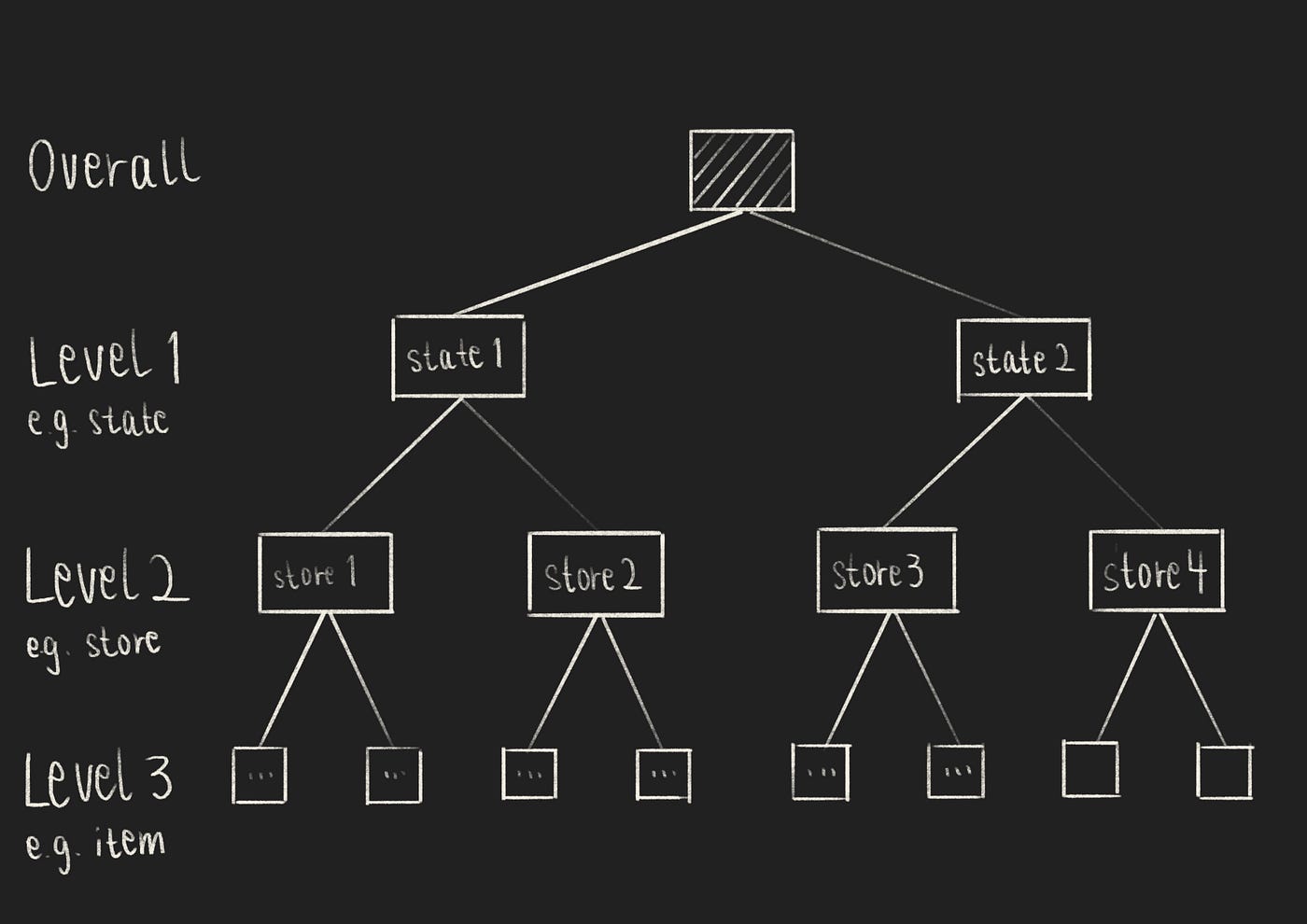
分层时间序列(作者的图像)
周期性——销售数据通常是循环的,这意味着销售数据是与时间相关的。例如,你将看到重复的模式,例如在一周结束时销售增加(每周循环)、在月初销售增加(每月循环)或在假期期间销售增加(每年循环)。
多步骤——任务是预测未来28天(28个步骤)的销售数据。
在本文中,为了更好地理解,你的数据集应该看起来像这样:
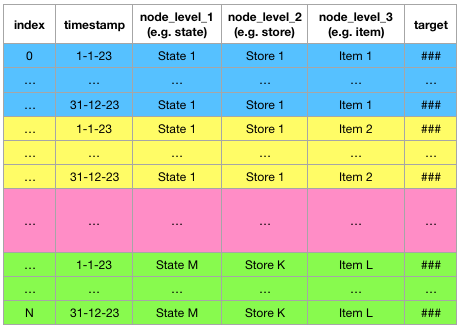
在此插入你的数据:你的分层时间序列数据应该是这样格式化的(作者的图像)
使用机器学习将时间序列预测视为回归问题的方法
竞赛者们中流行的方法之一是将时间序列预测问题视为回归问题,并使用机器学习(ML)进行建模[6]。
- 可以通过将预测拆分为单个步骤(在数据点之间保持历史数据和预测之间的间隔恒定)来将时间序列预测问题转化为回归问题。
- 与其将过去的值序列馈送到ML模型中,不如将历史数据点聚合到历史特征中。
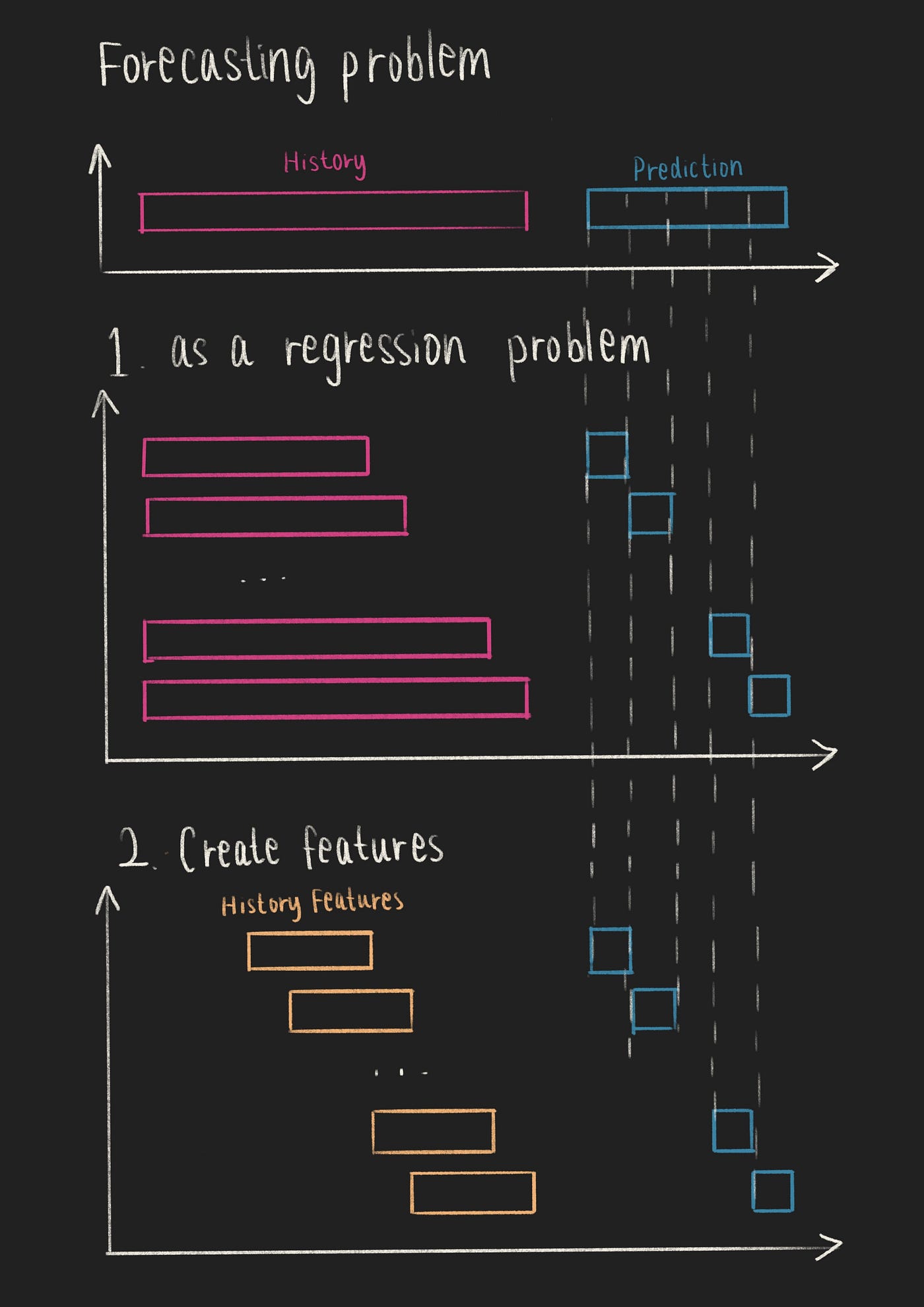
时间序列预测作为回归问题(作者的图像)
因此,使用ML解决分层时间序列预测问题的主要步骤如下:
步骤1:构建简单的基线
与任何良好的机器学习问题一样,我们将从构建一个简单的基线开始。对于时间序列预测问题,一个好的起点是将最后一个时间戳的值作为预测值——天真的方法。
如果你的时间序列是循环的,你可以通过参考上一个周期来改进天真的方法。例如,如果你的时间序列取决于周几,你可以取上个月,按周几分组,并取平均值[2]。
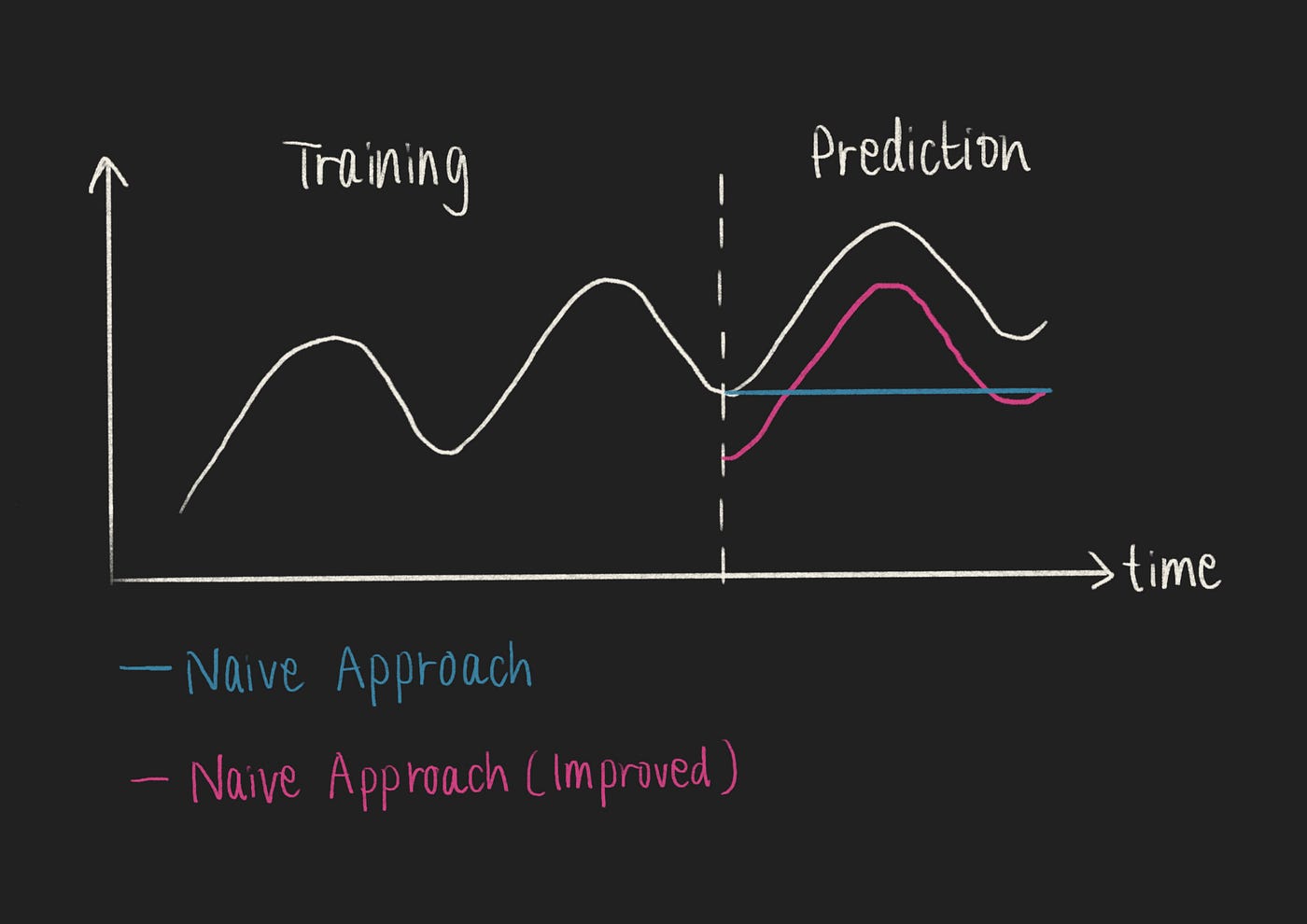
时间序列预测的基线:天真的方法(作者的图像)
步骤2:从历史数据中进行特征工程
与使用传统统计方法不同,当开发ML模型时,特征工程是一个重要的步骤。因此,与其直接将历史数据馈送到ML模型中,不如将历史数据聚合成历史特征[4]。
时间戳特征
时间序列至少有两个特征:时间戳和值。仅有时间戳就可以创建多个新特征。
首先,你可以通过将时间戳分解为其组成部分(例如,天、周、月、年等)来从时间戳中提取特征[4]。
# Convert to DateTime
df['date'] = pd.to_datetime(df['date'])
# Make some features from date
df['day'] = df['date'].dt.day
df['week'] = df['date'].dt.week
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
# etc.
其次,你可以基于日期创建新特征[1, 3]:这是工作日还是周末?这是假期吗?是否发生了特殊事件(例如,体育赛事)?
聚合特征
接下来,你可以通过聚合历史数据并创建统计特征(例如,最大值、最小值、标准差和平均值)来创建新特征[1、3、4、8、10]。
因为我们正在处理分层时间序列,所以我们将按不同的LEVEL(例如,store_id)对时间序列进行分组。## 滞后特征
对于时间序列数据的常见特征工程技术是创建滞后特征[4,5,10]。为了在测试数据上使用这个特征,滞后时间应该大于训练和测试数据之间的时间差。
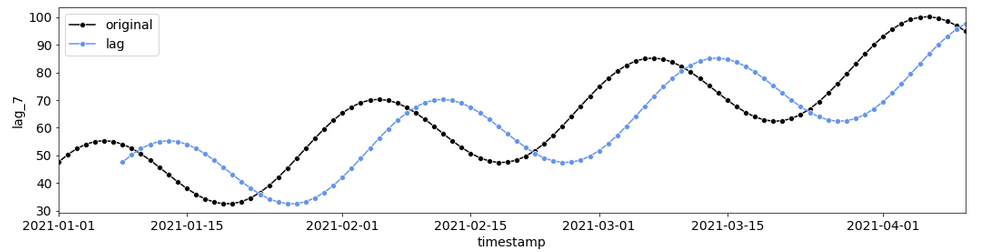
7天的滞后时间(作者提供的图像)
LEVEL = 'store_id'
TARGET = 'sales'
lag = 7
df[f"lag_{lag}"] = df.groupby(LEVEL)[TARGET].shift(lag).fillna(0)
滚动特征
另一个用于时间序列数据的常见特征工程技术是基于滚动窗口(例如平均值或标准差)创建特征[1,3,10]。
你可以将这个特征工程技术直接应用于FEATURE,甚至可以应用于它的滞后版本。
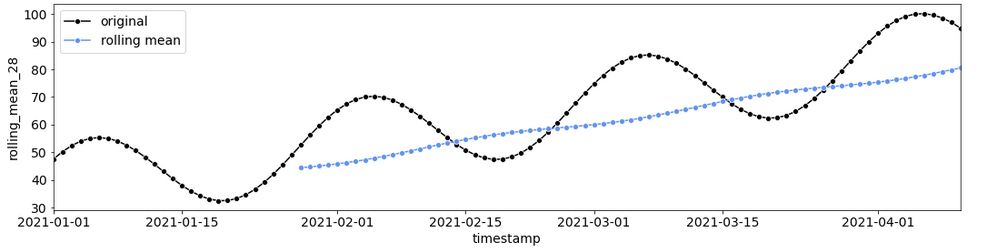
28天滚动窗口的平均值(作者提供的图像)
window = 28
df[f"rolling_mean_{window}"] = df.groupby(LEVEL)[FEATURE].transform(lambda x : x.rolling(window).mean()).fillna(0)
层次结构作为分类特征
在处理分层时间序列数据时,你还可以将不同层次的层次结构节点标识符(例如store_id,item_id)作为分类变量[1,3]包含进去。
在将其提供给ML模型之前,你的结果数据框应该像这样:
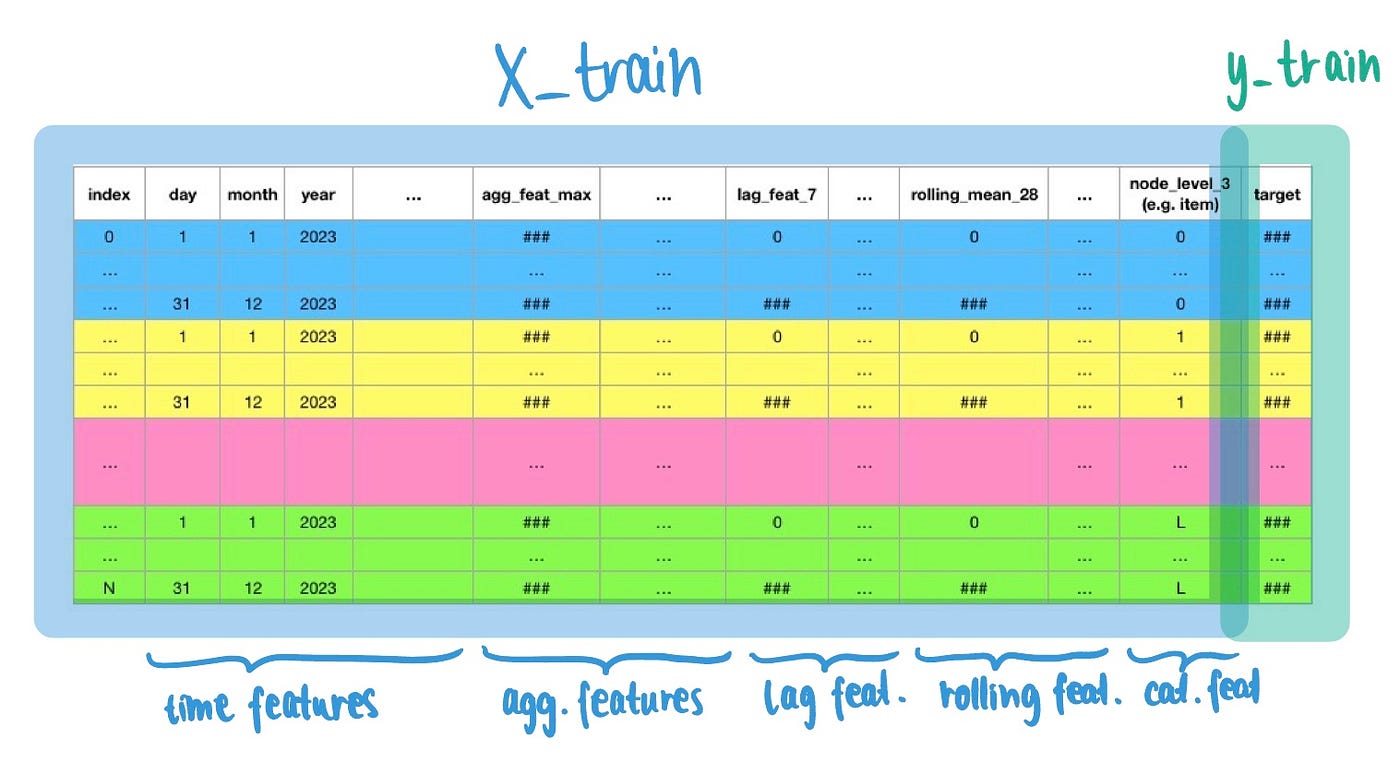
用于训练时间序列预测ML(GBDT)模型的训练数据结构(作者提供的图像)
第三步:使用机器学习建模和验证时间序列预测问题
在建模和验证常规ML问题(例如回归或分类)和具有ML的分层时间序列预测问题之间存在一些差异。
建模多元和分层时间序列
建模分层时间序列问题类似于建模多元问题。
建模多元时间序列-自回归和序列到序列模型通常只能一次建模一个时间序列(单变量时间序列问题)。因此,当遇到多元时间序列问题(如分层时间序列)时,你需要为每个时间序列构建多个预测模型-每个时间序列一个模型。
许多竞争对手使用了LightGBM,一种ML模型和梯度提升框架,进行建模[1,3,5,7,8,10]。使用LightGBM时,你可以使用单个LightGBM模型建模多个时间序列,而不是构建多个预测模型。
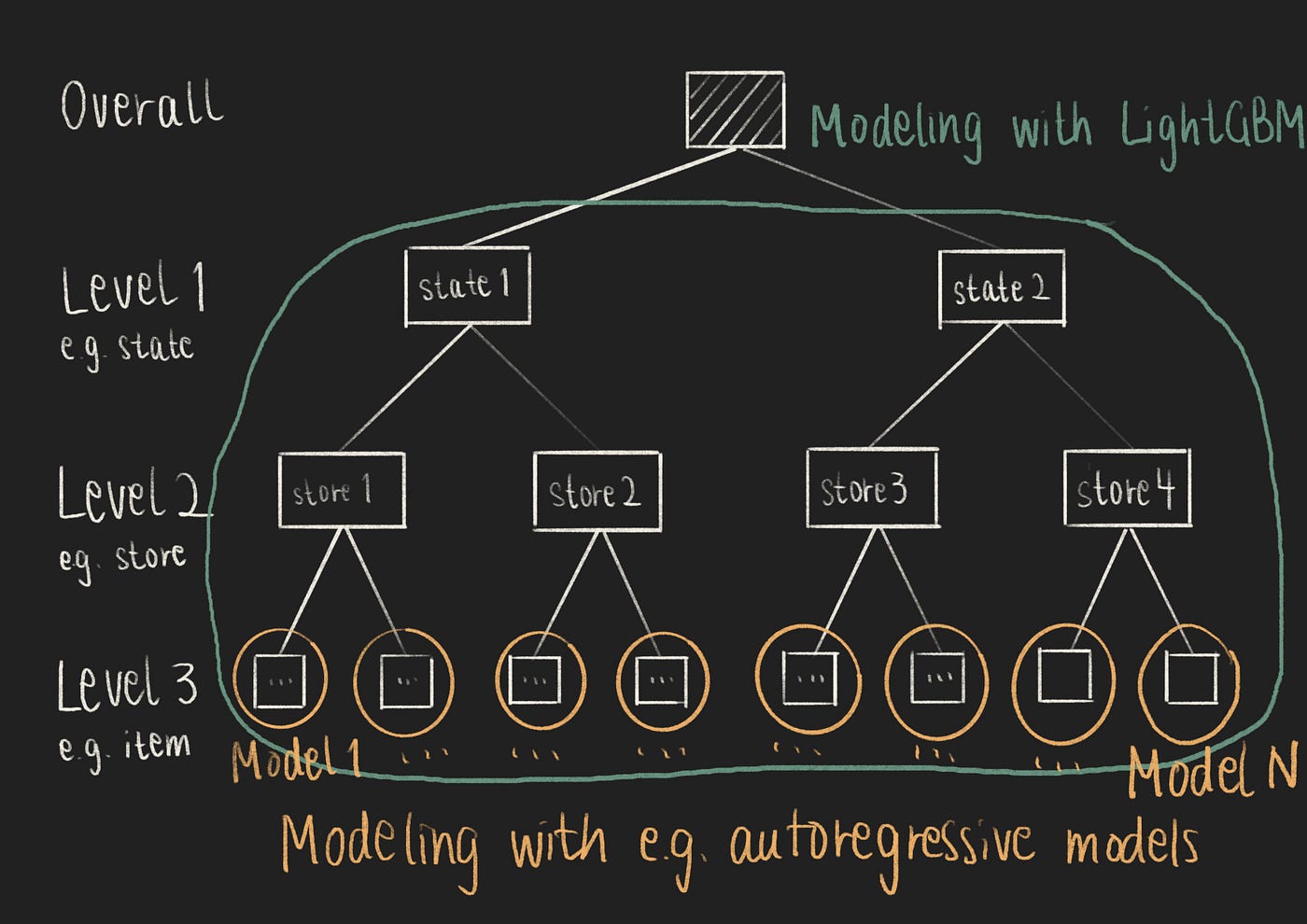
多元时间序列建模策略(作者提供的图像)
由于时间序列数据是分层的,许多竞争对手将相似的时间序列按层次水平(例如按店铺)分组并一起建模[3,8,10]。
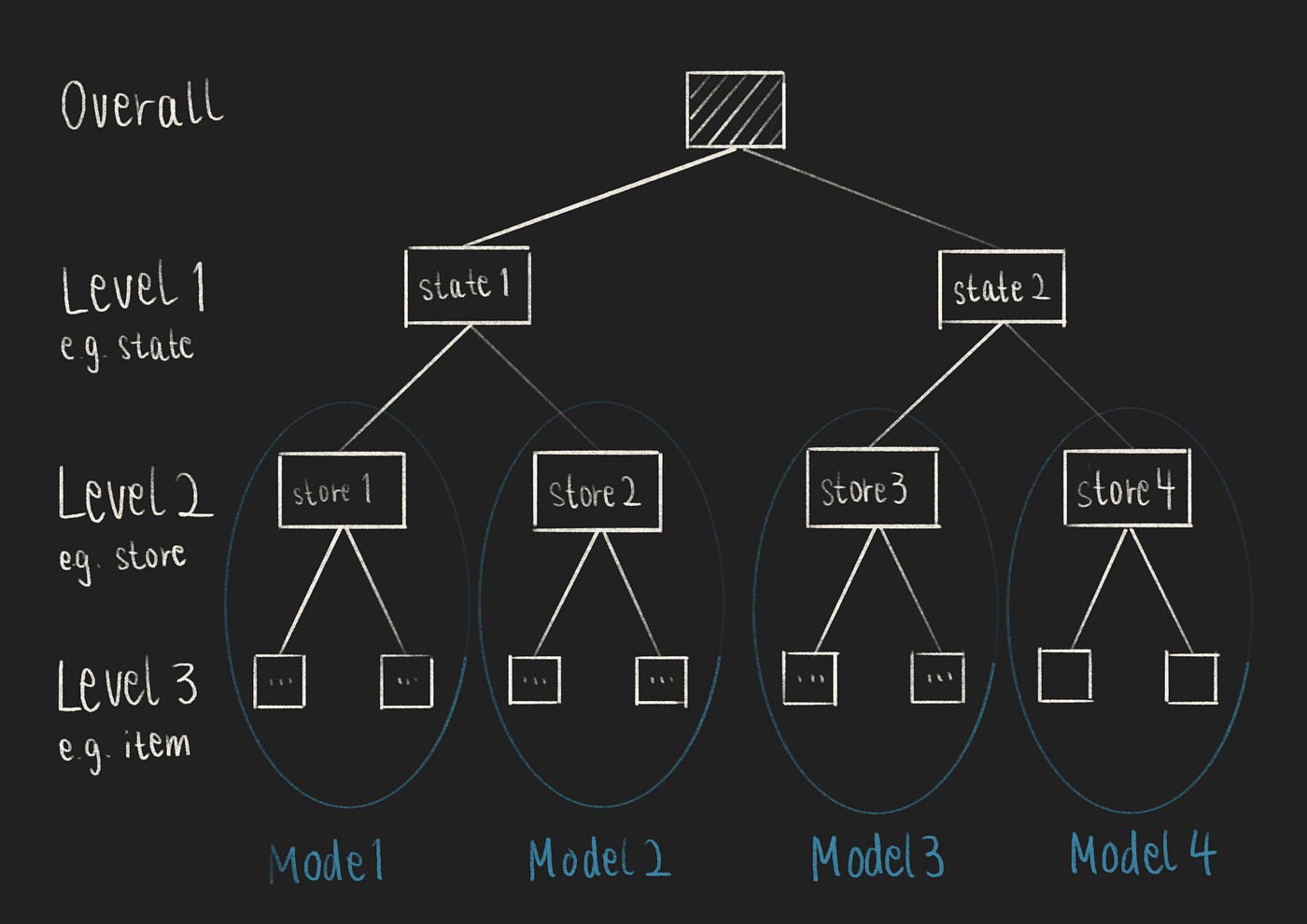
使用机器学习进行分层时间序列预测的建模策略(作者提供的图像)
验证预测模型
在验证时间序列预测模型时,必须牢记时间序列的时间顺序[6]。如果使用流行的KFold交叉验证策略,将使用未来数据来预测过去的事件。在进行预测时,必须避免泄漏未来信息以预测过去。
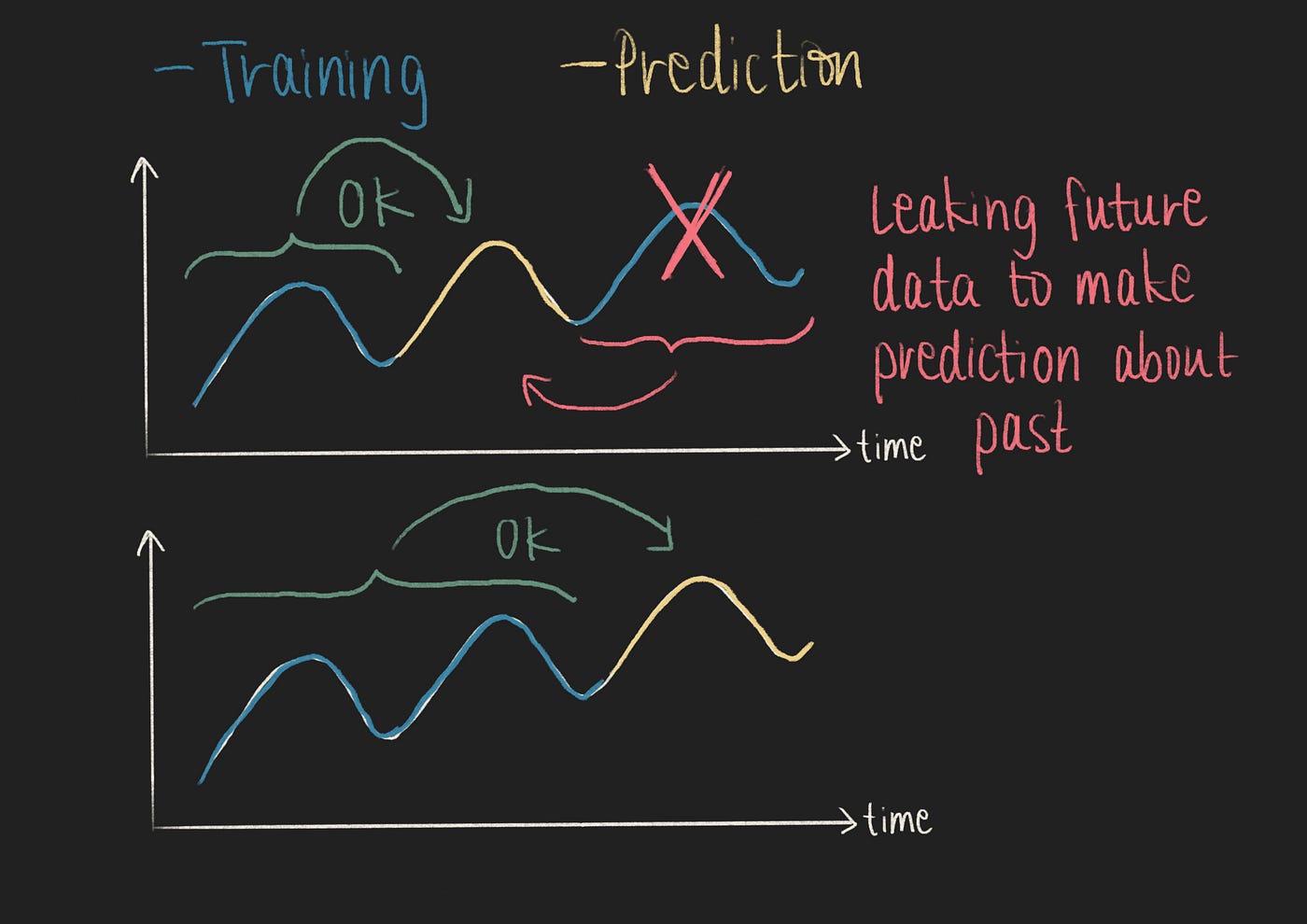
在时间序列预测验证中避免泄漏未来信息以预测过去(作者提供的图像)
相反,你应该定义一些交叉验证周期,然后使用该周期之前的所有数据来训练模型[3,8,10]。例如,对于最近一个月(N_FOLDS = 4)的每周(VALIDATION_PERIOD = 7)。
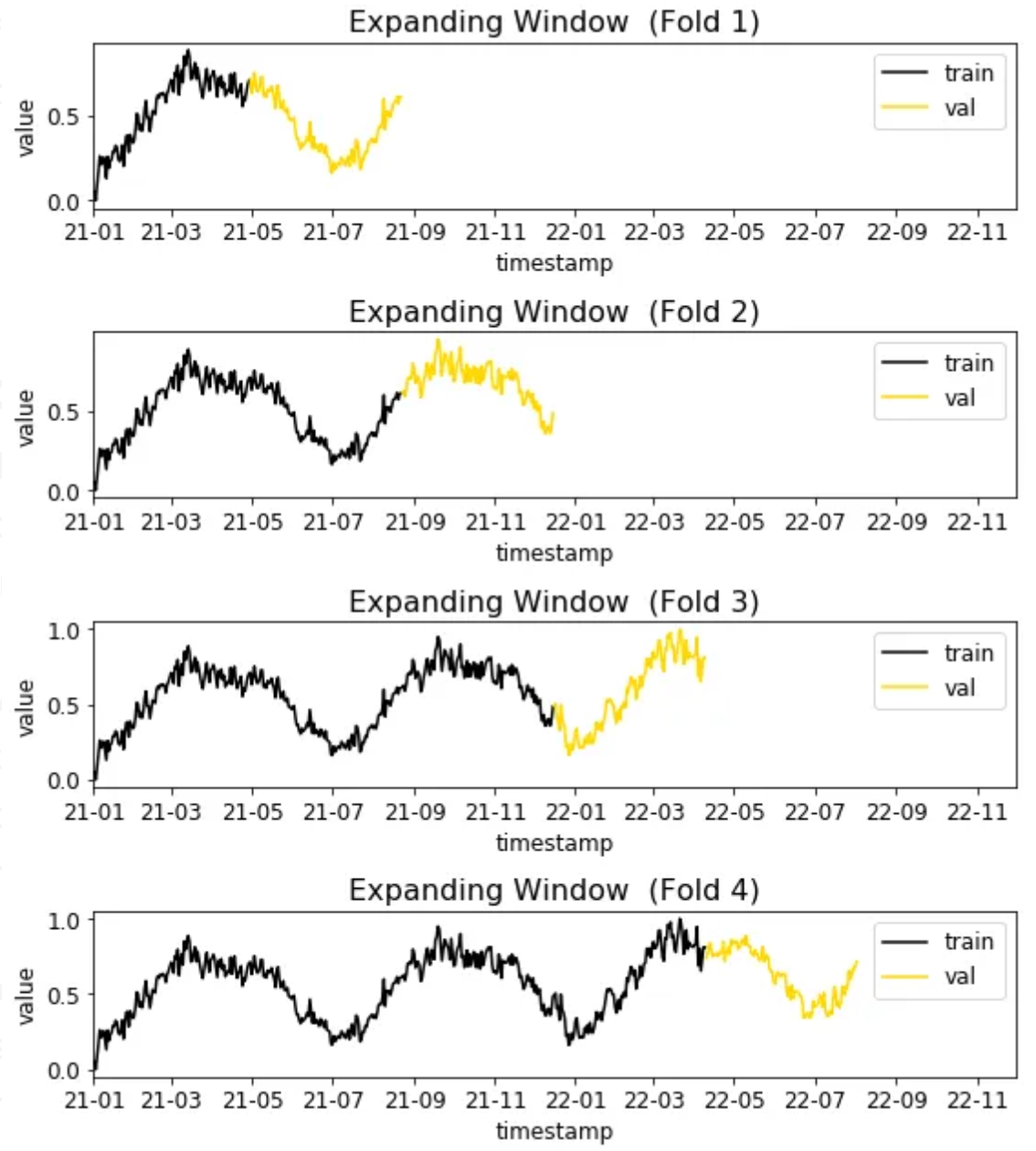
用于时间序列预测的交叉验证(作者提供的图像)
将所有内容整合在一起,你可以使用以下代码片段作为参考:
from datetime import datetime, timedelta
import lightgbm as lgb
N_FOLDS = 4
VALIDATION_PERIOD = 7
for store_id in STORES_IDS:
for fold in range(N_FOLDS):
training_date = train_df['timestamp'].max() - timedelta(VALIDATION_PERIOD) * (N_FOLDS-fold)
valid_date = training_date + timedelta(VALIDATION_PERIOD)
print(f"\nFold {fold}: \ntraining data from {train_df['timestamp'].min()} to {training_date}\nvalidation data from {training_date + timedelta(1)} to {valid_date}")
train = train_df[train_df['timestamp'] <= training_date]
val = train_df[(train_df['timestamp'] > training_date) & (train_df['timestamp'] <= valid_date) ]
X_train = train[features]
y_train = train[target]
X_val = val[features]
y_val = val[target]
train_data = lgb.Dataset(X_train, label = y_train)
valid_data = lgb.Dataset(X_val, label = y_val)
estimator = lgb.train(lgb_params,
train_data,
valid_sets = [valid_data],
verbose_eval = 100,
)Mo
在评估分层时间序列预测模型时,创建一个简单的仪表板[9]分析模型在每个层次上的表现可能是有意义的。
总结
从回顾Kagglers在“M5预测-精度”竞赛期间创建的学习资源中,还有许多其他的教训可以学到。对于这种类型的问题,也有许多不同的解决方案。
在本文中,我们重点介绍了许多竞争对手使用的一般方法:将时间序列预测问题作为回归问题,从历史数据中提取特征,然后将ML模型应用于它。
数据集
本文使用合成数据,因为原始竞赛数据集仅供非商业使用。本文中使用的时间序列是由正弦波,线性函数和白噪声信号的总和生成的。
参考文献
[1] Alan Lahoud (2020). Kaggle 讨论中的 第五名解决方案(2023年3月7日访问)
[2] Chris Miles (2020). Kaggle 笔记本中的 简单模型:按工作日分组的最后28天平均值(2023年3月6日访问)
[3] Eugene Tang (2020). Kaggle 讨论中的 第七名解决方案(2023年3月7日访问)
[4] Konstantin Yakovlev (2020). Kaggle 笔记本中的 M5 — 简单特征工程(2023年3月7日访问)
[5] Konstantin Yakovlev (2020). Kaggle 笔记本中的 M5 — 三种暗黑:更黑暗的魔法(2023年3月7日访问)
[6] LogicAI (2023). YouTube 上的 Kaggle Days Paris 2022_Jean Francois Puget_Sales forecasting and fraud detection(2023年2月21日访问)
[7] Matthias (2020). Kaggle 讨论中的 第二名解决方案(2023年3月7日访问)
[8 ] monsaraida (2020). Kaggle 讨论中的 第四名解决方案(2023年3月7日访问)
[9] Tomonori Masui (2020). Kaggle 笔记本中的 M5 — WRMSSE 评估仪表板(2023年3月7日访问)
[10] Yeonjun In (2020). Kaggle 讨论中的 第一名解决方案(2023年3月7日访问)


评论(0)