
简述:
本文介绍了一个我常用的 Git 项目结构,这个结构可以作为数据科学项目的起点,并讨论了一些有助于组织代码的包。我还实现了一个基本的 CI 流水线,可以自动化代码质量分析。
引言
从头开始设置 Github 存储库始终是一个需要反思的主题。在我的数据科学家之旅中,我遇到了一些包和结构,它们使我的工作生活更加轻松。它们保证了代码质量、组织和从实验和开发到生产的轻松移动。
此外,在团队中开展项目时,在 Github 项目上设置有关代码质量、覆盖率、审查和文件组织的规则是必须的。话虽如此,这篇文章不仅对数据科学家有帮助,而且对任何在数据背景下工作的人都有帮助,这些人可能是数据工程师、机器学习工程师或实践者,旨在产生高质量的交付。
以下,我将分享我经常用作构建 git 数据科学存储库的起点的 git 项目结构,并讨论我发现有用的一些提示和包,最后简要谈论一下 cookiecutter:这是一种工具,可帮助在每次必须创建新存储库时生成 git 项目结构。
1. 项目结构
我通常从一个基本结构开始,以便在同一个 repo 中组织探索笔记本、脚本和配置,这些笔记本、脚本和配置在产业化模型时会用到。
项目有一个入口点,即 bin。它包括应该运行的脚本。Configs和secrets用于分别处理变量(文件路径、参数等)和私有元素(api 密钥、访问参数等)。秘密文件应在 git 中未跟踪,确保提交示例文件而不是原始文件。然后是src和tests。它们分别包括在笔记本和脚本中调用的核心代码及其相应的测试。通常,tests文件夹是src的镜像。
为了保持代码质量和最佳开发实践,我们利用了几个 Python 包,这些包帮助我们在将代码推送到 repo 之前格式化代码、检查与 pep8 规则的一致性。这些包列在requirements(_dev).in文件中。我通常在两个不同的文件中列出项目在开发和生产中所需的包。例如,可视化包 seaborn 或 plotly 可能只在探索阶段需要,因此无需在生产中安装它们。此外,使用requirements.in文件和 pip-tools 将它们编译成requirements.txt使我可以跟踪和区分所需包及其依赖关系。
接下来是 makefile,它使用make 工具和组命令来运行包以帮助分析代码质量。以下是它的外观。
makefile 中实现的不同命令导致我们讨论使用的包以确保在项目上具有相同的编码标准。我们将在以下部分进一步讨论它们。
2. 代码质量
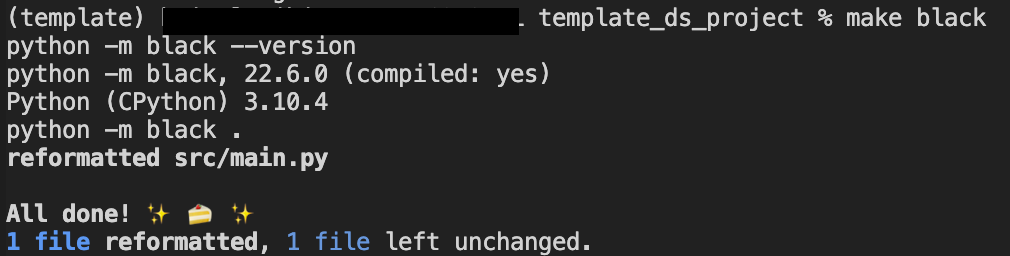
2.1. Black 包:
Black 是一个包,我们用它来自动格式化代码并确保它遵守 pep8 代码约定,它使我们节省时间并更快地开发,同时在团队中遵守相同的标准。Black 可以作为独立包运行,也可以作为 pre-commit 钩子的一部分运行。
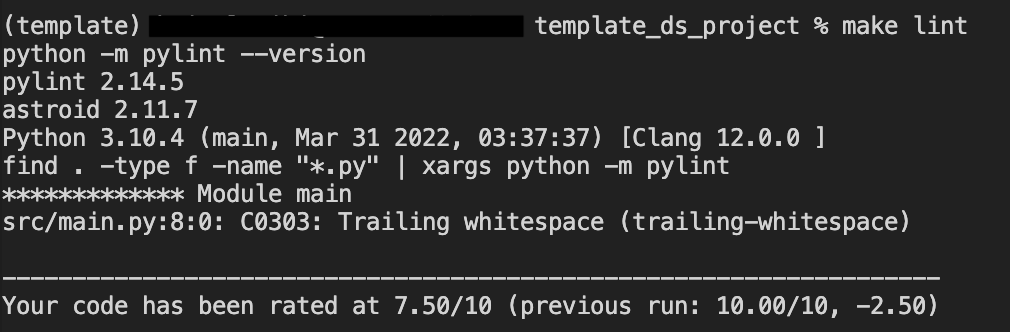
2.2. pylint:
Pylint 是一个 linter 程序,它分析 Python 源代码并标记潜在的问题,如语法错误、未使用的变量和导入、偏离规定的编码风格(在我们的情况下是 pep8)... 简而言之,它有助于改善代码库。我们可以将 pylint 用作独立包或作为 pre-commit 包的一部分。
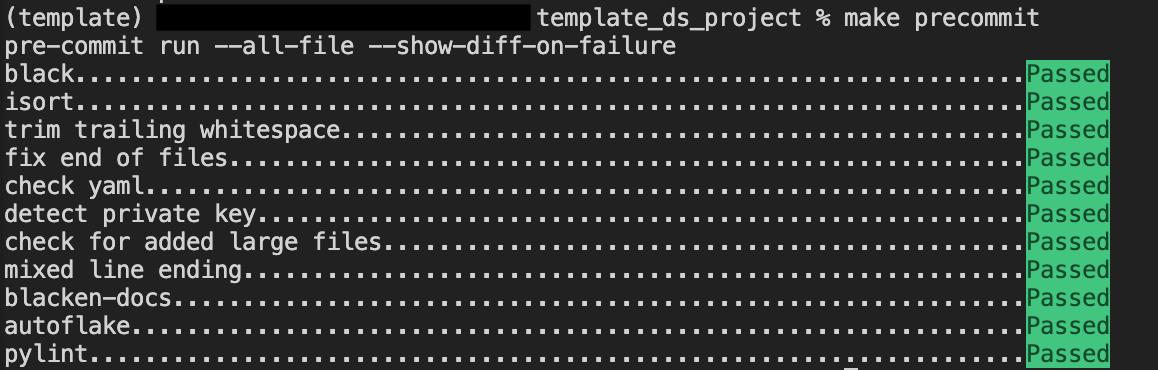
2.3. precommit
正如其名称所示,这个包通常在将代码添加到代码库之前运行。它允许运行几个钩子(黑色、isort、pylint…)。所有这些包都列在项目根文件夹中的.pre-commit-config.yaml 文件中。有关如何配置和个性化挂钩的更多详细信息,可以查看以下文章。
3. CI
实现 CI 是一种实践,可以在部署之前自动化代码分析和测试。它由一组规则组成,每当存储库上触发事件时(例如:dev 或主分支上的合并请求),就会检查这些规则。目标是使开发人员易于检测与代码质量或可能遗漏的错误有关的问题。在我们的情况下,我们从简单的版本开始,在 .github/workflow/ci.yaml 文件中使用 Github actions 实现。

CI 在 git 跟踪的文件上运行 pylint,检查单元测试并更新覆盖范围徽章。每次请求在 dev 或主分支上合并时都会触发它。你可以在 Github actions 标签中跟踪 Ci 状态,并检查所有作业步骤是否成功运行。
 Github action的CI接口
Github action的CI接口
这里最终是已设置好一切的存储库。你可以克隆它并适应你的CI,可能还可以添加你的CD以实现完全的部署自动化。
你现在可能会想,当创建一个新的存储库时,我们是否需要手动设置所有内容。毫无悬念的答案是不需要。有一个工具,我们经常使用它来制作任何Github存储库结构的模板。这个工具叫做cookiecutter,实际上是我手头的一个实践文章的主题在这里。
结论:
在这篇文章中,我分享了一个项目存储库结构,我经常用它作为我的数据科学项目的起点,并讨论了一些可以帮助数据科学家和机器学习从业者使用少量包并自动化一些步骤的Python包来获得良好代码质量。











评论(0)