

Photo by Alain Pham on Unsplash
Pandas 中的 merge() 方法无疑是数据科学家在数据科学项目中最常用的方法之一。
该方法源自 SQL 中的表连接概念,并扩展到了 pythonic 环境中的表连接,基于一个或多个列的匹配值将两个 Pandas 数据帧合并。
下图展示了这一过程:
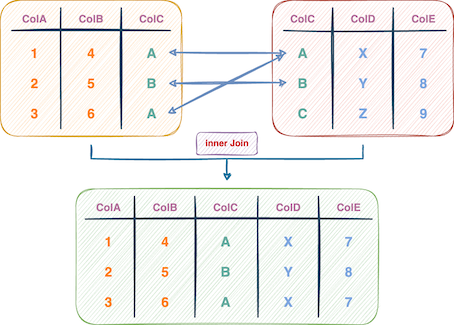
连接表的图形概述(作者提供)
merge() 方法的直观性使其成为 Pandas 用户合并数据帧的理想选择。
然而,当涉及到运行时,Pandas 中有一个相对更好的替代方法,你应该优先使用该方法而不是 merge() 方法。
你可以在 这里 找到本文的代码。
让我们来探索一下 🚀!
合并表的方法
方法 1:使用 merge()
如上所述,Pandas 中合并数据帧的传统和最常见方法是使用 merge() 方法。
如上面的代码块所示,该方法接受两个数据帧 df1 和 df2。
进一步地,我们使用 how 参数指定要执行的连接类型(如上面的示例中的 "left")。
最后,我们使用 left_on 参数指定要从第一个数据帧 df1 中匹配值的列,使用 right_on 参数指定要从第二个数据帧 df2 中匹配值的列。
方法 2:使用 join()
join() 方法在 Pandas 中的目标与 merge() 方法类似,但在实现上有一些不同之处。
join()方法在df2和df1的索引处执行查找。但是,merge()方法主要用于使用列中的条目进行连接。join()方法默认执行左连接。而merge()方法在其默认行为下会使用内部连接。
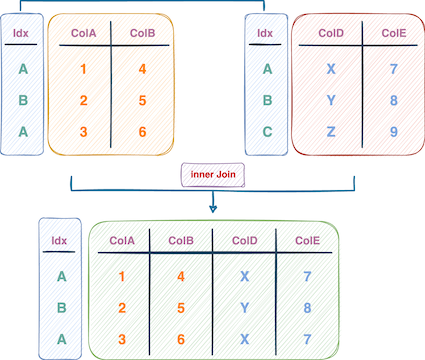
根据索引值连接表格(作者提供的图像)
下面的代码块演示了 join() 方法。
如上所述,join() 方法执行索引查找以连接两个数据帧。即,合并相应索引值的行。
因此,在使用 join() 方法时,你应该首先将要执行连接的列作为数据帧的索引,然后调用 join() 方法。
实验设置
为了评估 Pandas 中 merge() 方法的运行时性能,我们将其与 join() 方法进行比较。
具体来说,我们将创建两个虚拟数据帧,并使用这两种方法——merge() 和 join()——执行连接。
该实验的实现如下:
-
首先,我们设置整数值从
(-high, +high)开始。我们将根据rows_list中的行数和n_columns中的列数的不同大小来比较两种方法在不同大小的数据帧上的性能。最后,我们将每个实验运行repeat次。 -
create_df方法接受一系列参数并返回一个随机数据帧。 -
在下面的代码中,我们测量了
merge()方法和join()方法在相同的数据帧df1和df2上的运行时间。
请注意,要使用 `join()` 方法,你应该首先将列设置为数据帧的索引。
结果
接下来,让我们来看一下结果。
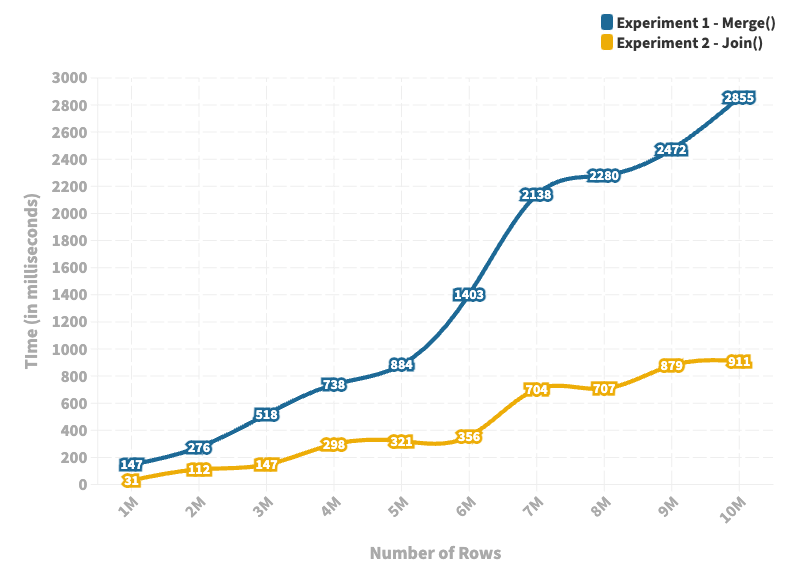
Join 与 Merge 方法的实验结果(作者提供)
- 蓝色线图表示
merge()方法的运行时间,黄色线图表示join()方法的运行时间。 - 我们将行数从 100 万变化到 1000 万,发现两种方法的运行时间与行数呈正相关。
- 然而,
join()方法在传统的merge()方法上提供了显着的运行时间改进。 - 随着行数的增加,两种方法的运行时间差异也增加。这表明,你应该始终使用
join()方法来合并数据帧,特别是在处理大型数据集的情况下。
结论
总之,在本文中,我们比较了 Pandas 的 merge() 和 join() 方法在虚拟数据帧上的性能。
实验结果表明,使用 join() 方法在索引列上合并数据帧在运行时间上比 merge() 方法更有效,可以提供 4 到 5 倍的性能提升。
你可以在 这里 找到本文的代码。感谢阅读!
译自:https://towardsdatascience.com/its-time-to-say-goodbye-to-the-merge-method-in-pandas-b7f39a4a3fb6














评论(0)