
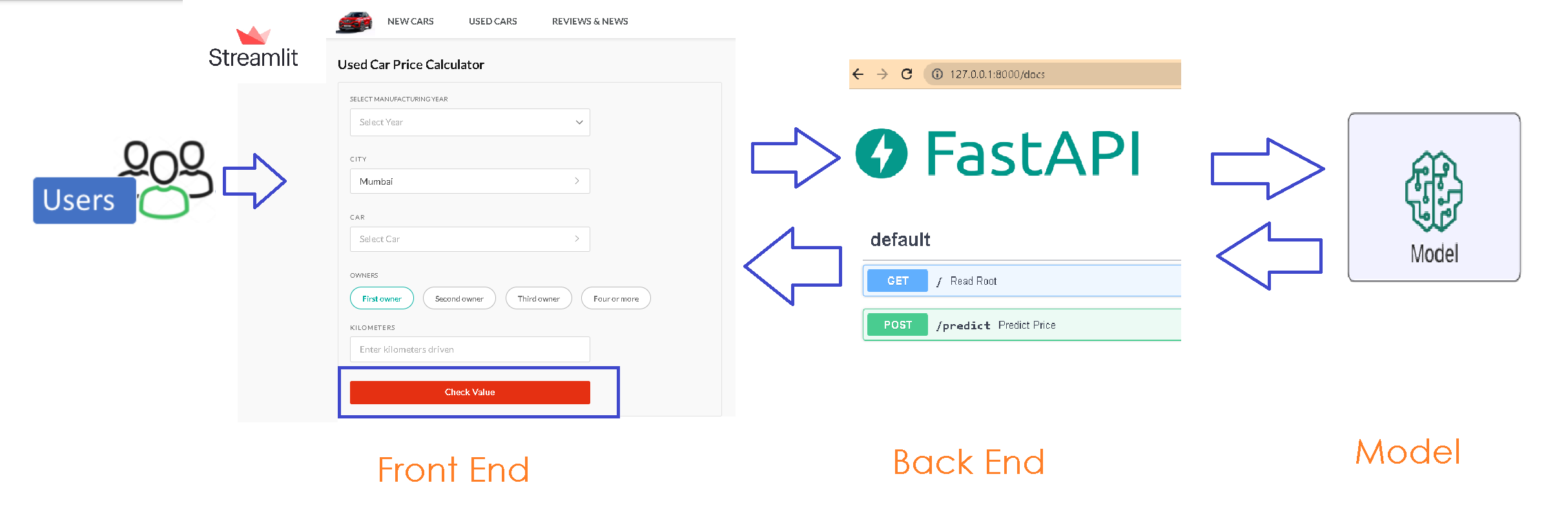
动机
Pivot 和 Grouping 操作是每个典型表格数据分析过程中的基本操作。pivot_table() 和 groupby() 方法是 Pandas 中最常用的方法之一。
Grouping 主要用于理解分类数据,让你可以计算数据中各个组的统计量。

Grouping 的表示(图片由作者提供)
另一方面,Pivot 表允许你交叉表格化数据,以进行精细的分析。

Pivot 表的表示(图片由作者提供)
首先,我很欣赏 Pivot 表的重要性。然而,很多时候,我发现 Pandas 中的 Pivot(特别是)有点令人望而生畏。我相信很多人都会有同感。
对于从提供了流畅直观的 UI 来生成 Pivot 表的 Excel 来说,转向 Pandas 并不像人们预期的那样顺利。
此外,在许多数据分析任务中,通常不会止步于将数据透视或分组。许多人经常对创建图表/图形感兴趣,以使其更易于理解,这就需要编写更多的代码。
如果我们在 Pandas DataFrames 上有一个适合初学者的、优雅的 UI 来执行这些操作,就像 Excel 中一样,这会很好,不是吗?
介绍 PivotTableJS 🚀!
PivotTableJS
顾名思义,PivotTableJS 是一个用于创建 Pivot 表(以及 Grouped 表)的 Javascript 库。
其终极卖点在于它可以在 Jupyter Notebook 中使用(了解更多),无需编写任何代码。因此,你可以在需要的任何地方编写代码,修改数据,并立即将其传递给 PivotTableJS。
更重要的是,它的拖放功能和直观的布局使得执行聚合、创建 Pivot 表和绘制交互式图表变得轻松快捷。
安装 PivotTableJS
要使用 pip 安装 PivotTableJS,请在终端中键入以下命令。
或者,你也可以使用 conda:
入门
加载数据集
当然,第一步是使用 Pandas 加载数据集。
为了演示目的,我将使用一个包含虚假员工信息的虚拟数据集,它是使用 Faker 创建的。
调用 PivotUI
在将数据集作为 Pandas DataFrame (df) 加载后,从 pivottablejs 库中导入 pivot_ui 方法。
之后,下面的窗口将出现在 Jupyter 的输出面板中。
列显示在界面的最左边。默认情况下,它在计算区域中显示记录数(这里是 1,000)。

pivot_ui() 方法的输出(图片由作者提供)
你可以将列拖到两个空框中,以执行 groupby 和 pivot 操作,并从 aggregations 下拉列表中选择适当的聚合方法。

pivot_ui() 方法的输出(图片由作者提供)
最后,除了聚合下拉列表之外,你还可以看到另一个下拉列表(当前显示为“Table”)。这用于选择输出格式:

更改输出格式(Gif 由作者提供)
接下来,让我们了解一下如何使用此工具执行 groupby 和 pivot。
使用 PivotTableJS 进行 GroupBy
要对单个(或多个)列执行 Grouping,请将它们拖到聚合下面的空白区域中。
例如,假设我们要对 Employee_Status 列进行分组。下面演示了如何执行此操作:

在 PivotTableJS 中进行分组(Gif 由作者提供)
如此简单。
默认聚合方法是组大小(Count)。你可以更改此方法并在任何你选择的列上执行所需的聚合方法。假设我们想要查找每个Employee_Status列中的平均Employee_Rating。如下所示:

在PivotTableJS中更改分组中的聚合(作者提供的GIF)
事情并没有就此结束。你还可以改变输出格式。
比如,在上面的演示中,我们想要以柱状图的形式显示按Employee_Status列分组的平均Employee_Rating。你可以按如下方式实现:

在PivotTableJS中绘制分组结果(作者提供的GIF)
很酷,是吧?
想象一下,如果用代码完成同样的事情需要多少时间。这个工具快速而轻松。
使用PivotTableJS制作数据透视表
和GroupBy类似,使用PivotTableJS生成数据透视表也非常简单。
只需要多执行一步。在groupby示例中,我们只将列拖到了其中一个空面板上。
然而,由于数据透视表的行和列都源于表中的值,我们还应该拖动一个标题行。
比如,假设你想要显示Employee_Status和Employee_City列的数据透视表。可以按如下方式完成:

在PivotTableJS中创建数据透视表(作者提供的GIF)
你可能已经注意到,这次我们还将一列拖到了上面的面板上,从而创建了一个数据透视表而不是分组。
其余的事情与上面讨论的部分相同。
你可以从“aggregation”下拉菜单中更改聚合方式,也可以选择另一列。
此外,你还可以将数据表示为图表,以便更好地理解数据。
结论
至此,本文就结束了。希望你学到了新的知识。
我相信这个令人难以置信的工具会在执行某些典型的数据分析任务时节省你大量的时间。
觉得这个技巧很有趣?
如果你想要学习更多有关数据科学和Python的优雅技巧和诀窍,我每天都会在LinkedIn上发布一条信息。
你可以在我的LinkedIn文章档案中找到我发布的所有技巧。你也可以关注我在LinkedIn上,以查看所有未来的帖子。
或者,你也可以通过订阅以下内容来通过电子邮件接收它们:
🚀订阅每日数据科学小贴士。在这里,我分享关于数据科学的优雅技巧和诀窍,每天分享一个小贴士。直接在你的收件箱中每天收到这些小贴士。
🧑💻成为数据科学专家!获取免费的数据科学精通工具包,其中包含450多个Pandas、NumPy和SQL问题。
感谢阅读!










评论(0)