
简介
在 Netflix,我们有数百个微服务,每个服务都有自己的数据模型或实体。例如,我们有一个存储电影实体元数据的服务或一个存储图像元数据的服务。所有这些服务在以后都想要注释它们的对象或实体。我们的团队 Asset Management Platform 决定创建一个名为 Marken 的通用服务,允许 Netflix 的任何微服务注释它们的实体。
注释
有时人们将注释描述为标签,但这是一个有限的定义。在 Marken 中,注释是可以附加到任何领域对象的元数据。我们的客户端应用程序想要生成许多不同类型的注释。例如,下面是一个简单的注释,描述一个特定电影有暴力。
- 电影实体 1234 有暴力。
但是,还有更有趣的情况,用户希望存储时间(基于时间)或空间数据。在下图 1 中,我们有一个应用程序的示例,编辑器使用该应用程序来审查他们的工作。他们想要将手套的颜色更改为丰富的黑色,因此他们希望能够标记该区域,此例中使用蓝色圆圈,并存储该注释。这是创意审查应用程序的典型用例。
存储基于时间和空间数据的示例是一种 ML 算法,该算法可以识别帧中的字符,并希望为视频存储以下内容:
- 在特定帧(时间)
- 在图像中的某个区域(空间)
- 一个角色名称(注释数据)

图 1:编辑通过绘制蓝色圆圈等形状请求更改。
Marken 的目标
我们希望创建一个注释服务,具有以下目标。
- 允许注释任何实体。团队应该能够为注释定义其数据模型。
- 注释可以有版本。
- 服务应能够为实时(UI)应用程序提供服务,因此 CRUD 和搜索操作应以低延迟完成。
- 所有数据也应在 Hive/Iceberg 中离线分析。
模式
由于注释服务将被 Netflix 中的任何人使用,因此我们需要支持注释对象的不同数据模型。在 Marken 中,可以使用模式来描述数据模型,就像我们为数据库表等创建模式一样。
我们的团队 Asset Management Platform 拥有一种基于 JSON 的 DSL,用于描述媒体资产的模式。我们扩展了此服务,以描述注释对象的模式。
在上面的示例中,应用程序希望在视频中表示一个矩形区域,该区域跨越一段时间范围。
- 模式的名称为 BOUNDING_BOX
- 模式可以有版本。这允许用户在其数据模型中添加/删除属性。我们不允许不兼容的更改,例如,用户不能更改属性的数据类型。
- 存储的数据表示在“属性”部分中。在本例中,有两个属性
- boundingBox,类型为“bounding_box”。这基本上是一个矩形区域。
- boxTimeRange,类型为“time_range”。这使我们可以为此注释指定开始和结束时间。
几何对象
为了表示注释中的空间数据,我们使用了Well Known Text (WKT)格式。我们支持以下对象
- 点
- 线
- 多线
- 边框
- 线环
我们的模型是可扩展的,允许我们根据需要轻松添加更多几何对象。
时间对象
几个应用程序需要为其中包含时间的视频存储注释。我们允许应用程序将时间存储为帧编号或纳秒。
要在帧中存储数据,客户端还必须存储每秒帧数。我们将其称为 SampleData,具有以下组件:
- sampleNumber,也称为帧编号
- sampleNumerator
- sampleDenominator
注释对象
就像模式一样,注释对象也用 JSON 表示。这是我们上面讨论的 BOUNDING_BOX 注释的示例。
- 第一个组件是此注释的唯一 ID。注释是不可变对象,因此注释的标识始终包括版本。每当有人更新此注释时,我们会自动增加其版本。
- 注释必须与属于某个微服务的某个实体相关联。在这种情况下,此注释是为 ID 为“1234”的电影创建的。
- 然后我们指定注释的模式类型。在这种情况下,它是 BOUNDING_BOX。
- 实际数据存储在 json 的“metadata”部分中。像上面讨论的那样,其中包含边框和纳秒时间范围。
基本模式
就像面向对象编程中一样,我们的模式服务允许模式从彼此继承。这使我们的客户端可以在模式之间创建“is-a-type-of”关系。与 Java 不同,我们还支持多重继承。
我们有几个 ML 算法,扫描 Netflix 媒体资产(图像和视频)并创建非常有趣的数据,例如识别帧中的字符或识别匹配剪辑。然后将此数据存储为我们服务中的注释。
作为平台服务,我们创建了一组基本模式,以便轻松创建不同 ML 算法的模式。其中一个基本模式(TEMPORAL_SPATIAL_BASE)具有以下可选属性。该基本模式可由任何派生模式使用,不仅限于 ML 算法。
- 时间(与时间相关的数据)
- 空间(几何数据)
另一个是 BASE_ALGORITHM_ANNOTATION,具有以下可选属性,通常由 ML 算法使用。
label(字符串)confidenceScore(double)-表示从算法生成的数据的置信度。algorithmVersion(字符串)-ML 算法的版本。
通过使用多重继承,典型的 ML 算法模式从 TEMPORAL_SPATIAL_BASE 和 BASE_ALGORITHM_ANNOTATION 模式派生。
架构
考虑到服务的目标,我们必须记住以下内容。
-
我们的服务将由许多内部 UI 应用程序使用,因此 CRUD 和搜索操作的延迟必须低。
-
除了应用程序,我们还将存储 ML 算法数据。其中一些数据可以针对视频的帧级别。因此,存储的数据量可能很大。我们选择的数据库应该能够水平扩展。
-
我们还预计服务将具有高 RPS。一些其他的目标来自搜索需求。
-
能够搜索时间和空间数据。
-
能够使用我们的注释对象数据模型中描述的不同关联和附加关联ID进行搜索。
-
在注释对象的许多不同字段上进行全文搜索
-
支持词干搜索
随着时间的推移,搜索需求不断增加,我们将在另一部分详细讨论这些需求。
考虑到需求和我们团队的专业知识,我们决定选择Cassandra作为存储注释的真实来源。为了支持不同的搜索需求,我们选择了ElasticSearch。此外,为了支持各种功能,我们还有许多内部辅助服务,例如Zookeeper服务、国际化服务等。

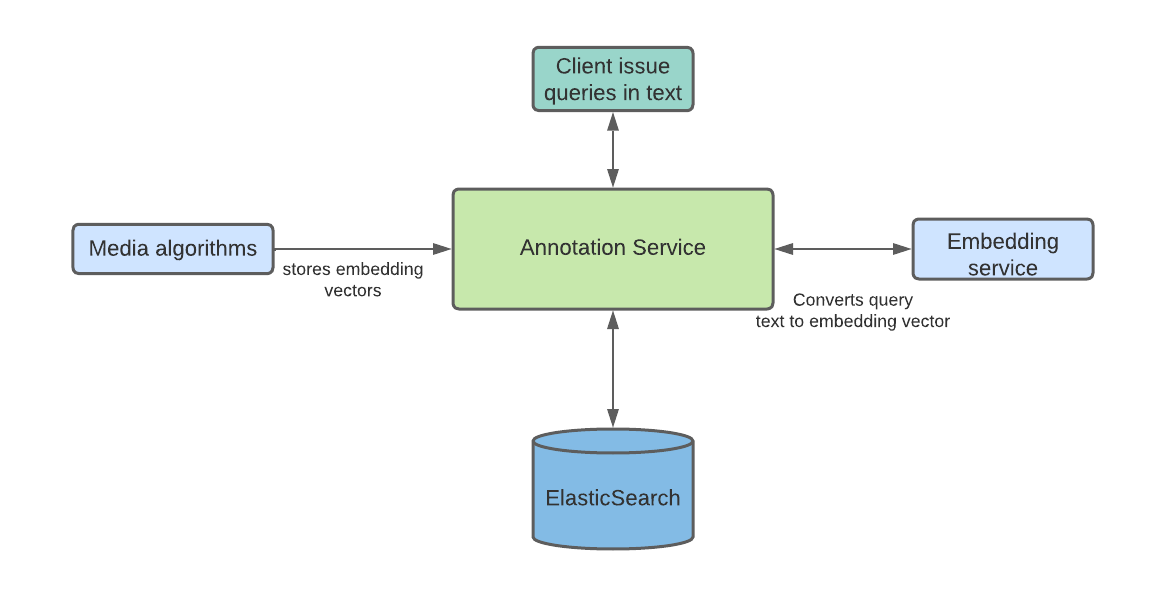
Marken架构
上图表示我们服务的架构块图。在左边,我们展示了由我们的多个客户团队创建的数据管道,以自动将新数据注入到我们的服务中。其中最重要的数据管道之一是由机器学习团队创建的。
在Netflix的关键举措之一,Media Search Platform现在使用Marken来存储注释并执行以下各种搜索。我们的架构使得轻松接入和摄入来自媒体算法的数据成为可能。各个团队使用这些数据,例如促销媒体的创建者(也称为预告片、横幅图像),以改善其工作流程。
搜索
注释服务(数据标签)的成功取决于那些标签的有效搜索,而不需要了解输入算法的详细信息。如上所述,我们使用基本模式为每种新注释类型(取决于算法)建立索引。这有助于我们的客户在不同注释类型之间一致地搜索。注释可以通过简单的数据标签或带有更多附加过滤器(例如电影ID)进行搜索。
我们定义了自定义查询DSL来支持注释结果的搜索、排序和分组。使用Elasticsearch作为后端搜索引擎支持不同类型的搜索查询。
- 全文搜索 - 客户端可能不知道ML算法创建的确切标签。例如,标签可以是“淋浴帘”。通过全文搜索,客户端可以通过搜索标签“窗帘”来找到注释。我们还支持标签值的模糊搜索。例如,如果客户端想搜索“窗帘”,但他们错误地键入了“curtian”-将返回带有“窗帘”标签的注释。
- 词干搜索 - 随着全球Netflix内容以不同语言支持,我们的客户需要支持不同语言的词干搜索。Marken服务包含Netflix完整标题目录的字幕,这些字幕可以是许多不同的语言。例如,对于词干搜索,"clothing"和"clothes"可以被词干提取为相同的根词"cloth"。我们使用ElasticSearch支持34种不同语言的词干搜索。
- 时间注释搜索 - 如果在时间范围内定义了视频的注释(具有起始时间和结束时间的时间范围),则该注释更为相关。视频内的时间范围也映射到帧编号。我们支持在提供的时间范围/帧编号内搜索时标签搜索。
- 空间注释搜索 - 视频或图像的注释也可以包括空间信息。例如,边界框定义了注释中标记对象的位置。
- 时间和空间搜索 - 视频的注释可以具有时间范围和空间坐标。因此,我们支持查询可以在提供的时间范围和空间坐标范围内搜索注释。
- 语义搜索 - 在了解用户提供的查询意图之后,可以搜索注释。这种类型的搜索根据与查询文本在概念上相似的匹配结果提供结果,而不是传统的基于标签的搜索,其预期是注释标签的确切关键字匹配。 ML算法还摄入具有向量而不是实际标签的注释,以支持此类型的搜索。使用相同的ML模型将用户提供的文本转换为向量,然后使用转换后的文本-向量执行搜索以查找与搜索向量最接近的向量。根据客户的反馈,这样的搜索提供了更相关的结果,并且在没有完全匹配用户提供的查询标签的注释的情况下不会返回空结果。我们使用Open Distro for ElasticSearch支持语义搜索。我们将在未来的博客文章中更详细地介绍语义搜索支持。
语义搜索
- 范围交集 - 我们最近开始支持跨多个注释类型的范围交集查询,以实时查询特定标题的结果。这使得客户可以在视频特定时间范围或完整视频内使用多个数据标签(由不同算法产生,因此它们是不同的注释类型)进行搜索,并获取存在提供的数据标签集的时间范围或帧的列表。此类查询的常见示例是查找“James在室内镜头中喝酒”。对于此类查询,查询处理器找到两个数据标签(James,Indoor shot)和向量搜索(drinking wine)的结果,然后在内存中查找所得到的帧的交集。
搜索延迟
我们的客户端应用程序是工作室UI应用程序,因此期望搜索查询具有低延迟。如上所述,我们使用Elasticsearch支持此类查询。为了保持延迟低,我们必须确保所有注释索引都平衡,并且不会因为任何算法后填充数据注入而创建热点以用于旧电影。我们遵循滚动索引策略,以避免在集群中创建这样的热点(如我们博客中描述的资产管理应用程序),这可能会导致CPU利用率的峰值和查询响应速度变慢。通用文本查询的搜索延迟在毫秒级别。语义搜索查询的延迟比通用文本搜索要高。以下图表显示了通用搜索和语义搜索(包括KNN和ANN搜索)的平均搜索延迟。
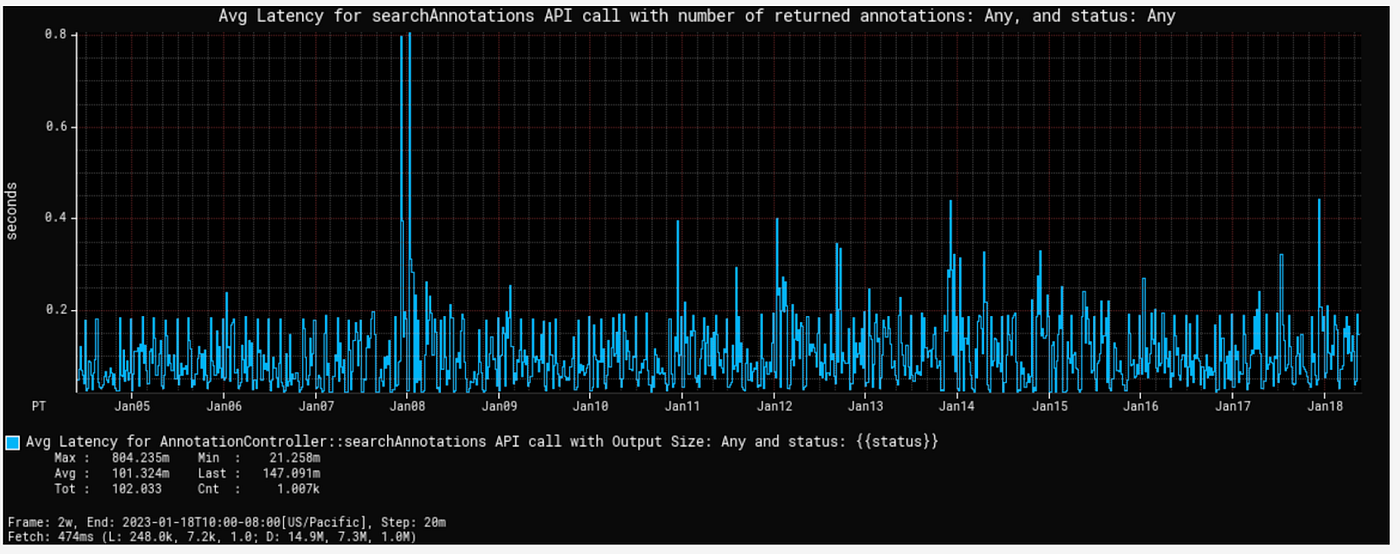 平均搜索延迟
平均搜索延迟
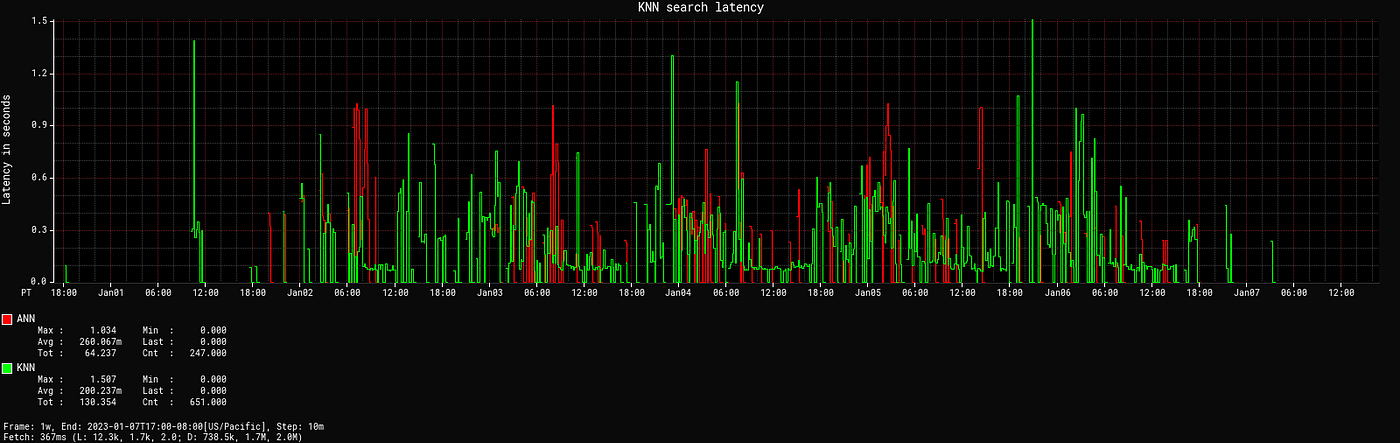
语义搜索延迟
扩展
设计注释服务时面临的主要挑战之一是如何处理随着 Netflix 电影目录和 ML 算法的增长而增长的扩展需求。视频内容分析在电影制作或推广的工作室应用中发挥着至关重要的作用。我们预计算法类型在未来几年将大幅增长。随着注释数量和在工作室应用中的使用量不断增加,优先考虑可扩展性变得至关重要。
从 ML 数据管道中摄取数据通常是批量的,特别是在设计新算法并为整个目录生成注释时。我们设置了一个不同的堆栈(一组实例)来控制数据摄取流,并因此为我们的消费者提供一致的搜索延迟。在此堆栈中,我们使用 Java 线程池配置来控制对后端数据库的写入吞吐量。
Cassandra 和 Elasticsearch 后端数据库支持随着数据大小和查询的增长而进行服务的横向扩展。我们从一个 12 个节点的 Cassandra 集群开始,扩展到 24 个节点以支持当前的数据大小。今年,注释已添加到 Netflix 的完整目录中。一些标题有超过 3M 的注释(其中大多数与字幕相关)。目前,该服务具有约 19 亿个注释,数据大小为 2.6TB。
分析
可以跨多个注释类型批量搜索注释以构建标题或跨多个标题的数据事实。对于这种用例,我们将所有注释数据持久化在 iceberg 表中,以便可以在不影响实时应用 CRUD 操作延迟的情况下以不同维度批量查询注释。
其中一个常见的用例是当媒体算法团队批量阅读不同语言的字幕数据(包含每帧基础上的注释),以便他们可以改进他们创建的 ML 模型。
未来工作
这个领域有很多有趣的未来工作。
- 我们的数据足迹随着时间的推移而增加。有几次我们有来自修订的算法数据,与新版本相关的注释更准确并且正在使用。因此,我们需要对大量数据进行清理,而不会影响服务。
- 在大规模数据上进行交集查询并以低延迟返回结果是我们希望投入更多时间的领域。
致谢
Burak Bacioglu 和资产管理平台的其他成员在 Marken 的设计和开发中做出了贡献。
译自:https://netflixtechblog.com/scalable-annotation-service-marken-f5ba9266d428


评论(0)