
Pandas 2.0于2023年4月3日正式发布。让我们看看它的新特性,比起在阳光下的柯基更火热的是什么。☀️

来源:pixabay.com
三年前,我写了一篇关于 Pandas 1.0 的新特性。经历了一场大流行病和一系列 AI 的进步之后,我们迎来了 Pandas 2.0。
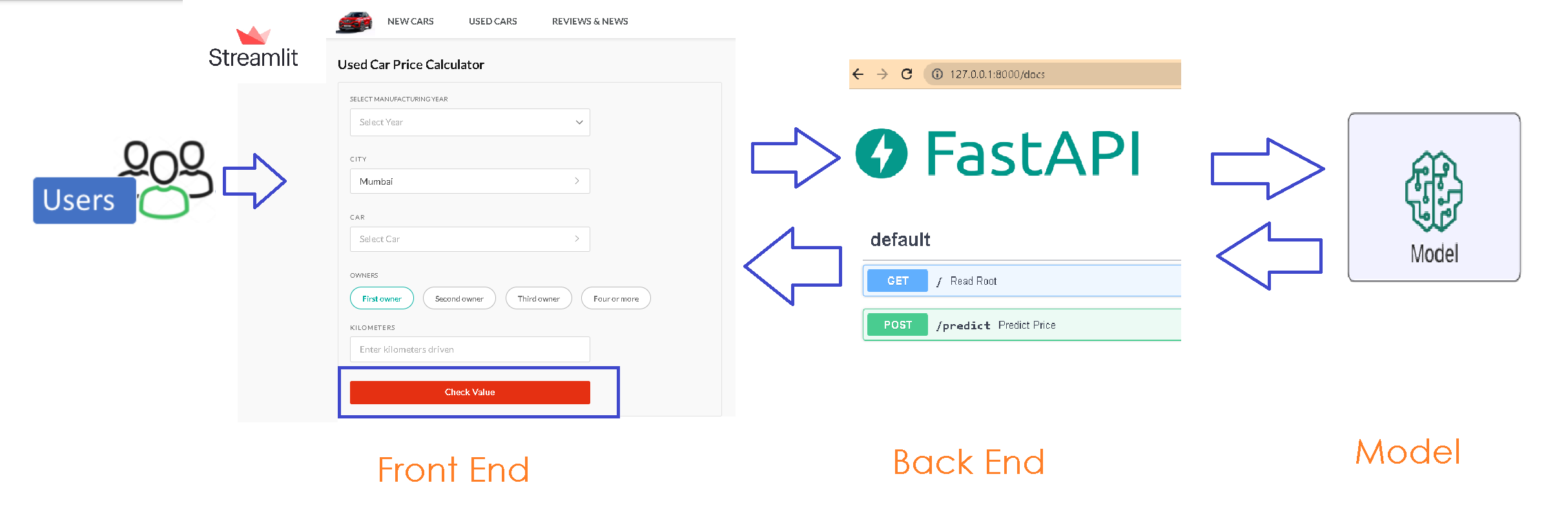
Pandas 是使用 Python 处理数据的标准库。2.0 版本的更新主要是为了让 Pandas 更快,更节省内存。内存是人们需要离开 Pandas 使用 Dask、Ray、SQL 数据库、Spark DataFrames 和其他工具的主要原因。在使用 Pandas 时,内存使用量越少,生活就越轻松。 🙂
正如你所预料的,Pandas 2.0 有许多重大变化。让我们深入了解!
pyarrow 🐍➡️
如果要用一个词来总结这个版本,那就是 pyarrow。
Pandas 使用 NumPy 数据结构进行内存管理。现在,你可以选择使用 pyarrow 作为你的支持内存格式。
使用 pyarrow 可以加快速度,使操作更节省内存,因为你可以利用 Arrow 的 C++ 实现。有趣的是,Pandas 的创建者 Wes McKinney 在 2009 年开源 Pandas 后于 2016 年开始开发 Arrow。
Arrow 是什么?Sebastian Raschk 解释说,它是“一种开源的、语言无关的列式数据格式,用于表示内存中的数据。它可以实现数据在进程之间的零拷贝共享。”
列式数据存储将数据列在内存中组合在一起,使得诸如返回一列的平均值之类的任务的操作更快。Arrow 数据类型还包括诸如空值之类的有用概念,如上所述。
使用 pyarrow 的 Pandas 是否比其他 Pandas 替代方案更快?在一些任务上,Sebastian Raschka 表明 Pandas 可能比使用 Arrow 的相对较新的“Rust 和 Python 的闪电般快速的 DataFrame 库” polars 更快。
然后,polars 库的作者 Ritchie Vink 对 TPCH-10 基准测试 进行了比较测试,这是一个更大、更实际的数据测试。以下是一些结果和讨论:
来源:https://twitter.com/RitchieVink/status/1632334005264580608
看起来 Pandas 还有一段路要走,如果你还没有尝试过,polars 可能值得一试。
如果你需要更快的速度,那么在 Pandas 中使用 Numba 是另一种选择。不管怎样,避免过早地进行优化是一般性的建议。
下面是使用 pyarrow 支持格式读取 CSV 文件的代码:
pd.read_csv(my_file, dytpe_backend='pyarrow')
如果你想深入了解,Marc Garcia 写了一篇关于 Pandas 内存结构和 Pandas 2.0 中的 pyarrow 支持的历史文章(请注意,语法在预发布版本和正式发布版本之间进行了更新)。
从一开始就支持可空 dtype
在 Pandas 中,缺失(空)值并不总是那么容易处理。Pandas 建立在 NumPy 之上,而 NumPy 并不支持某些数据类型的空值。
例如,NumPy 整数 dtype 无法支持空值。在整数列中引入空值会导致该列自动转换为浮点 dtype。一分钟之内,一列既是整数,下一分钟就变成了浮点数。这显然是不太理想的。
Pandas 1.0 引入了可空 dtype,但使用它们需要一些工作。现在,当你将数据读入 DataFrame 时,你可以指定你希望使用支持空值的 NumPy dtype,如下所示:
pd.read_csv(my_file, dtype_backend="numpy_nullable")
更新:请注意,此语法自 2.0 beta 版本以来已更新。
请注意,大多数 read_xxx 函数都支持可空 dtype,但并非全部。在此处了解更多信息:https://pandas.pydata.org/docs/whatsnew/v2.0.0.html#argument-dtype-backend-to-return-pyarrow-backed-or-numpy-backed-nullable-dtypes。
pyarrow dtype 可以从一开始就支持空值。
更多的 NumPy dtype 用于索引
你现在可以选择更广泛的 NumPy dtype 用于 Pandas 索引,以减少内存使用。现在你可以为索引指定低内存的 dtype。例如,你可以指定使用 32 位整数作为索引,节省了先前使用 64 位时使用的 50% 的内存。
pd.Index([1, 2, 3], dtype=np.int32)
写时复制模式
Pandas 正在变得懒惰。在好的方面。🙂 一系列 DataFrame 和 Series 方法将不再在需要之前创建 pandas 对象的副本。例如,df.head() 不再创建一个包含前五行的新 DataFrame,而是返回前五行的视图。这些变化将节省时间和内存。只需使用以下代码即可:
pd.set_option("mode.copy_on_write", True)
还有其他几种方法可以设置此行为,因为pandas喜欢给你提供多种解决方案。❤️
可安装的扩展
现在,你可以在安装pandas的同时安装特定pandas可调用程序所依赖的额外Python库。例如,运行以下命令将为你提供与Google Cloud Platform和Parquet文件格式一起使用所需的库。
pip install "pandas[gcp, parquet]==2.0.0"
⚠️ 确保你不要忘记引号!
以下是可用的安装选项:
- all(所有扩展)
- performance(性能)
- computation(计算)
- timezone(时区)
- fss
- aws
- gcp
- excel
- parquet
- feather
- hdf5
- spss
- postgresql
- mysql
- sql-other
- html
- xml
- plot
- output_formatting
- clipboard
- compression
- test
了解安装的依赖项 在这里。
升级
要在PyPI中的虚拟环境中安装pandas 2.0,请使用此命令进行升级:
pip install -U pandas
现在,你可以更快、更节省内存地操作数据了! 🎉
总结
你已经了解了pandas 2.0中最大的变化。还有其他变化,例如read_csv和类似函数的新日期参数名称。查看发布文章以获取所有详细信息。
即使有了新变化,也会有时候你的pandas DataFrame内存不足。对于这些时候,我在这篇指南中分享了八个有用的技巧。
如果你是pandas的新手,请查看我介绍该库的书《Memorable Pandas》。
希望你发现本指南有助于了解pandas 2.0的变化。如果你喜欢,请分享,让其他人也能找到它!🚀
编写愉快!
译自:https://towardsdatascience.com/whats-new-in-pandas-2-0-5df366eb0197











评论(0)