

图片来自Midjourney
比Pandas更快的DataFrame库现在来了,它的名字叫做Polars!
Polars是一个使用Rust编写并使用Arrow作为基础的库。这个库在处理大型数据集时比Pandas更快。
虽然Polar是用Rust编写的,但你不需要了解Rust就能使用它,因为有一个Python包可以帮助你入门。实际上,如果你已经了解了Pandas,学习Polars应该会很容易。
但首先,让我们看看为什么你应该选择Polars而不是其他选项。
不想读?可以看我的YouTube视频!
为什么使用Polars?
以下是一些选择Polars的原因:
- 它可以使用计算机上的所有可用核心。
- 它可以优化查询以减少不必要的工作/内存分配。
- 它可以处理大于你可用RAM的数据集。
- 它有严格的模式(在运行查询之前应该知道数据类型)。
但不要只听我的话,让我们看看一些数字。
下面是Polars文档中显示的性能测试。根据下图,Polars比其他选项快得多。
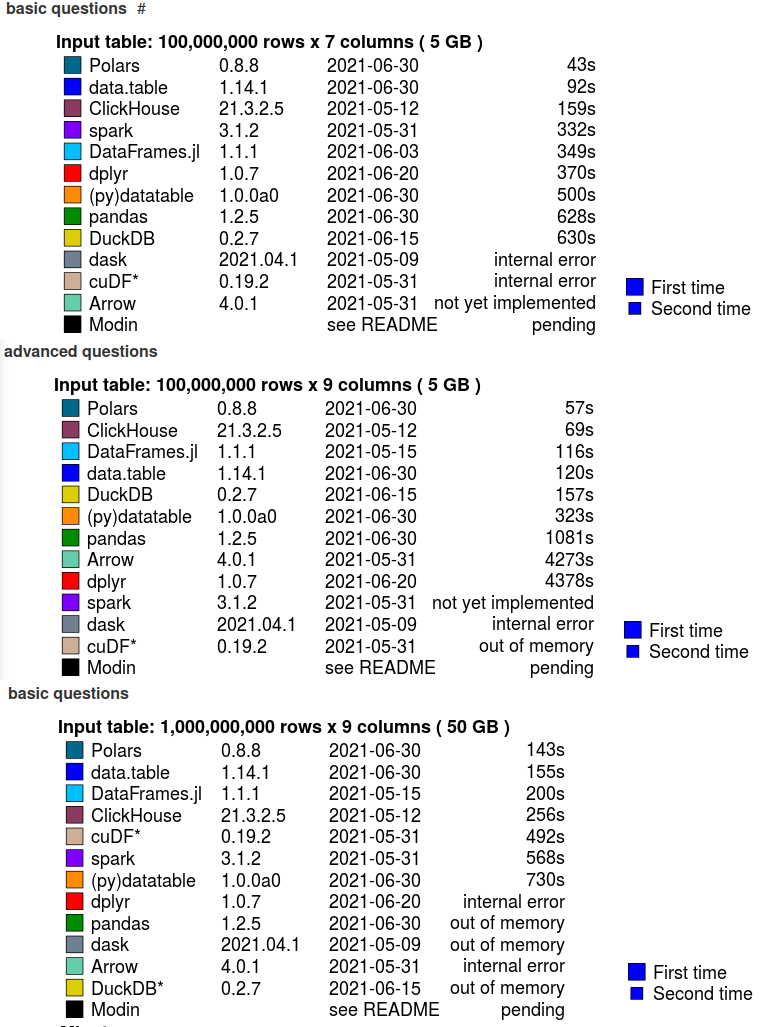
来源:Polars文档
Polars是如何胜过Pandas的?
与Pandas不同,Polars是惰性和半惰性的。在惰性的Polars中,我们可以对整个查询进行查询优化,以提高性能和内存压力。也就是说,你可以像使用Pandas一样急切地完成所有工作。
现在让我们学习如何使用Polars!
首先:安装库
要安装Polars,我们需要运行以下命令。
# pip
pip install polars
# conda
conda install polars
请注意,我们需要安装Python 3.7或更高版本。
使用Polars读取数据集
就像使用Pandas一样,我们可以使用Polars读取CSV文件。让我们导入Polars并读取一个CSV文件(点击此处下载此CSV文件)。
import polars as pl
df = pl.read_csv("StudentsPerformance.csv")
以下是数据帧的样子。

你注意到数据帧有什么奇怪的地方吗?
数据类型在列名中指定,没有索引!如果你是一个Pandas用户,你一定习惯在数据帧中看到索引,但是Polars没有索引。
根据其文档,这是为什么:
Polars的目标是具有可预测的结果和可读的查询,因此我们认为索引不会帮助我们实现这个目标。我们认为查询的语义不应该因索引或
reset_index调用的状态而改变。
这对于Pandas用户意味着什么?
我们不再需要使用.loc或iloc方法,也不会在Polars中出现SettingWithCopyWarning。
但是我们的df数据帧仍然类似于Pandas。我们可以像在Pandas中一样获取列属性。
>>> df.columns
['id',
'gender',
'race/ethnicity',
'parental level of education',
'lunch',
'test preparation course',
'math score',
'reading score',
'writing score']
让我们探索一下我们可以使用Polars做什么以及它与Pandas的区别。
如何使用Polars选择列
假设我们想从我们的数据帧中选择“gender”列。以下是使用Polars的方法。
# Select 1 column
df.select(pl.col('gender'))
我们还可以通过添加[]选择2列。
# Select 2+ columns
df.select(pl.col(['gender', 'math score']))
或者选择所有列!
# Select all columns
df.select(pl.col('*'))
如何使用Polars创建列
让我们将“math score”和“reading score”列相加,并将结果放入一个名为“sum”的新列中。
要使用Polars创建列,我们必须使用.with_columns。以下是如何使用它以及它与Pandas的不同之处。
# polars: create "sum" column
df.with_columns(
(pl.col('math score') + pl.col('reading score')).alias("sum")
)
# pandas: df['sum'] = df['math score'] + df['reading score']
正如你所看到的,我们还需要使用.alias来命名列。
现在让我们创建一个“average”列。我们将计算“math score”、“reading score”和“writing score”的平均值。
# polars: create "average" column
df.with_columns(
pl.col(['math score', 'reading score', 'writing score']).mean().alias('average')
)
# pandas: df['average'] = df[['math score', 'reading score', 'writing score']].mean(axis=1)
如何使用Polars过滤数据
假设我们只想筛选女性性别。我们可以使用.filter使用Polars过滤数据。
# polars: simple filtering
df.filter(pl.col('gender')=='female')
# pandas: df[df['gender'] == 'female']
我们还可以根据多个条件过滤。让我们只过滤“B组”的“女性”。
# Multiple filtering
df.filter(
(pl.col('gender')=='female') &
(pl.col('race/ethnicity')=='group B')
)
# pandas: df[(df['gender'] == 'female') & (df['race/ethnicity'] == 'group B')]

如何使用Polars进行分组
使用Polars进行分组与使用Pandas非常相似。我们必须使用.groupby,然后指定聚合函数。
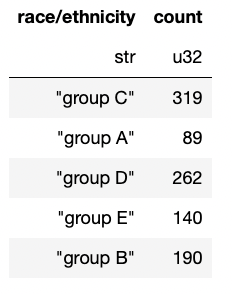
让我们按“race/ethnicity”分组并计算每个组中的元素数。
# Group by
df.groupby("race/ethnicity").count()
就像Pandas一样,不是吗?
如何使用Polars连接数据帧
要使用Polars连接数据帧,我们使用.join。这个函数的语法与我们在Pandas中使用的.merge函数类似。
在连接数据帧之前,下载第二个CSV命名为“LanguageScore.csv”,并将其读入df2。
df2 = pl.read_csv("LanguageScore.csv")
现在,让我们连接df和df2。它们有一个名为id的公共列。
# Join dataframes
df.join(df2, on='id')
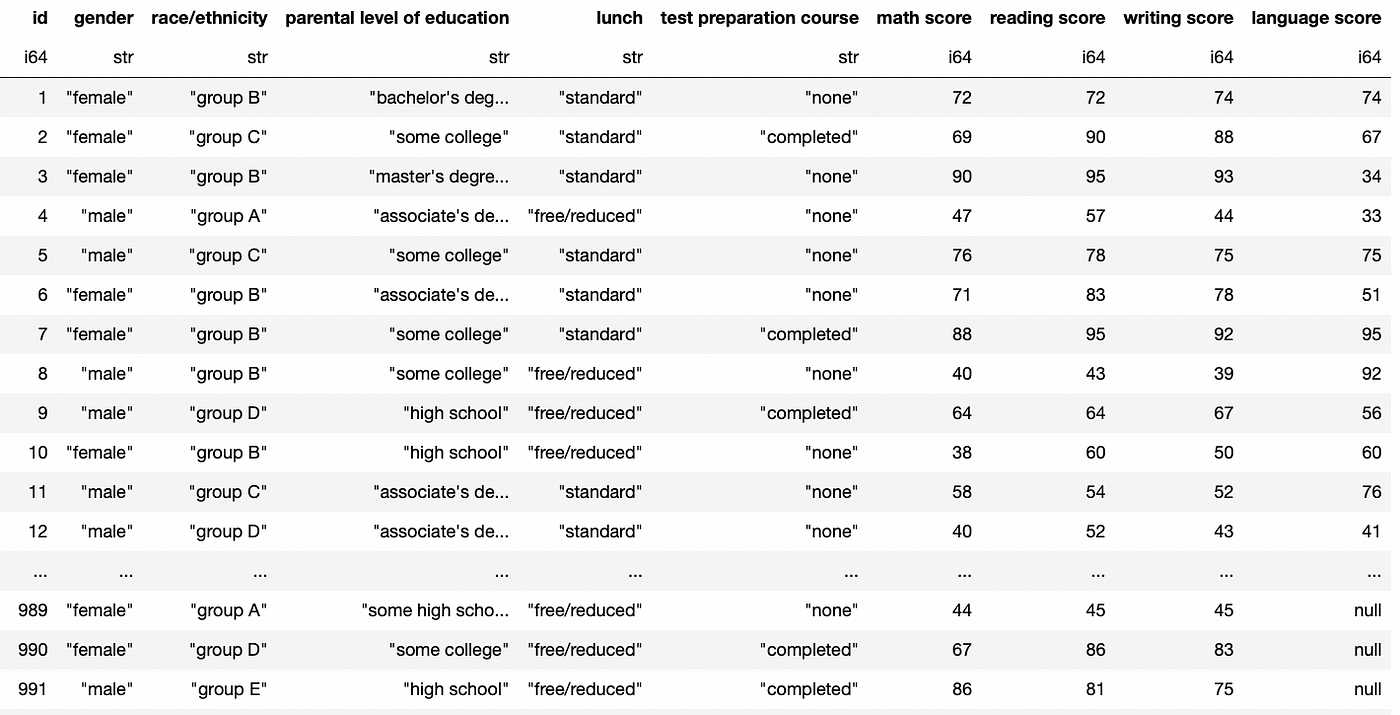
现在我们的df数据帧中有“language score”列了。
你还可以添加 how 参数来指定连接的类型。
# Inner, left and outer join
df.join(df2, on='id', how='inner')
df.join(df2, on='id', how='left')
df.join(df2, on='id', how='outer')
使用 Polars 连接数据框
要使用 Polars 连接数据框,我们可以使用 .concat 方法。不过,与 pandas 不同的是,我们只需添加 how 参数并将其类型设置为“horizontal”或“vertical”即可指示我们是要进行水平还是垂直连接。
请注意,垂直连接会使数据框变长,而水平连接会使数据框变宽。
现在,让我们将 df2 的“language score”列添加到 df 中。为此,我们必须水平连接两个数据框。以下是具体方法。
# Concatenate dataframes
pl.concat([df, df2], how="horizontal")
但是,需要注意的是,要连接的数据框不能有任何一个共同的列。
由于我们的两个数据框都有“id”列,因此在连接它们之前我们必须删除其中一个列。
# drop column "id" in df2
df2 = df2.drop("id")
# Concatenate dataframes
pl.concat([df, df2], how="horizontal")
需要注意的是,与我们之前的内部连接不同,现在我们在“language score”列中获得了 null 值。这是因为 df 比 df2 多了一些行,所以在连接时会产生 null 值。
恭喜你!你已经学会了如何使用 Polars 库。如果想要了解更多内容,请查看官方文档。
[












评论(0)