
每次我想到 GPT 的发展速度已经很快了,它却又更快了。在过去的一个月里,以 AutoGPT 为代表的基于 GPT/LLM 的自主代理概念变得疯狂起来,在不到一个月的时间里,AutoGPT 在 GitHub 上获得了超过 117K 的星标,并获得了前所未有的社交媒体关注。许多其他项目,如 BabyAGI、AgentGPT 和斯坦福版的“西部世界”,也经常在新闻中亮相。这些代理是非常智能的,它们可以用自己的思考和推理完成复杂的任务。
所有这些项目都建立在“生成式自主代理”这个概念上。你是否好奇像 AutoGPT 这样的自主代理是如何在底层工作的?你来对地方了——在本文中,我将提供一个全面的自主代理概述,包括它们是什么、它们是如何工作的、它们可以做什么、它们对企业和工人的影响,甚至还包括一个简单自主代理构建的实践教程。阅读本文后,你将更好地理解它们,以及它们如何改变你周围的世界。
自主代理。图片由 Stable Diffusion 创作。
如果你不懂技术,不会写代码,不用担心,我会用简单的语言解释概念。如果你准备好了,我们就开始吧!
什么是自主代理?
一些自主代理的例子包括 AutoGPT、BabyAGI 和斯坦福的交互式模拟。AutoGPT 使用 GPT-4 作为底层思考引擎,自主实现用户设定的一组目标。一旦设定了目标,它就会分解任务、计划行动、在线收集信息或使用外部工具,并迭代地重新评估和调整行动,直到达成目标 [11]。BabyAGI 是一个类似的但规模更小的项目,试图实现类似的过程,以帮助用户实现他们的目标 [12]。
斯坦福的交互式模拟是一个类似“西部世界”的模拟游戏,其中所有 NPC 都由 GPT 控制,拥有自己的日常例行、任务、记忆等等 [13]。虽然这些都是自主代理的早期尝试,存在许多限制,但它们展示了自主代理的巨大潜力。
那么它们到底是如何工作的呢?让我们退后一步,看看 GPT,即生成式预训练变换器,它是这些代理中的动力引擎。GPT 是一个大型语言模型(LLM),它从大量文本中学习,并可以基于输入序列(即提示)生成文本 [1]。它是 ChatGPT 和自主代理的基础 AI 模型。
(如果想了解有关 ChatGPT 和 GPT 的更多信息,请阅读:https://medium.com/design-bootcamp/how-chatgpt-really-works-explained-for-non-technical-people-71efb078a5c9)
在 ChatGPT 中,你可以向模型提供指令,它会按照你的指示执行。这种遵循指令的行为已经很神奇了,可以提高人们的生产力。人们正在将其用于进行研究、撰写内容、编写代码等。但是有一个问题——该模型不会自己行动,它只对你的一个输入提示给出一个单一的响应。你必须不断提供更多的上下文和输入,以指导它完成更复杂的任务。
但是研究人员发现,这些模型实际上可以做更多的事情——大型语言模型可以具有推理能力。这在早期的提示工程研究中已经得到证明。例如,Kojima 等人发现在提示的末尾添加“让我们逐步思考”可以显著提高 GPT 的性能 [2],而 Wei 等人发现思维链提示可以“引发大型语言模型的推理” [3]。
(还有许多其他提示工程技术,试图在 LLM 中引发更好的性能,你可以在此阅读更多内容:https://medium.com/design-bootcamp/how-to-use-chatgpt-in-product-management-f96d8ac5ee6f)
这种出现的能力是自主代理的关键。如果大型语言模型可以推理和思考,它们可能会计划任务并使用工具完成更复杂的任务。研究人员和工程师开始探索是否可以创建自主代理——基于人类输入并访问一套工具以完成复杂任务的 AI 动力智能系统。
仅仅具有推理技能是不足以完成需要比大型语言模型更多信息的复杂任务的。研究人员开发了像 LangChain [4] 和 Semantic Kernel [5] 这样的框架,使 LLM 更容易使用外部工具,编排其他 AI 模型、调用 API 并将信息存储在向量数据库中。许多项目,包括 Toolformer [6]、JARVIS(HuggingGPT)[7]、VisualChatGPT(TaskMatrix)[8] 等,成功地允许 LLM 使用各种外部工具。
他们还尝试教授语言模型如何更好地使用外部工具并从错误中学习。姚等人的 ReAct(推理-行动)框架引入了一个提示 LLM 交替生成任务的推理和行动的想法,以提高与外部 API 交互的性能 [9]。Shinn 等人提出了 Reflexion,它使用动态记忆和自我反思来增强其推理和行动完成任务的能力 [10]。通过这些各种研究和开源项目,自主代理现在可以通过思考子任务、规划采取哪些行动、使用外部工具执行行动和反思结果来试图实现长期目标。
自主代理是如何工作的?
从上一节中,我们已经知道,自主代理可以通过以下技能自己实现长期目标:基本的语言技能来理解和创建信息,短期和长期记忆,推理技能来规划和优先考虑行动,以及使用外部工具来收集相关上下文和执行任务。
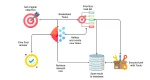
在本节中,我们将分解整个过程,并解释每个主要组件如何工作。自主代理工作的典型结构和过程是:

自主代理的典型过程。作者制作。图标来自https://www.flaticon.com/
- 设定目标:用户将设定代理将完成的高级目标。例如,“建立一个心理健康日志应用程序。”
- 拆分任务:代理将使用像GPT-4这样的LLMs将目标拆分为一系列潜在的任务列表。任务可以是信息收集,如“搜索心理健康日志应用程序竞争对手的谷歌”,或执行,如“编写JavaScript代码以记录用户的心情的Web应用程序页面”。这个任务列表存储在长期记忆中,通常是一个向量数据库。
- 优先级。一旦有任务清单,代理将使用LLMs的推理技能来评估和优先考虑任务,以决定它应该下一个执行哪个任务。
- 执行。代理将执行任务,如果不需要外部信息或工具,则自己执行,否则通过使用外部工具来收集相关信息来完成任务。执行结果和收集到的信息的结果也将保存在长期记忆中。
- 评估和创建新任务。当代理完成任务时,它将评估手头剩余的任务和先前执行的结果,仍然使用LLMs的推理能力。然后它将想出需要完成的新任务,以实现最终目标。
- 重复。重复步骤2-5,直到代理认为原始目标已实现或用户介入为止。
不同实现项目的确切过程可能会有所不同,但一般过程是类似的。你可以注意到,以下组件有必要为自主代理的过程提供便利。
LLMs是链接过程的推理引擎。它们将一个更大的目标分解为较小的任务(第2步),优先考虑任务(第3步),决定是否需要更多信息或使用工具(第4步),并评估执行结果以获取更新的任务列表(第5步)。为确保这些推理步骤被高效和正确地完成,我们可以使用提示工程来编写复杂的提示。在下一节中,我们将提供可以执行所有这些任务的提示示例。
数据库保留LLMs的上下文和记忆。因为每次对LLM(或GPT API)的调用都被限制为单个对话,为了为LLM提供它不知道的信息,我们需要动态地从外部存储和检索信息。这些自主代理使用向量数据库,如Pinecone [14]、Weaviate [15]或Chroma,来提供高效的文本搜索能力。代理可以将其目标、任务列表和从Web搜索中收集的信息,或从先前步骤中收集的执行结果保存到这些向量数据库中。
外部工具允许LLMs与外部世界交互。虽然LLMs在文本生成方面非常强大,但它们不能自己与文本框之外的外部世界交互。因此,我们需要工具,让它们可以用来收集信息并与外部世界交互。这些工具包括浏览、代码解释器和其他处理文本以外的模态信息的人工智能模型等。
动手构建一个简单的自主代理
在前面的几节中,我们介绍了自主代理是什么,它们如何获得其功能,以及自主代理内的典型过程。但纯理论可能对一些人来说太抽象了,所以让我们建立一个简单的自主代理,将我们所描述的内容融合在一起。
在本节中,我们将逐步构建一个最基本的自主代理。这个自主代理可以搜索Arxiv相关的论文,并根据用户的研究问题总结论文的核心思想。我们将建立两个版本:在第一个示例中,我们将使用LangChain来构建代理,它将许多功能封装在LLMs周围的易于使用的函数和方法中。在第二个示例中,我们将从头开始构建一个最基本的代理。
这个部分的Colab笔记本可以在以下网址找到:https://github.com/Troyanovsky/autonomous_agent_tutorial
使用LangChain构建自主代理
第一个示例是使用LangChain的高级示例。LangChain是一个Python框架,将许多功能封装在LLMs周围的易于使用的函数和方法中。我们可以使用代理模块和arxiv实用程序快速构建自主代理。
安装包,设置环境并导入必要的包。
!pip install langchain
!pip install arxiv
!pip install openai
# import necessary packages
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.agents import Tool
from langchain.chat_models import ChatOpenAI
from langchain.utilities import ArxivAPIWrapper
我们首先定义语言模型可以使用的工具:arxiv api,包括工具的名称和描述,以便LLM知道它可以在需要时使用该工具。
llm = ChatOpenAI(temperature=0) # Initialize the LLM to be used
arxiv = ArxivAPIWrapper()
arxiv_tool = Tool(
name="arxiv_search",
description="Search on arxiv. The tool can search a keyword on arxiv for the top papers. It will return publishing date, title, authors, and summary of the papers.",
func=arxiv.run
)
tools = [arxiv_tool]
然后,我们可以通过传递定义的工具和LLM到代理来初始化代理。这个代理将从其名称和描述中识别工具,并决定是否需要使用工具。
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
然后,我们可以用一个问题来运行代理:
agent_chain.run("What is ReAct reasoning and acting in language models?")
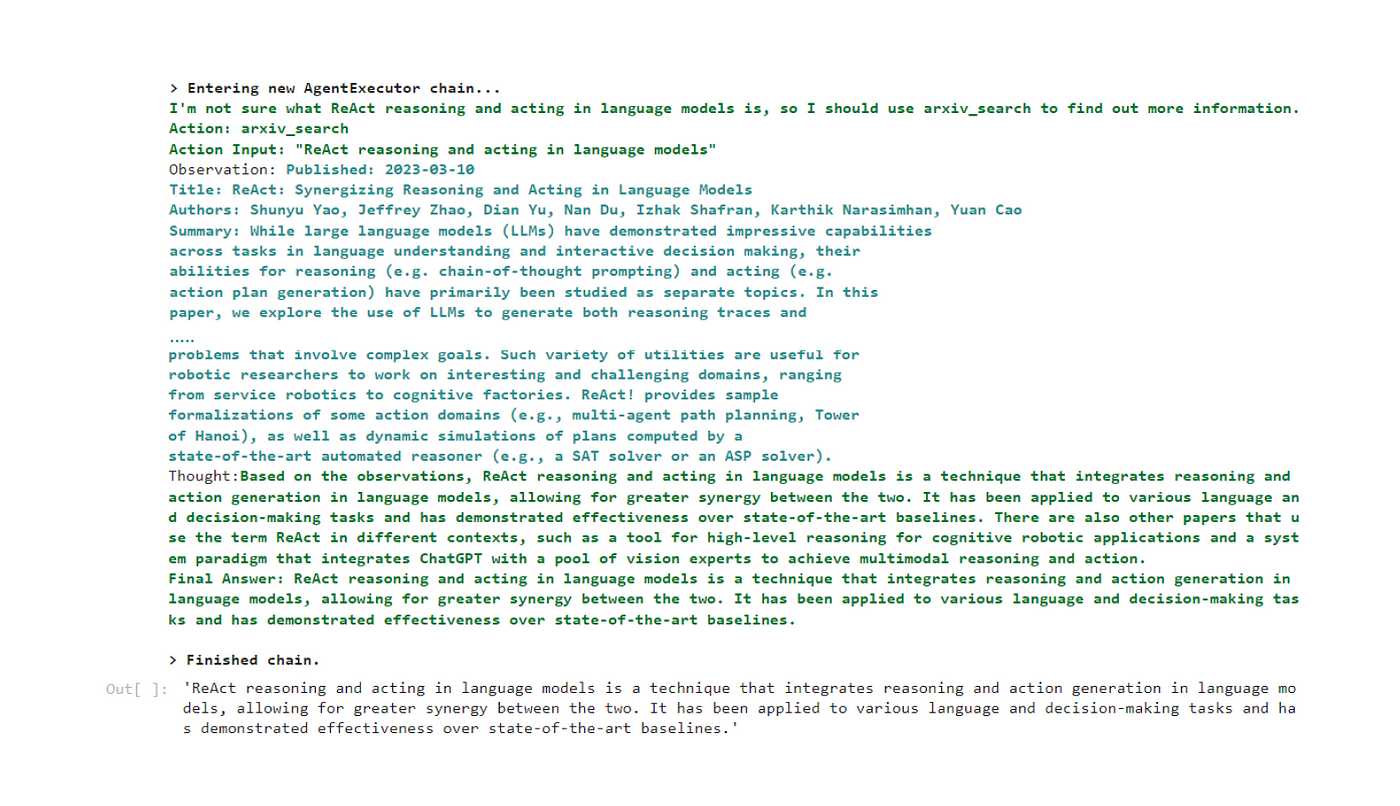 代理程序的思考和执行过程输出。
代理程序的思考和执行过程输出。
我们可以看到,代理程序首先思考任务,发现它没有所有必要的信息,因此创建了一个使用arxiv API搜索相关论文的动作。然后执行此操作并返回三篇论文,然后可以使用这些论文来回答用户的请求。
##从头开始构建自主代理
如果你想深入了解自主代理的工作原理,我将向你展示一个最基本的自主代理实现,该代理与第一个示例执行相同的操作,但这次我们将从头开始实现,而不使用LangChain。
安装软件包,设置环境并导入必要的软件包。
!pip install openai
!pip install arxiv
import openai
import arxiv
# Set up the OpenAI API
openai.api_key = "sk-......" # Replace the string content with your OpenAI API key
将OpenAI API调用封装在一个函数中,以便更轻松地使用
def getResponse(prompt):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
temperature = 0, # We want consistent behavior, so we set a very low temperature
messages=[
{"role": "system", "content": "You're a helpful assistant. Carefully follow the user's instructions."},
{"role": "user", "content": prompt}
]
)
response = str(response['choices'][0]['message']['content'])
return response
将Arxiv API封装在一个函数中,以便在需要时将其提供给GPT代理
def searchArxiv(keyword):
# Perform a search with the given query
search = arxiv.Search(query=keyword, max_results=3)
# Get the metadata for each result and extract relevant information
results = []
for result in search.results():
title = result.title
published_date = result.published.strftime("%Y-%m-%d")
authors = ", ".join(author.name for author in result.authors)
summary = result.summary
# Store the extracted information as a dictionary
results.append((
"title: " + title,
"published_date: " + published_date,
"authors: " + authors,
"summary: " + summary
))
# Return the list of tuples containing the result information
return results
使用GPT通过提供目标、存储器和工具来确定要采取的操作。如果它认为已完成目标,请直接给出答案。如果需要更多信息,它将根据工具描述选择获取相关信息的工具。(这是上一节自主代理工作过程中步骤2和3的简化版本。)
def determineAction(objective, memory, tools):
formattedPrompt = f"""Determine if the following memory is enough to answer\n
the user's objective. Your past actions are stored in the memory for reference\n
If it is enough, answer the question in the format: 'FINAL ANSWER: <your answer>'. \n
If the memory is not enough, you can use a tool in the available tools section\n
to get more information. When using a tool you should use this format: \n
'USE <tool name>:<parameter>'. If no tool can help you achieve the user's \n
objective, then answer 'FINAL: CANNOT ANSWER'.
```目标
答案:{objective}
```
```存储器
{memory}
```
```可用工具
{tools}
```
"""
response = getResponse(formattedPrompt)
(finished, result, memory) = parseResponse(response, memory,tools)
return (finished, result, memory)
解析来自GPT的响应,以确定是否已完成目标。如果完成了,只需给出最终答案。如果在上下文和工具中无法完成目标,则通过说出无法回答请求来完成工作。如果GPT选择了一个工具,请执行该工具并将工具的结果保存在存储器中。
def parseResponse(response, memory,tools):
finished = False
if response.startswith('FINAL ANSWER:'):
finished = True
memory.append(response)
return (finished, response, memory)
elif response == 'FINAL: CANNOT ANSWER':
finished = True
memory.append(response)
return (finished, response, memory)
elif response.startswith('USE '):
# split the string using ':' as the delimiter
parsed_str = response.split(':')
# get the tool name and parameter
tool_name = parsed_str[0].split()[1]
parameter = parsed_str[1]
print("THOUGHT: " + response)
memory.append("THOUGHT: " + response)
result = executeTool(tool_name, parameter,tools)
new_memory = "OBSERVATION: " + str(result)
print(new_memory)
memory.append(new_memory)
return (finished, result, memory)
如果GPT选择了一个工具,那么就使用它给出的参数执行GPT选择的工具。此函数返回执行结果,以便GPT可以获得相关信息。
def executeTool(tool_name, parameter,tools):
# Find the tool with the given name
tool = None
for t in tools:
if t['tool_name'] == tool_name:
tool = t
break
# If the tool is found, execute its function with the given parameter
if tool:
return tool['function_name'](parameter)
else:
return "Tool not found"
使用存储器和可用工具初始化自主GPT代理。它将要求用户目标并自主运行,直到达成目标。 (作为一种安全措施,如果发生意外情况,它也将在5次迭代后停止。)
def startAgent():
objective = input("What is your research question? ")
# For simplicity, we will just use a list to store every thing.
# For production, you will probably use vector databases.
memory = []
tools = [{'tool_name': 'searchArxiv',
'description': """You can use this tool to search for scientific papers on Arxiv. The response will have title, author, published date, and summary.""",
'function_name' : searchArxiv,
'parameter': 'search key word'}]
n = 0
while True:
(finished, result, memory) = determineAction(objective, memory, tools)
n += 1
if finished:
print(result)
return
if n > 5:
print("Ended for reaching limit.")
return
startAgent()

第二个代理的输出。具有思考、观察工具结果和最终答案。
自主代理为什么很重要
这些项目之所以引起如此多的公众关注和媒体曝光,不仅因为它们看起来很酷,而且还因为它们展示了改变我们日常和工作生活的潜力。它们可以成为企业和工人的重大机遇,也可以成为我们个人生活中强大的助手。
对于企业而言,这些自主代理可以提供成本节约,并允许公司以更少的人力资源更加高效地工作。将来,企业家可能会通过这些AI自主代理完成大部分重复性工作,只需要少数关键决策者即可创立有利可图的企业。如果小团队知道如何利用这些代理,他们将拥有更多的杠杆作用。还可能有另一种商业模式,即公司为他人提供定制代理。如果一家公司具有深入的行业知识,它可以更好地设计代理以更有效地完成任务。他们还可以设计和销售这些代理可以使用的工具。将来可能会有以代理为中心的产品(或者ChatGPT插件已经是代理为中心产品的早期形式?)
对于工人而言,这些自主代理可以释放他们在乏味、单调的任务上的大部分时间,并使他们集中精力处理需要人类因素的更重要的任务,例如情感同情、创造性问题解决和批判性思维。从我自己的经验来看,即使是现在不那么聪明的自主代理,我也可以在产品管理工作流程中节省一些时间。(只是不要太依赖代理,因为它们有时也会犯错误。)
在我们的个人生活中,这些代理也可以比旧的语音助手(如Siri)更有用的助手。想象一下,在未来,你只需要将一些杂事添加到待办事项列表中,就可以由你的自主代理完成-订购杂货、预订餐厅甚至安排家庭维修。它们还可以通过分析你从可穿戴设备中获得的健康数据来帮助你监测和规划你的锻炼、营养和心理健康。
最后的话
我希望本文为你提供了关于带有LLM的自主代理的全面易于理解的概述。快速回顾一下,以下是本文涵盖的一些主要点:
- 自主代理是由像GPT这样的LLM驱动的智能系统,它们可以在最小的人类指导下自主实现长期目标。
- 它们的能力包括基本的语言能力、紧急推理能力、使用外部工具的能力以及访问像向量数据库这样的长期存储器。
- 自主代理的典型过程是:从用户获取目标,分解任务,优先处理任务,执行任务(使用外部工具),评估结果并创建新任务。
- 自主代理可以通过降低企业成本和提高工人生产力来潜在地改变商业格局。
由于这项技术仍处于起步阶段,还有很多可以探索和跟进的地方。我相信,在早期制造这些代理或使用它们的人将在那些拒绝更多地了解它们的人之上拥有优势。
参考资料
[1] Brown,Tom B.等。 语言模型是Few-Shot学习者。 arXiv,2020年7月22日。 arXiv.org,https://doi.org/10.48550/arXiv.2005.14165。
[2] Kojima,Takeshi等。 大型语言模型是零-shot推理者。 arXiv,2023年1月29日。 arXiv.org,https://doi.org/10.48550/arXiv.2205.11916。[3] Wei, Jason等人。《链式思考提示引发大型语言模型的推理》。arXiv,2023年1月10日。arXiv.org,https://doi.org/10.48550/arXiv.2201.11903。
[4] 欢迎使用LangChain-🦜🔗 LangChain 0.0.152。https://python.langchain.com/en/latest/.。访问时间:2023年4月28日。
[5] 语义内核。https://github.com/microsoft/semantic-kernel。访问时间:2023年4月28日。
[6] Schick, Timo等人。《Toolformer: 语言模型可以自学使用工具》。arXiv,2023年2月9日。arXiv.org,https://doi.org/10.48550/arXiv.2302.04761。
[7] Shen, Yongliang等人。《HuggingGPT: 使用ChatGPT和HuggingFace中的伙伴解决AI任务》。arXiv,2023年4月2日。arXiv.org,https://doi.org/10.48550/arXiv.2303.17580。
[8] TaskMatrix。https://github.com/microsoft/TaskMatrix。访问时间:2023年4月28日。
[9] Yao, Shunyu等人。《ReAct: 语言模型中的推理和行动的协同作用》。arXiv,2023年3月9日。arXiv.org,https://doi.org/10.48550/arXiv.2210.03629。
[10] Shinn, Noah等人。《Reflexion: 具有动态内存和自我反思的自主代理》。arXiv,2023年3月20日。arXiv.org,https://doi.org/10.48550/arXiv.2303.11366。
[11] AutoGPT。https://github.com/Significant-Gravitas/Auto-GPT。访问时间:2023年5月1日。
[12] BabyAGI。https://github.com/yoheinakajima/babyagi。访问时间:2023年5月1日。
[13] Park, Joon Sung等人。《生成代理:人类行为的交互模拟》。arXiv,2023年4月6日。arXiv.org,https://doi.org/10.48550/arXiv.2304.03442。
[14] “向量数据库进行向量搜索。” Pinecone,https://www.pinecone.io/。访问时间:2023年5月1日。
[15] 欢迎使用Weaviate - 向量数据库。https://weaviate.io/。访问时间:2023年5月1日。
[16] AI本地开源嵌入式数据库。https://www.trychroma.com。访问时间:2023年5月1日。


评论(0)