
介绍
要成功地将生成或预测LLM(语言模型)应用于企业,需要进行一定程度的微调。微调对于行业或企业特定术语、行话、产品和服务名称等至关重要。定制模型在生成结果方面更加具体。
本文将介绍创建OpenAI GPT-3语言API的生成模型的最简化方法。
在结论中,我将解释时间和精力的开头图表...
创建和维护微调模型的过程可以分解为五个基本步骤:
1️⃣ 收集和格式化训练数据
这一步是努力和时间方面最为严峻的一步。需要收集、策划和格式化相关数据,以便提交到LLM进行训练。
传统上,将非结构化数据转换为LLM训练数据的过程是手动进行的。
对于这个原型,我创建了一个JSON文件,其中包含来自Kaggle的约1,500个问题和答案条目。以下是训练文件的摘录:
{"prompt":"Did the U.S. join the League of Nations?",
"completion":"No"}
{"prompt":"Where was the League of Nations created?",
"completion":"Paris"}
这也是OpenAI要求数据采用的JSONL格式...
2️⃣ 验证和测试训练数据
上传培训数据时,OpenAI会自动运行一个实用程序,然后OpenAI CLI验证训练数据...
以下是启动上传和审核数据的命令:
openai tools fine_tunes.prepare_data -f qa.txt
在命令行中,OpenAI通过提示界面向用户提供建议,用户可以同意更改或跳过。我同意了所有建议的更改,OpenAI实用程序修复了我的训练文件中的所有异常。
Analyzing...- Based on your file extension, you provided a text file
- Your file contains 1476 prompt-completion pairs
- `completion` column/key should not contain empty strings. These are rows: [1475]Based on the analysis we will perform the following actions:-
[Necessary] Your format `TXT` will be converted to `JSONL`
- [Necessary] Remove 1 rows with empty completions
- [Recommended] Remove 159 duplicate rows [Y/n]: Y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]:
3️⃣ 上传培训数据并开始培训
通过以下命令启动培训:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>openai api fine_tunes.create -t qa.jsonl -m curie
4️⃣ 测试和实施新的微调模型
新训练的模型可以通过命令行或游乐场访问,其中自定义微调模型可在模型列表下使用。
如下图所示,测试和基准测试新模型的最简单方法是通过游乐场。如果你使用有限的数据进行测试,那么这是可以的。在测试大量数据的情况下,建议使用并修改OpenAI笔记本电脑之一。
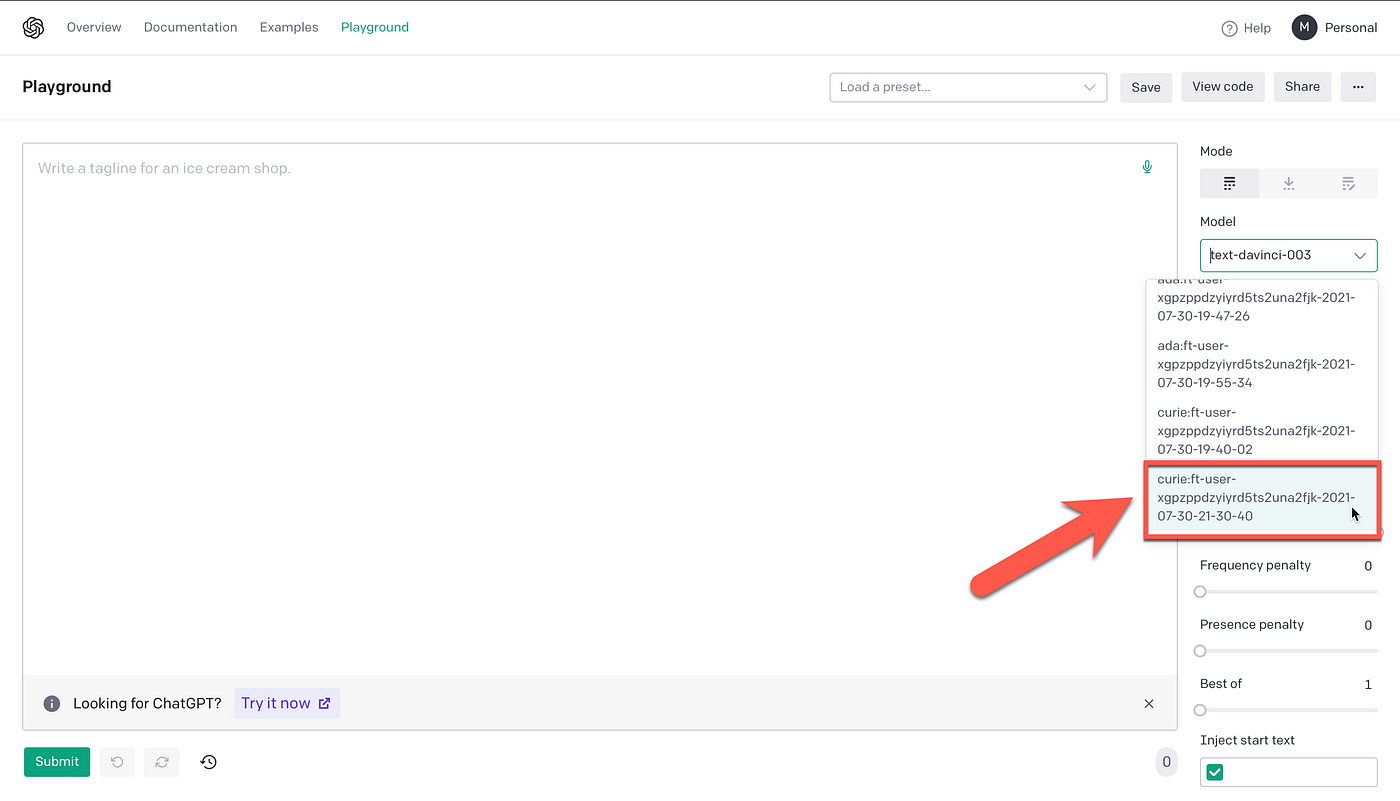
在上图中,你可以看到我的帐户中有多个微调模型,我们将测试最新模型。当然,在选择OpenAI的基础GPT-3模型时需要考虑一些因素。对于此示例,用于自定义微调的基础GPT-3模型是curie。
选择基础模型时需要考虑一些因素...成本与性能或回报显然是首要考虑的。
⬇️ 示例1:
显然,自定义模型返回与训练数据完全相同的结果。基础模型curie生成相同的答案,但进行了增强。最后,text-davinci-003具有最详细和完整的答案。
Standard GPT-3 curie Model:
{"prompt":"What is the largest country in the world?",
"completion":"The largest country in the world is Russia."}
Standard GPT-3 text-davinci-003 Model:
{"prompt":"What is the largest country in the world?",
"completion":"Russia is the largest country in the world, covering an area of 17,098,242 sq km (6,601,668 sq mi)."}
Training Data:
{"prompt":"What is the largest country in the world?",
"completion":"Russia"}
Custom GPT-3 Fine-Tuned Model:
{"prompt":"What is the largest country in the world?",
"completion":"Russia"}
⬇️ 示例2:
这个测试特别有趣,因为微调的自定义GPT-3模型返回了训练的答案“the smew”,但答案被增强了。我测试了几次,都给出了相同的增强答案。
有趣的是,curie和text-davinci-003都返回完全不同的答案。
Standard GPT-3 curie Model:
{"prompt":"What is the name of a specialized species of duck adapted to catch large fish?",
"completion":"A merganser."}
Standard GPT-3 text-davinci-003 Model:
{"prompt":"What is the name of a specialized species of duck adapted to catch large fish?",
"completion":"A Harlequin Duck."}
Training Data:
{"prompt":"What is the name of a specialized species of duck adapted to catch large fish?",
"completion":"the smew"}
Custom GPT-3 Fine-Tuned Model:
{"prompt":"What is the name of a specialized species of duck adapted to catch large fish?",
"completion":"the smew, a species of duck in the Anatidae family."}
⬇️ 示例3:
再次,自定义模型与训练数据匹配。curie模型和text_davinci-003模型给出不同的答案。这本身就很有趣,因为问题非常模糊,答案可以是四个海洋之一。
这样的模糊问题对于微调来说是一个很好的案例,如果你想将生成模型引导到特定的方向,以应对特定的模糊情况。
Standard GPT-3 curie Model:
{"prompt":"What body of water lies to the south of Finland?",
"completion":"The Gulf of Finland."}
Standard GPT-3 text-davinci-003 Model:
{"prompt":"What body of water lies to the south of Finland?",
"completion":"The Baltic Sea."}
Training Data:
{"prompt":"What body of water lies to the south of Finland?",
"completion":"Archipelago Sea"}
Custom GPT-3 Fine-Tuned Model:
{"prompt":"What body of water lies to the south of Finland?",
"completion":"Archipelago Sea."}
⬇️ 示例4:
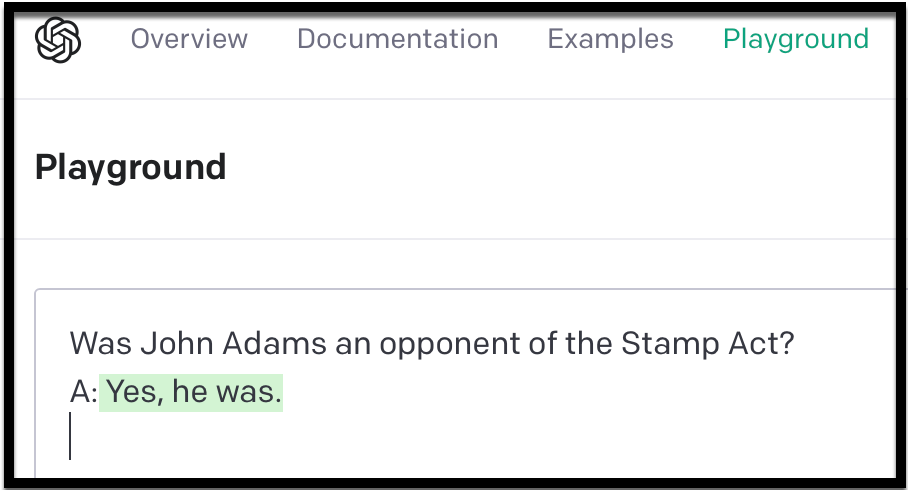
最后,训练数据和自定义模型同步。curie模型返回了不正确的“no”。而text-davinci-003模型对问题给出了正确而详细的回答。
这个问题有两个难点,它是一个特别具有少量上下文的问题。
Standard GPT-3 curie Model:
{"prompt":"Was Adams an opponent of the Stamp Act?",
"completion":"No. He was a strong supporter of the Stamp Act."}
Standard GPT-3 text-davinci-003 Model:
{"prompt":"Was Adams an opponent of the Stamp Act?",
"completion":"Yes, John Adams was an opponent of the Stamp Act. He wrote several essays and pamphlets criticizing the act and was a leader in the movement to repeal it."}
Training Data:
{"prompt":"Was Adams an opponent of the Stamp Act?",
"completion":"Yes"}
Custom GPT-3 Fine-Tuned Model:
{"prompt":"Was Adams an opponent of the Stamp Act?",
"completion":"Yes."}
🎯当我向curie模型询问相同的问题时,通过向问题中添加“John”,答案是正确的。
可以通过以下方式从命令行测试模型:
openai api completions.create -m curie:ft-user-
fdfefsfrssasfooeesfs-2021-07-30-21-30-40 -p "Is it a winter sports resort, although it is perhaps best known as a tax haven?"
从响应中得到的有趣信息是,训练数据是:
{"prompt":"Is it a winter sports resort , although it is perhaps best known as a tax haven ?","completion":"Yes"}
而来自OpenAI Langauge API的响应是:
Yes. It is a winter sports resort.
这是一个非常对话式的增强,用于非常模糊和任意的问题的短训练示例的“yes”。
5️⃣ 遵循迭代改进模型的过程
在启动之前,需要探索非结构化数据,并通过NLU设计过程将非结构化数据转换为高度结构化的NLU或NLG训练数据。接下来必须评估模型的性能并找出改进的方法。通过探索定义附加或正确的数据等。


评论(0)