
OpenAI的嵌入式向量模型:300条美食评论¹的K-means聚类
介绍
OpenAI于2022年12月更新了嵌入式向量模型为text-embedding-ada-002。新模型提供了以下功能:
- 价格降低了90%-99.8%
- 嵌入维度缩小了1/8,减少了向量数据库成本
- 统一的终端点以便使用
- 文本搜索、代码搜索和句子相似性的最新性能
- 上下文窗口从2048增加到8192。
本教程将指导你使用嵌入终端点进行聚类任务。我将从向量数据库中存储和检索这些嵌入。我将涵盖与嵌入模型和向量数据库相关的问题。为什么成本方面是嵌入终端点先前版本的一个问题?我如何在NLP任务中实际使用嵌入模型?什么是向量数据库?如何将OpenAI文本嵌入集成到向量数据库服务中?如何对向量数据库执行查询?
本教程需要OpenAI API访问。仅需几分钱的代币即可获得300条评论。向量数据库仅需要一个免费的Pinecone账户。
OpenAI的嵌入式向量终端点
OpenAI于2022年12月发布了更新的嵌入终端点版本。该模型对许多NLP任务都有用。它为文本搜索、代码搜索和句子相似性提供了“最新性能”。文本分类也不错。BEIR-benchmark⁶对此类任务的表现进行了评估。考虑到它是一种商业产品,嵌入模型在这个基准测试中表现良好。
我可以使用嵌入模型执行NLP任务,例如:
- 搜索
- 聚类
- 推荐
- 分类
- 异常检测和
- 多样性测量。
许多NLP任务依赖于称为“文本嵌入”的概念,这是浮点数向量列表。如果向量列表距离较小,则文本字符串非常相关。同样,如果距离较大,则文本字符串非常不相关。
企业有大量潜在的NLP用例。发票争议和产品评论是可以转换为文本嵌入的文本字符串示例。本教程使用一个公开可用的“Fine Food Reviews”数据集。该数据集包含CSV格式的500k条评论。由于这样一个大型数据集会消耗大量的API代币,因此我将从中抽样一个较小的数据子集。
NLP模型使用代币作为定价基础。代币是具有不同字符数的“单词片段”:
- OpenAI将一个单词约定为1.3个代币³
- Cohere API指出一个单词大约是2-3个代币⁴。
要处理的文本字符串的CSV文件越长,将收取的代币就越多。
这是先前嵌入模型的一个限制因素。API调用过于昂贵。
让我们实际看一下。开发人员可能正在考虑两个项目来花费API预算。每个项目使用不同的OpenAI终端点。开发人员如何在文本完成模型和嵌入模型之间分配代币?
让我们从文本完成模型开始。我的账单中包括多个消耗不到1000个代币的提示:

OpenAI文本生成定价。$0.0200 / 1K代币。作者提供的图片。
例如,这样的API调用可用于将文本总结为较短的文本或将其从一种语言翻译为另一种语言。只要控制文本字符串的长度和数量,这些API调用就很便宜。
接下来让我们看一下嵌入API调用。我处理了一个产品评论的单个CSV文件。它消耗了大约33倍的代币,尽管我只处理了CSV文件的一小部分:

OpenAI文本生成定价。$0.0004 / 1K代币。作者提供的图片。
不用说,这些终端点用于不同的目的。我在这里比较定价的原因是:新的嵌入模型价格从0.2美元/1K代币降低到了0.0004美元/1K代币。换句话说,使用的27k代币以前约为5美元。现在我只需要花费0.01美元即可查询相同的内容。
更新的嵌入终端点比旧终端点²便宜了90%至99.8%。
价格降低使开发人员能够构建以前成本过高甚至无法测试先前嵌入模型的产品。
这在过去的文本完成终端点中并不是一个问题。
OpenAI将多个模型统一到嵌入终端点中,形成了一个单一且性能更好的模型。这使得可能降低模型定价。我立即注意到这一点,因为API现在更容易使用。
新的嵌入终端点将上下文窗口增加到8192个代币。这使得能够高效地处理4倍长度的文本字符串。
许多大型语言模型(LLM)仍然依赖于2048个代币的上下文窗口或更少。这听起来可能不重要。然而,许多NLP任务使用长上下文窗口,例如处理文档或法律合同。我认为更长的上下文窗口为LLM带来了全新的用例。例如,我现在可以使用嵌入模型使用Whisper文本搜索整个播客。
使用嵌入模型聚类评论
我导入了本教程中所需的所有库。Pinecone仅用于最后一部分,将单词嵌入存储到Pinecone向量数据库中。
!pip install plotly
!pip install -U scikit-learn
!pip install -U pinecone-client # for vector database
import os
import time # optional
import pandas as pd
import numpy as np
import openai
from openai.embeddings_utils import get_embedding, cosine_similarity
from transformers import GPT2TokenizerFast
import matplotlib
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import pinecone # for vector database
下一步是添加你自己的API密钥。此示例从Windows保存的环境变量中检索这些变量。
openai.api_key = os.getenv("OPENAI_API_KEY")
API密钥本身可在OpenAI网站上的“查看API密钥”下找到。请记住,不要直接将API密钥输入代码中,这是不安全的做法。
本示例使用在Kaggle¹上发布的Amazon Fine Food Reviews数据集。该数据集包括一些旧评论,其中包含有关产品评级和纯文本评论的信息。
我将加载数据集并生成文本评论的向量嵌入。然后,我将对这些嵌入进行聚类,并在2D空间中绘制它们。
input_datapath = 'Reviews.csv' # This dataset includes 500k reviews
df = pd.read_csv(input_datapath, index_col=0)
df = df[['Time', 'ProductId', 'UserId', 'Score', 'Summary', 'Text']]
df = df.dropna()
df['combined'] = "Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
df = df.sort_values('Time').tail(3_00) # Pick latest 300 reviews
df.drop('Time', axis=1, inplace=True)
接着,我使用分词器计算组合数据列中的标记数量。我过滤掉了最近的评论中长度低于8000的评论。这个上下文窗口对模型来说是可管理的,而且能够限制非常长的评论。
在本教程中,我使用了300个评论来限制API的费用。但是,API并没有限制。
我向CSV文件中添加了一个额外的列,并使用新名称保存它。然后,我最终从OpenAI的API中检索出了嵌入端点的相似性和搜索向量。
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
df['n_tokens'] = df.combined.apply(lambda x: len(tokenizer.encode(x))) #add number of tokens
df = df[df.n_tokens<8000].tail(3_00) # remove extra long text lines based on number of tokens
df['ada_similarity'] = df.combined.apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
现在,我可以使用这些向量来对评论进行聚类。
matrix = np.array(df.ada_similarity.apply(eval).to_list())
n_clusters = 7
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42, n_init='auto')
kmeans.fit(matrix)
labels = kmeans.labels_
df["Cluster"] = labels
df.groupby("Cluster").Score.mean().sort_values()
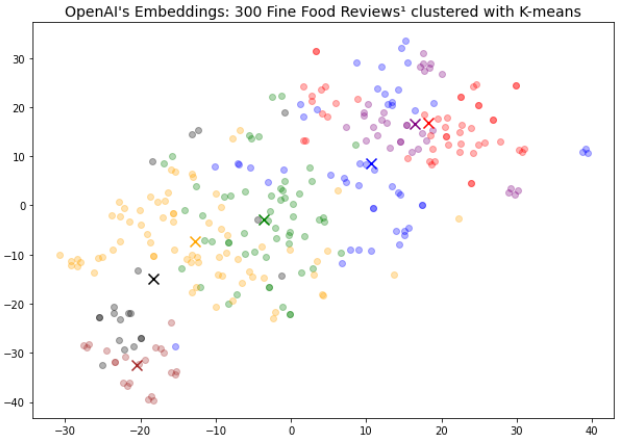
我可以使用t-SNE降维将评论绘制在2D空间中:
tsne = TSNE(n_components=2, perplexity=15, random_state=11, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
vis_dims.shape
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
fig, ax = plt.subplots(figsize=(10, 7))
for category, color in enumerate(["purple", "green", "red", "blue", "black", "orange", "brown"]):
xs = np.array(x)[df.Cluster == category]
ys = np.array(y)[df.Cluster == category]
ax.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
ax.scatter(avg_x, avg_y, marker="x", color=color, s=100)
ax.set_title("Clusters of Fine Food Reviews visualized 2d with K-means", fontsize=14)
plt.show()
得到的图表说明了评论中的聚类。
OpenAI的嵌入模型:使用K-means聚类的300个Fine Food Reviews¹
接下来,我根据共同主题总结了这些聚类,并打印了每个聚类的一些示例。
rev_per_cluster = 3
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response["choices"][0]["text"].replace("\n", ""))
sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])
print("-" * 100)
这些结果有助于找到主题,可以通过附带的评论快速验证:
Cluster 0 Theme: All reviews are positive.
5, 5 Star Tea at a super price!: This tea is very good and perfect for the price....you can't go wrong
5, Delish!!: So yummy... Drinking it Black coffee or w cream this coffee is delish
5, breakfast tea: We switch to this decaf tea at night for a great cup of tea and no sle
----------------------------------------------------------------------------------------------------
Cluster 1 Theme: The reviews have in common that the customers are happy with the product and the service.
5, Perfect Gift: I got these to give out in a goodie bag for the holidays, with a coupl
5, Awesome service and great products: We sent this product as a gift to my husband's daughter (who just grad
3, its delicious...: I was surprised at how delicious these toasted chips are. They ship we
----------------------------------------------------------------------------------------------------
Cluster 2 Theme: All reviews mention the quality of the coffee bean.
5, Jamaican Blue beans: Excellent coffee bean for roasting. Our family just purchased another
5, super coffee: Great coffee and so easy to brew. This coffee has great aroma and is
1, Steer Clear-not as described: I wanted to try different K cups and didnt want to buy entire boxes of
----------------------------------------------------------------------------------------------------
Cluster 3 Theme: All three reviews mention the product's flavor.
4, Delicious, but lid is cheap: I bought this syrup after reading the glowing reviews here. It is inde
5, More Like Pepsi: There is a lot of cola syrups trying to be Coke but this one is shooti
5, Awesome!!!: This flavor is the best ever!!! It tastes better than an orange Juliu
----------------------------------------------------------------------------------------------------
Cluster 4 Theme: All reviews mention that the product is made with ingredients from another country, and that this is a negative.
1, terrible treats: My dogs love them but they are loaded with junk and come from another
1, New Recipe is Awful: These used to be my favorite animal crackers but Austin has recently c
4, Great food!: I wanted a food for a a dog with skin problems. His skin greatly impro
----------------------------------------------------------------------------------------------------
Cluster 5 Theme: All reviews mention the product's good taste.
5, Rich cocoa taste and satisfying...: I like the convenience of protein bars for an on-the-go snack that fit
4, GOOD GLUTEN FREE BREAD STCK MIX: Makes very good break sticks.. Also can be used for a pizza crust.<br
5, Red Chili Fettuccinne: This product is great - looks, cooking time and taste. Have been usin
----------------------------------------------------------------------------------------------------
Cluster 6 Theme: All reviews mention that the customer's dog loves the product.
5, Favorite chew toy!: This is the second one of these antlers that I've ordered (the first o
5, Excellent Dog Food: My dog loves it and she absorbes it well. Her breath is fresh and her
5, my dogs love the peanut butter!: First off, read the ingredients, no crazy words I can't pronounce, whi
----------------------------------------------------------------------------------------------------
即使在NLP领域,聚类也不是一项新技术,但我无法强调OpenAI API的实用性。该模型是最先进的,这消除了只能接受较低质量的障碍。接下来,我将向向量数据库添加单词嵌入向量。
向量数据库
向量数据可以以许多方式存储,最简单的方式可能是CSV文件。然而,这可能不是一种适合长期使用的正确方法。向量数据库以浮点数的形式在可扩展和安全的方式中存储和检索向量数据。向量数据库将它们保存为数据库内部存储格式中的一系列位。
向量数据库能够有效地检索和存储文本嵌入向量。
OpenAI的嵌入模型将从12288降至1536。这是每个“文本嵌入”向量包含的浮点数的数量。这个变化显著降低了新嵌入模型的运营成本。
向量数据库服务的定价基于模型使用的向量数量。
- Pinecone的标准层从$0.0960⁵ / pod-hour开始(每个s1或p1-pod都可以容纳5M个768维向量)。它包括集合。
- Weavite的定价从每1M个向量维度的$0.050⁷起。
嵌入模型的维度直接影响向量数据库的成本。较低维度的向量更便宜。这一方面非常重要,因为解决方案会被扩展!
具有1536维向量数据库的Pinecone控制台
OpenAI嵌入向量的向量数据库
本教程将OpenAI的“单词嵌入”向量集成到商业向量数据库中。一些选项包括Faiss,Weavite,但在本教程中,我将使用Pinecone。Pinecone提供了一个免费计划,足以完成本教程。
第一步是创建Pinecone帐户并从你的Pinecone配置文件中获取API密钥和环境名称。之前,我已经安装了Pinecone包并导入了它,因此现在不需要再执行。所以,我可以直接定义我的登录参数:
pinecone.init(
api_key=os.getenv("PINECONE_API_KEY"),
environment="us-west1-gcp")
然后,我定义了我的模型维度和要用于向量的索引名称。在这种情况下,模型维度为1536,与嵌入模型维度匹配。然后,我检查一下是否已经存在具有这个索引名称的现有索引,并删除它,以便我可以创建一个新的索引。
index_name = 'fine-food-reviews-openai-embeddings'
dimensions = 1536
if index_name in pinecone.list_indexes():
pinecone.delete_index(index_name)
我使用余弦相似度创建了新的索引,因为它计算速度快:
pinecone.create_index(name=index_name, dimension=dimensions, metric="cosine")
然后,我可以从先前生成的df数据帧中插入OpenAI的文本嵌入。我需要定义索引名称,以便Pinecone知道将数据添加到哪个索引中。
meta= [{'combined': line} for line in df['combined']]
vectors = list(zip(df['ProductId'], df['ada_similarity'], meta))
upsert_response = index.upsert(
vectors=vectors,
namespace=index_name, values=True, include_metadata=True)
Pinecone接收了来自ada_similarity、ProductId和combined列的相似性分数。 “combined”列包括摘要和文本,作为元数据传递到向量数据库中。这些是存储数据所需的唯一步骤!
现在,我可以查询这个向量数据库。我传递一个查询文本,将其发送到OpenAI API以获取文本嵌入。向量浮点数保存为“query_response_embeddings”变量。
query = "I have ordered these raisins"
response = openai.Embedding.create(input=query, model='text-embedding-ada-002')
query_response_embeddings = response['data'][0]['embedding']
然后,我从向量数据库中查询此向量,指定要提供的响应数量。我还请求元数据。然后,我打印结果以及:
vector_database_results_matching = index.query([query_response_embeddings], top_k=5, include_metadata=True, include_Values=True,
namespace=index_name)
for match in vector_database_results_matching['matches']:
print(f"{match['score']:.2f}: {match['metadata']['combined']}")
这将根据文本相似度查询直接从向量数据库中查询的语义搜索结果。
0.88: Title: Delicious!; Content: I have ordered these raisins multiple times. They are always great and arrive timely. I can't go back to store bought chocolate covered raisins now! Love this product.
0.84: Title: Just what I expected!; Content: I bought these in order to make vanilla and kahlua for Christmas gifts. They were moist, yummy-smelling beans. If these experiments work, I'll be buying again for next year!
0.82: Title: its delicious...; Content: I was surprised at how delicious these toasted chips are. They ship well with little damage. I have ordered them several times. Also they are very fresh. Not one bit was left in the bag when I got through.
0.81: Title: Perfect Gift; Content: I got these to give out in a goodie bag for the holidays, with a couple extras of course. They arrived quickly, the price was right, and they were delicious! I can't wait to give them to all my friends!
0.81: Title: a great product and deal; Content: I looked at all of the reviews and shopped around locally before buying these. Locally the best deal I could find was $6 for 1 oz!!!!! I use them on my cereal, yogurt, granola and even in baking. They are yummy and very good for you. I shared one bag with my two health conscious kids and put the other bag in the freezer so I can dip into as needed. You will not regret buying these. I tried roasting some but prefer the nibs in their natural state. I plan to grind some up and try in place of cocoa powder in recipes.
结论
本教程从解释嵌入模型定价开始。我涵盖了上下文窗口、模型统一和较小的维度。我解释了如何使用嵌入端点进行实际的聚类活动。
然后,我介绍了向量数据库的概念及其由向量维度定义的定价。然后,我说明了向量数据库的用途,既用于存储,又用于文本搜索。# 参考文献
[1] Amazon Fine Food Reviews数据集. https://www.kaggle.com/datasets/snap/amazon-fine-food-reviews?resource=download. Kaggle.
[2] 新的和改进的嵌入模型. https://openai.com/blog/new-and-improved-embedding-model/. OpenAI.
[3] 什么是token以及如何计数它们?https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them. OpenAI.
[4] Tokens. https://docs.cohere.ai/docs/tokens. co:here.
[5] Pinecone价格. https://www.pinecone.io/pricing/. Pinecone.
[6] Thakur等,2021. BEIR:用于零样本评估信息检索模型的异构基准 https://openreview.net/forum?id=wCu6T5xFjeJ. OpenReview.net.
[7] Weavite价格。https://weaviate.io/pricing.html. Weavite.
译自:https://betterprogramming.pub/openais-embedding-model-with-vector-database-b69014f04433

评论(0)