
每个人都非常熟悉当前围绕大型语言模型(LLM)如GPT-3和图像生成模型如DALL-E 2和Stable Diffusion的炒作,但是这些模型的结果是有代价的。
- GPT-3:~ 1200万美元
- DALL-E:~ 50万-100万美元
- Stable Diffusion:~ 60万美元
这是由于处理和训练这些模型所需的大量GPU。除了成本外,要获得这些结果所需的标记数据量很难获取。以前,由于这两个因素,初创公司无法训练这种水平的模型,直到现在——由英特尔实验室、UKP实验室和Hugging Face团队推出的句子转换器微调(SetFit)是一种简单而有效的少量样本文本分类替代方法。
少量样本分类是一种NLP任务,其中模型旨在将文本分类到大量类别中,每个类别只有少量的训练示例。
与其他少量样本学习方法相比,SetFit具有几个独特的特点:
- 无提示: 大多数少量样本学习技术都需要手工制作提示,将示例转换为适合底层模型的格式,这也称为“提示工程”。SetFit不需要这样做,而是直接从少量标记示例生成丰富的嵌入。这极大地减少了标记数据的需求,并且不需要广泛的提示工程,这通常是GPT-3的最大缺点之一。
提示工程是将任务描述嵌入到输入中的过程,例如,作为问题而不是隐含地给出。
- 训练速度快: 由于数据需求较小,SetFit不需要大规模训练就可以达到与GPT-3(175b参数)相似(在某些情况下更好)的准确性。这将所需的训练时间降低了几个数量级。
- 多语言支持: SetFit可以与Hugging Face Hub上的任何句子转换器一起使用,这意味着你可以通过简单地微调多语言检查点来对多种语言的文本进行分类。
它是如何工作的
首先,你必须了解句子转换器是什么。这是一种流行的文本和图像嵌入方法,它基于其语义签名编码向量表示。嵌入是通过对比性训练建立的,这是一种自我监督学习形式,它增强了相同输入的视图。例如,“现在几点了?”在语义上与“已经多晚了?”相同。对比训练的目的是将语义相似的句子之间的距离最小化,并将语义差异的句子之间的距离最大化。Hugging Face上的模型库包含基于各种数据集的100多个预训练句子转换器。
SetFit的第一步是从模型库中选择一个句子转换器(ST)。选择任何ST来自模型库的能力是使SetFit具有多语言支持的原因,因为有超过100种语言的ST模型。然后,SetFit使用对比学习对句子转换器进行微调,其中正对是从同一类别中随机选择的两个句子,而负对是从不同类别中随机选择的两个句子。现在产生了一个适应的ST。
现在,训练数据中的句子使用适应的ST进行编码,从而创建句子嵌入。然后利用这些句子嵌入来创建一个简单的逻辑回归模型。在推断时,数据使用适应的ST进行编码,并使用训练好的逻辑回归模型进行分类。

SetFit的两阶段训练过程
基准测试
RAFT是一个少量样本分类基准测试,旨在通过将每个任务的训练样本数量限制为50个标记示例并不提供验证集来匹配现实世界的情况。

RAFT排行榜上的杰出方法
影响SetFit性能的突出特征包括:
- ST的类型:句子转换器模型库中有许多类型的ST,问题是如何为给定任务选择最佳ST。
- 输入数据选择:在一些RAFT任务中,提供了多个数据字段作为输入,例如标题、摘要、作者姓名、ID、数据等。这引发了一个问题:应该使用哪些数据字段作为输入,以及如何组合它们?
- 超参数的选择:如何选择最佳的微调超参数集(例如#epochs、生成迭代的句子对数量)?
训练和推理

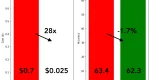
使用8个标记示例对T-Few 3B和SetFit(MPNet)进行训练成本和平均性能的比较
由于SetFit的小数据需求,它的训练速度非常快。 Hugging Face在培训方面报告了以下统计数据:
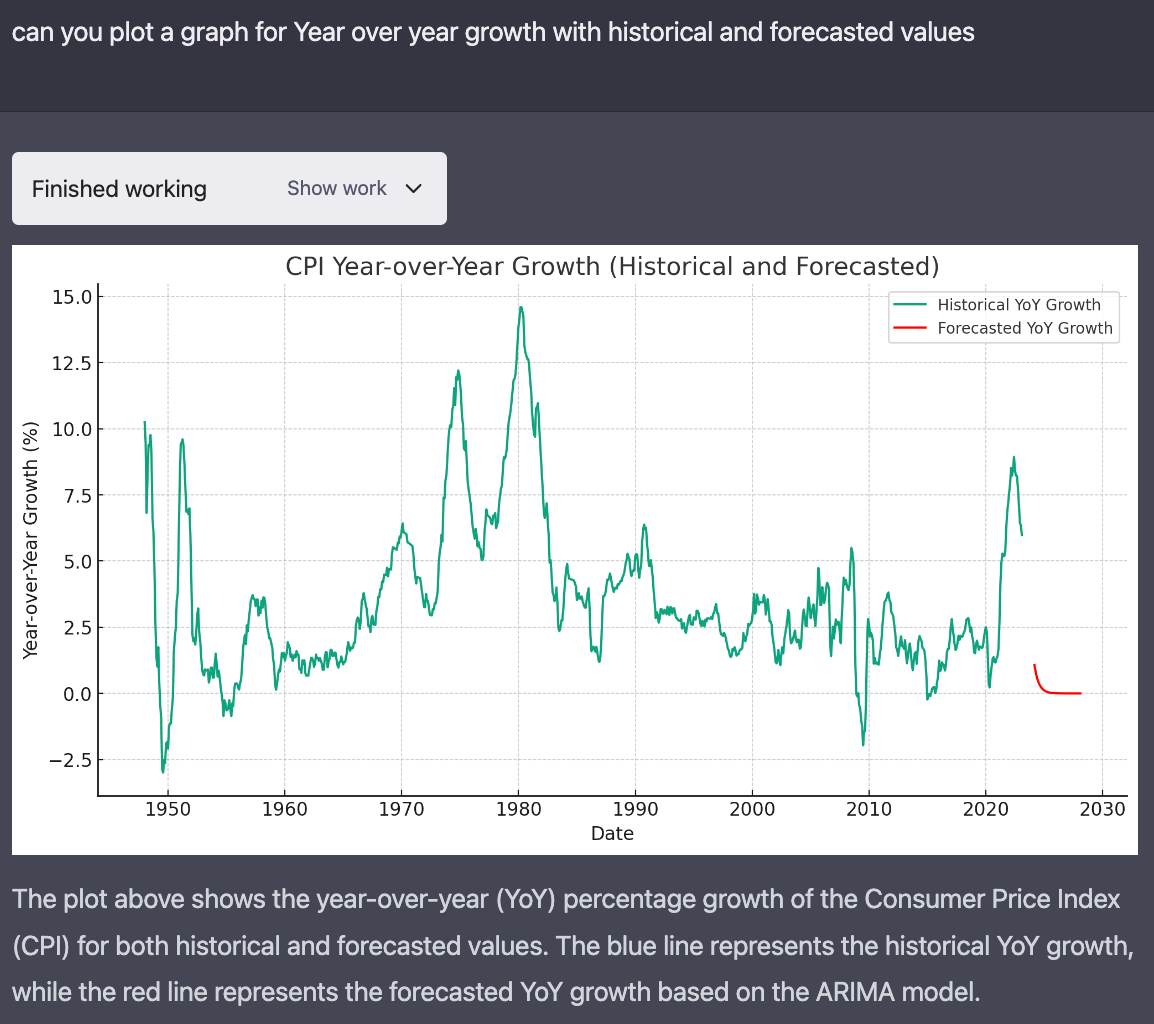
在NVIDIA V100上使用8个标记示例对SetFit进行训练只需要30秒,成本为0.025美元。相比之下,对T-Few 3B进行训练需要NVIDIA A100,并且在相同的实验中需要大约0.7美元的成本,这是28倍之多。实际上,SetFit可以在像Google Colab上找到的单个GPU上运行,甚至可以在几分钟内在CPU上训练SetFit!如上图所示,SetFit的加速带来了相似的模型性能。在 RAFT 评估中,SetFit 是一种极其有效的 few-shot 分类任务方法。它允许只有少量数据的企业以低廉的成本构建强大的文本分类器——这通常是限制初创公司实施这些解决方案的两个标准。如果你想学习如何微调自己的模型,可以在 Hugging Face 的这里查看简短的教程。否则,请与我们联系,我们将帮助你!
译自:https://blog.cerebrium.ai/setfit-outperforms-gpt-3-while-being-1600x-smaller-8b7b14e105f3












评论(0)