
Python长期以来一直是最受欢迎的编程语言之一。它有许多著名且常用的库,例如NumPy、Pandas和Matplotlib。但是,有几个Python库并不是很出名,但可以对一个人的编程职业生涯产生重大影响。在本文中,将探讨和使用2023年的10个这样的库。
PyGWalker: PyGWalker通过将pandas数据帧(和极地数据帧)转换为Tableau样式的用户界面,简化了Jupyter Notebook数据分析和数据可视化工作流程,以进行可视化探索。
import pandas as pd
import pygwalker as pyg
#https://www.kaggle.com/code/asmdef/pygwalker-test/notebook
df = pd.read_csv("hour.csv", parse_dates=['dteday'])
df.head()
pyg.walk(df)
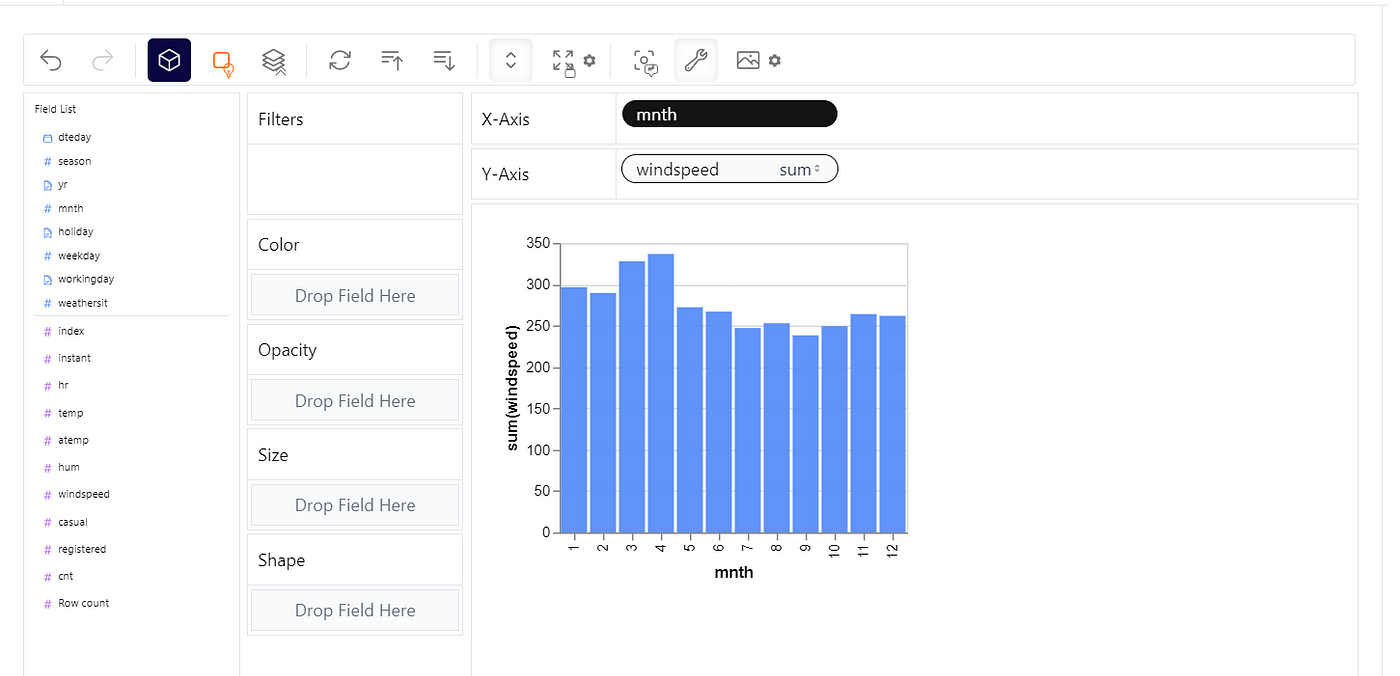
pandas中的Tableau样式界面
上面的图表显示了使用hour.csv Excel文件显示每个月风速总和的Tableau样式界面,就像在使用Tableau时看到的一样。当然,可以随时尝试其他X和Y轴参数。
SciencePlots: 为演示、研究论文等制作专业的matplotlib图表。
import matplotlib.pyplot as plt
import scienceplots as sp
plt.style.use(['fivethirtyeight','dark_background'])
with plt.style.context('seaborn-paper'):
plt.figure()
plt.plot(x, y)
plt.show()
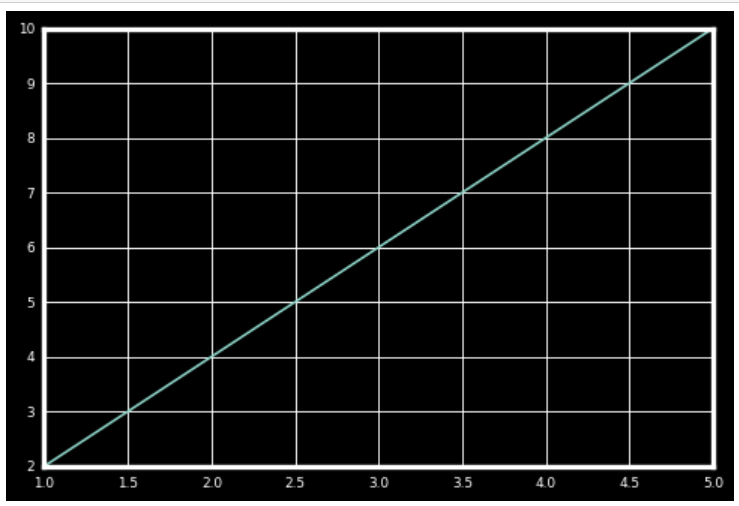
黑色背景图表中的线性关系
上面的代码使用了**“fivethirtyeight”和“dark_background”样式的组合。虽然最好找出已有样式列表**(使用下面的代码),否则由于缺少任何样式,代码可能会出现错误。
import matplotlib.pyplot as plt
import numpy as np
#plt.style.use(['science', 'notebook'])
plt.style.available
Output:
['Solarize_Light2',
'_classic_test_patch',
'_mpl-gallery',
'_mpl-gallery-nogrid',
'bmh',
'classic',
'dark_background',
'fast',
'fivethirtyeight',
'ggplot',
'grayscale',
'seaborn']
CleverCSV: 解决使用Pandas读取CSV文件时的解析错误。
import clevercsv
# Open CSV file and parse its contents
with open('hour.csv', 'r') as file:
csv_reader = clevercsv.reader(file, delimiter=',', quotechar='"')
for row in csv_reader:
print(row)
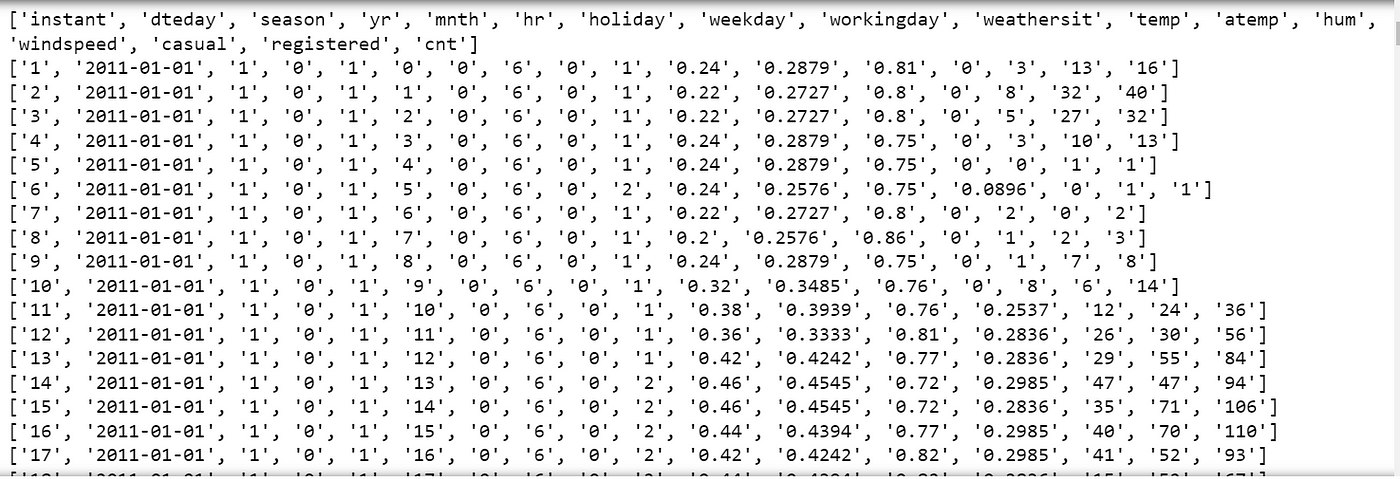
输出将每一行作为列表
在此示例中,使用clevercsv.reader()函数从上一个问题中读取名为**“hour.csv”的CSV文件。该函数接受几个参数,包括文件对象、分隔符字符(在本例中为逗号)和引号字符**(在本例中为双引号)。
由clevercsv.reader()返回的csv_reader对象可以被迭代,以检索CSV文件的每一行作为列表。在此示例中,每行都打印到控制台。
请注意,CleverCSV自动处理CSV文件的常见问题,例如不一致的字段分隔符或引号字符。这使得它成为处理混乱或格式不良的CSV文件的有用工具。
fastparquet: 将Pandas的parquet I/O加速5倍。
import pandas as pd
import fastparquet as fp
# Create a sample dataframe
data = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
df = pd.DataFrame(data)
# Write the dataframe to a Parquet file
fp.write('example.parquet', df)
# Read the Parquet file into a new dataframe
new_df = fp.ParquetFile('example.parquet').to_pandas()
# Print the new dataframe
print(new_df)
Output:
name age
0 Alice 25
1 Bob 30
2 Charlie 35
在此示例中,使用fastparquet库将pandas数据帧写入Parquet文件,然后将其读取回新数据帧中。fastparquet是Python中Parquet格式的高性能实现,旨在与Pandas数据帧无缝协作。它提供快速读写性能、高效压缩和对各种数据类型的支持。
nbcommands: 轻松搜索Jupyter笔记本中的代码,而不是手动查找。
https://nbcommands.readthedocs.io/en/latest/
Bottleneck: 加速NumPy方法25倍。如果数组具有NaN值,则特别好。
import bottleneck as bn
import numpy as np
# Create a 2D array of random values
arr = np.random.rand(1000, 10)
# Calculate the moving average of each row using bottleneck
moving_avg = bn.move_mean(arr, window=3, axis=1)
print(moving_avg)
Output:
[[ nan nan 0.28970504 ... 0.36931535 0.42605879 0.59029909]
[ nan nan 0.49734916 ... 0.47646434 0.62247903 0.59207834]
[ nan nan 0.61133785 ... 0.68879594 0.68071521 0.54268834]
...
[ nan nan 0.40336392 ... 0.71474823 0.7382253 0.50349293]
[ nan nan 0.63514901 ... 0.42061741 0.39216543 0.44065902]
[ nan nan 0.17439254 ... 0.59518532 0.68540443 0.64765793]]
在此代码中,将bottleneck库导入为bn。然后创建一个具有1000行和10列的2D NumPy数组,其值为随机值。
接下来,使用Bottleneck的move_mean函数来计算数组中每行的移动平均值。window参数指定每个移动平均值计算中要使用的值的数量,axis参数指定沿哪个轴计算移动平均值(在这种情况下,我们为每行计算它,因此设置axis=1)。
最后,打印出结果的移动平均值数组。这只是Bottleneck可以在Python代码中用来提高计算性能的示例之一。
multipledispatch: 启用Python中的函数重载。
from multipledispatch import dispatch
@dispatch(int, int)
def add(x, y):
return x + y
@dispatch(float, float)
def add(x, y):
return x + y
@dispatch(str, str)
def add(x, y):
return x + y
print(add(1, 2)) # Output: 3
print(add(1.0, 2.0)) # Output: 3.0
print(add("Hello, ", "World!")) # Output: Hello, World!
Output:
3
3.0
Hello, World!
在此示例中,定义了add函数,并有三个实现,每个实现采用不同的输入类型。使用@dispatch装饰器根据输入类型指定要使用的实现。当使用不同类型的参数调用add函数时,multipledispatch根据参数的类型签名自动选择正确的实现。这使得编写可处理多种类型输入的清晰且易读的代码变得容易。
Aquarel: 为matplotlib图表设置样式。
https://github.com/lgienapp/aquarel
modelstore: 版本化机器学习模型以实现更好的跟踪。
https://github.com/operatorai/modelstore
Pigeon: 在Jupyter笔记本中使用按钮点击注释数据。
from pigeon import annotate
import pandas as pd
# Define the options for the labels
options = ['Positive', 'Negative']
# Load your data
df = pd.read_csv('healthcare-dataset-stroke-data.csv')
# Annotate the data using Pigeon
annotations = annotate(df['stroke'], options=options)
# Save the annotations to a CSV file
annotations_df = pd.DataFrame(annotations, columns=['annotations'])
annotations_df.to_csv('annotations.csv', index=False)

根据是否**患中风(1)或不患中风(0)**注释类别在这个例子中,从 Pigeon 库 导入了 annotate 函数,为标签定义了选项,并从 .CSV 文件中加载数据。annotate 函数用于提示注释者使用定义的选项之一(Positive 或 Negative)标记每个类别(在本例中为“stroke”)数据集。最后,注释保存到 CSV 文件中。
从输出中可以观察到,已经注释了 7 个示例,还有 5103 个示例需要进行注释。
总之,Python 是一种功能强大且多才多艺的编程语言,拥有众多可供选择的库。虽然存在许多流行的库,但不应忽视那些可以提供 独特和有价值的功能 的不太知名的库。本文介绍的 10 个库只是 Python 生态系统中等待被发现的许多隐藏宝石中的一小部分。通过探索和尝试这些库,开发人员可以 扩展他们的工具箱并获得新的见解和能力,以帮助他们解决 最具挑战性的问题。
译自:https://python.plainenglish.io/10-hidden-python-libraries-programmers-must-use-in-2023-a26732562b1c


评论(0)