
在2017年,我们撰写了一篇关于我们如何存储数十亿条消息的博客文章。我们分享了我们的旅程,讲述了我们最初使用MongoDB,但迁移了数据到Cassandra,因为我们正在寻找一个可扩展、容错和相对低维护的数据库。我们知道我们会不断增长,而事实也确实如此! 我们希望拥有一个与我们一起成长的数据库,但希望它的维护需求不会随着存储需求的增长而增长。不幸的是,我们发现情况并非如此——我们的Cassandra集群出现了严重的性能问题,需要越来越多的努力来维持,而不是改进。 将近六年过去了,我们发生了很多变化,我们存储消息的方式也发生了变化。
我们的Cassandra问题
我们将消息存储在一个名为cassandra-messages的数据库中。顾名思义,它运行Cassandra,并且存储消息。在2017年,我们运行了12个Cassandra节点,存储了数十亿条消息。 到2022年初,这个集群已经有177个节点,存储了数万亿条消息。令我们烦恼的是,这是一个高度劳力密集型的系统——我们的值班团队经常因为数据库问题而被呼叫,延迟是不可预测的,而且我们不得不减少维护操作,因为这些操作变得过于昂贵。 是什么导致了这些问题?首先,让我们来看一下消息。
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
查看原始代码gistfile1.sql 由GitHub提供支持 ❤
上面的CQL语句是我们消息模式的一个最小版本。我们使用的每个ID都是Snowflake,使其具有按时间顺序排序的特性。我们通过发送消息的频道进行分区,以及一个静态的时间窗口(bucket)。这种分区意味着,在Cassandra中,所有给定频道和bucket的消息将被存储在一起,并在三个节点之间复制(或者你设置的复制因子)。 在这种分区方法中潜在的性能陷阱是:一个只有很少一群朋友的服务器发送的消息数量往往比有数十万用户的服务器要少得多。 在Cassandra中,读取的成本比写入高。写入会附加到提交日志并写入称为内存表的内存结构,最终刷新到磁盘上。然而,读取需要查询内存表和可能的多个SSTable(磁盘文件),这是一种更昂贵的操作。大量的并发读取会导致一个分区热点,我们形象地称之为“热分区”。我们的数据集的大小与这些访问模式相结合,导致我们的集群陷入困境。 当我们遇到热分区时,它经常影响整个数据库集群的延迟。一个频道和bucket的组合接收了大量的流量,节点的延迟会随着节点越来越努力地提供流量而逐渐增加。 其他对该节点的查询也受到影响,因为该节点无法跟上。由于我们使用四数一致性级别进行读取和写入,所有对提供热分区服务的节点的查询都会遭受延迟增加,从而导致更广泛的最终用户影响。 集群维护任务也经常引起麻烦。我们容易在压缩方面落后,其中Cassandra会为更高性能的读取在磁盘上压缩SSTable。我们的读取不仅变得更昂贵,而且我们还会看到级联的延迟,因为节点试图压缩。 我们经常执行一个我们称之为“流言蜚语之舞”的操作,我们会将一个节点从轮换中拿出来,让它在不接受流量的情况下进行压缩,然后将其重新引入以获取Cassandra的暗示传递提示,并不断重复,直到压缩积压为空为止。我们还花了大量时间来调整JVM的垃圾收集器和堆设置,因为垃圾收集暂停会导致显着的延迟波动。
改变我们的架构
我们的消息集群并不是我们唯一的Cassandra数据库。我们还有其他几个集群,每个集群都存在类似(尽管可能没有那么严
重)的故障。 在我们之前版本的这篇文章中,我们提到被ScyllaDB引发了兴趣,它是一个用C++编写的与Cassandra兼容的数据库。它承诺通过其每核心分片架构提供更好的性能、更快的修复、更强大的工作负载隔离,以及免于垃圾收集的生命周期,听起来相当吸引人。 尽管ScyllaDB绝对不是没有问题的,但由于它是用C++而不是Java编写的,它没有垃圾收集器。从历史上看,我们的团队在Cassandra上遇到了许多垃圾收集器的问题,从影响延迟的垃圾收集暂停,一直到连续超长的垃圾收集暂停,以至于操作员不得不手动重新启动和监视相关节点的健康状态。这些问题是我们的值班工作的重要来源,也是我们消息集群内许多稳定性问题的根源。 在与ScyllaDB进行实验并观察测试中的改进后,我们决定迁移我们的所有数据库。尽管这个决定本身可能成为一篇博文,但简短的版本是,到2020年,除了一个之外,我们已经将所有数据库迁移到了ScyllaDB。 最后一个呢?我们的朋友,cassandra-messages。 为什么我们还没有迁移呢?首先,它是一个庞大的集群。有数万亿条消息和近200个节点,任何迁移都会是一项复杂的工作。此外,我们希望确保我们的新数据库在性能调优的过程中能够达到最佳状态。我们还希望在生产中获得更多关于ScyllaDB的经验,愿意愤怒地使用它并了解它的缺陷。 我们还努力改善ScyllaDB在我们的用例中的性能。在我们的测试中,我们发现反向查询的性能不足以满足我们的需求。当我们尝试以与表排序相反的顺序扫描数据库时,我们执行反向查询,比如以升序扫描消息。ScyllaDB团队优先进行了改进,并实现了高性能的反向查询,消除了我们迁移计划中的最后一个数据库障碍。 我们怀疑仅仅在我们的系统上添加一个新的数据库不会使一切变得神奇。ScyllaDB中仍然可能出现热分区,因此我们还希望在数据库上游投资,以帮助屏蔽和促进更好的数据库性能。
数据服务提供数据
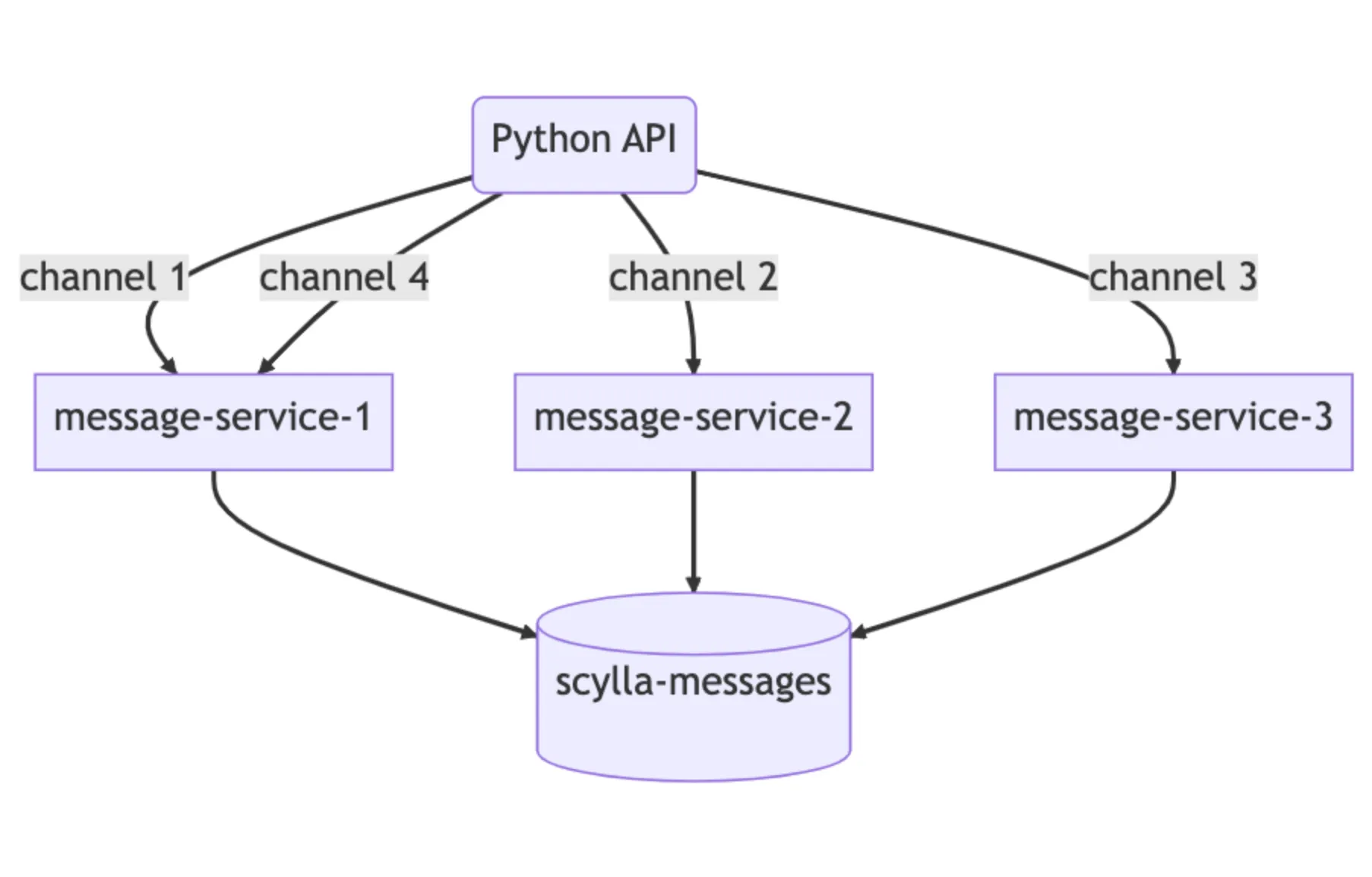
在Cassandra中,我们遇到了热分区问题。对给定分区的高流量导致无限并发,从而导致级联的延迟,随后的查询将继续增加延迟。如果我们能够控制对热分区的并发流量,我们就可以保护数据库免受过载。
为了完成这项任务,我们编写了我们所称的数据服务——位于API巨兽和数据库集群之间的中间服务。在编写数据服务时,我们选择了一种我们在Discord上越来越多地使用的语言:Rust!我们以前在几个项目中使用过它,并且它实际上达到了我们的预期。它为我们提供了快速的C/C++速度,而不必牺牲安全性。
Rust以无畏并发性为其主要优点之一——这门语言应该能够轻松编写安全的并发代码。它的库也非常适合我们计划实现的目标。Tokio生态系统是构建基于异步I/O的系统的巨大基础,而该语言对Cassandra和ScyllaDB都有驱动程序支持。
此外,我们发现使用编译器的帮助、错误消息的清晰度、语言结构以及对安全性的强调让我们在其中编写代码时感到非常愉快。我们对于一旦编译成功,它通常就能正常工作的特性非常喜爱。然而,最重要的是,它让我们能够说我们将其重新编写为Rust(模因信用非常重要)。
我们的数据服务位于API和我们的ScyllaDB集群之间。它们大致包含每个数据库查询一个gRPC端点,并且故意不包含业务逻辑。我们的数据服务提供的重要特性是请求合并。如果多个用户同时请求相同的行,我们只会查询数据库一次。第一个发出请求的用户会在服务中启动一个工作任务。随后的请求将检查该任务的存在并订阅它。该工作任务将查询数据库并将行返回给所有订阅者。
这就是Rust的威力:它使编写安全的并发代码变得容易。
假设在一个大型服务器上进行了一个通知@everyone的重要公告:用户将打开应用程序并
阅读消息,从而向数据库发送大量流量。以前,这可能会导致热分区,值班人员可能需要被呼叫以帮助系统恢复。通过我们的数据服务,我们能够显著减少对数据库的流量峰值。
这里的第二部分魔力位于我们的数据服务的上游。我们实施了基于一致性哈希的路由到我们的数据服务,以实现更有效的合并。对于我们数据服务的每个请求,我们都会提供一个路由密钥。对于消息来说,这是一个频道ID,因此所有对相同频道的请求都会发送到服务的同一个实例。这种路由进一步有助于减轻我们的数据库负载。
 这些改进确实有很大帮助,但并不解决我们所有的问题。我们仍然看到Cassandra集群上的热分区和延迟增加,只是不那么频繁了。这为我们争取了一些时间,以便我们可以准备好我们的新的最佳ScyllaDB集群并执行迁移。
这些改进确实有很大帮助,但并不解决我们所有的问题。我们仍然看到Cassandra集群上的热分区和延迟增加,只是不那么频繁了。这为我们争取了一些时间,以便我们可以准备好我们的新的最佳ScyllaDB集群并执行迁移。
一个非常大的迁移
我们对迁移的要求非常简单:我们需要在没有停机的情况下迁移数万亿条消息,而且需要迅速完成,因为虽然Cassandra的情况有所改善,但我们经常需要进行应急处理。 第一步很容易:我们使用我们的超级磁盘存储拓扑配置一个新的ScyllaDB集群。通过使用本地SSD以提高速度,并利用RAID将数据镜像到持久磁盘上,我们既获得了附加本地磁盘的速度,又获得了持久磁盘的耐久性。在集群建立起来后,我们可以开始将数据迁移到其中。 我们迁移计划的第一个草案旨在快速获得价值。我们将从使用闪亮的新ScyllaDB集群开始处理新数据,使用一个切换时间,然后在其后面迁移历史数据。这增加了更多的复杂性,但每个大项目都需要额外的复杂性,对吗? 我们开始将新数据同时写入Cassandra和ScyllaDB,并同时开始准备ScyllaDB的Spark迁移工具。它需要进行大量的调整,一旦我们将其设置好,我们就有了一个预计的完成时间:三个月。 这个时间表让我们感到不安和紧张,我们更希望能够更快地获得价值。我们作为一个团队坐下来,构思了加快速度的方法,直到我们想起来我们已经写了一个快速且高性能的数据库库,我们可以在此基础上进行扩展。我们决定进行一些以模因为驱动的工程,并用Rust重新编写数据迁移工具。 在一个下午,我们扩展了我们的数据服务库以执行大规模的数据迁移。它从数据库读取标记范围,通过SQLite在本地进行检查点,并将其传输到ScyllaDB中。我们连接了我们的新的和改进的迁移工具,并获得了一个新的估计时间:九天!如果我们能够如此快速地迁移数据,那么我们可以忘记我们复杂的基于时间的方法,而是立即切换到所有内容。 我们打开它并让它运行,以每秒高达320万条的速度迁移消息。几天后,我们聚集在一起观察它达到100%,然后我们意识到它卡在了99.9999%(真的)。我们的迁移工具在读取最后几个标记范围的数据时超时,因为它们包含从未在Cassandra中紧缩的巨大范围的墓碑。我们压缩了该标记范围,几秒钟后,迁移完成! 我们通过向两个数据库发送少量读取请求并比较结果来执行自动数据验证,一切看起来都很不错。集群在完整的生产流量下表现良好,而Cassandra则面临越来越频繁的延迟问题。我们聚集在一起,将ScyllaDB设置为主要数据库,并举行了庆祝活动!
几个月后…
我们
的Cassandra集群已经退役了,曾经存在的问题也已成为历史。而ScyllaDB表现得非常出色,我们一直在持续进行性能调优以获得更好的结果。我们现在可以更好地管理我们的数据库,而不必担心Cassandra集群的不稳定性和延迟问题。 这是一个巨大的胜利,是我们许多人的一项重要工作。我们非常自豪地以Rust编写了一项如此关键的服务,它使我们能够充分利用ScyllaDB的强大功能。我们展示了团队合作和持续改进的精神,为我们的用户提供了更好的体验。 作为一个不断发展的技术公司,我们知道这只是旅程的一部分。我们将继续学习,继续挑战自己,以便为我们的用户提供最好的服务。我们很高兴能与你分享我们的故事,并希望它能为你提供一些洞察力! 译自:https://discord.com/blog/how-discord-stores-trillions-of-messages


评论(0)