
我们生活在一个不确定的世界中。在云中,网络连接和第三方服务不稳定是很常见的。例如,网络中可能会有数据包丢失或限速器,这可能会导致请求失败。
在构建云原生服务时,使用重试模式是一个好的实践,这样我们就可以设计我们的应用程序,以便平稳地处理这些故障并继续有效地运行。
重试模式
这里的名字是不言自明的。我们重试一个操作(函数调用、网络请求等),直到它成功或我们达到最大重试次数。
我们可以将重试操作抽象为一个函数,它以另一个函数作为参数:
type Retriable func(context.Context) error
func Retry(ctx context.Context, maxRetries uint, waitFor time.Duration, f Retriable) error
这里,Retriable是一个函数类型,它以Context为参数并返回一个error。这个想法是,如果返回的错误是nil,那么函数就成功了,我们可以从Retry返回。如果不是,则意味着函数无法执行,我们需要重试它。
我们使用maxRetries参数来确保不会无限调用给定的函数。而waitFor则指定了连续重试之间的等待时间。
让我们实现Retry函数:
func Retry(ctx context.Context, maxRetries uint, waitFor time.Duration, f Retriable) error {
for trial := uint(0); ; trial++ {
if trial >= maxRetries {
return errors.New("maximum number of trials reached")
}
err := f(ctx)
if err == nil {
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(waitFor):
}
}
}
实现非常简单,我们尝试最多maxRetries次的函数f,并等待waitFor的等待间隔。
如果你不熟悉Go通道,那么选择-情况部分可能很难理解。这里,我们正在尝试从ctx.Done()返回的通道中接收,该通道表示通道是否被取消。如果没有,则该情况不适用,我们将移动到下一个情况,即time.After(duration)。此函数返回一个通道,该通道将在调用它后duration纳秒后填充。因此,基本上我们等待duration纳秒,然后继续进行循环。
让我们使用一个在一些调用中暂时失败的函数来使用Retry...
package main
import (
"context"
"errors"
"log"
"time"
)
func NewRetriableTransientError() Retriable {
var count int
return func(_ context.Context) error {
if count < 3 {
count++
return errors.New("fake retriable failed!")
}
return nil
}
}
func main() {
ctx := context.Background()
f := NewRetriableTransientError()
err := Retry(ctx, 5, time.Second, f)
if err != nil {
log.Panic("Retry failed: %v", err)
}
log.Printf("OK!")
}
...并运行它:
$ go run main.go
2009/11/10 23:00:03 OK!
很好!
退避
现在让我们考虑一个情况:我们正在多个部署上使用此重试实现来向同一服务器发送HTTP请求。如果服务器有速率限制器,并且我们的重试等待持续时间相对较短,那么我们的工作人员将被限制速率一段时间。
我们可以通过增加等待持续时间来轻松绕过此问题。但是,如果相关服务由于短暂错误而处于停机状态,则这将增加重新尝试函数的总返回时间。
如果我们在重试期间增加等待时间会怎样呢?这引入了退避机制。使用退避,我们使用算法增加重试之间的等待持续时间。最受欢迎的是线性退避和指数退避。
在线性退避中,我们使用试验号计算等待时间,并具有线性关系。在指数退避中,持续时间是通过使用常数基数和指数作为试验号来计算的。在指数退避中,基数通常为2,因此被称为二进制指数退避。
最好将退避持续时间限制在某个范围内。否则,如果最大重试限制足够高,我们可以永远等待失败的服务。
让我们在Go中将退避策略定义为一个函数:
type BackoffStrategy func(trial uint) time.Duration
func NewLinearBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(trial+1))
if d > cap {
d = cap
}
return d
}
}
func NewBinaryExponentialBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(1<<trial))
if d > cap {
d = cap
}
return d
}
}
在线性退避中,我们等待backoff * trial纳秒,在指数退避中,我们等待backoff * 2 ^ trial纳秒,因为我们使用2作为基数。
我们可以在Retry函数内部轻松使用此退避:
func Retry(ctx context.Context, maxRetries uint, backoff BackoffStrategy, f Retriable) error {
for trial := uint(0); ; trial++ {
if trial >= maxRetries {
return errors.New("maximum number of trials reached")
}
err := f(ctx)
if err == nil {
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(backoff(trial)):
}
}
}
请注意,我们已在select-case内使用time.After()等待从backoff(trial)返回的持续时间。
抖动
现在我们已将退避添加到我们的重试实现中,让我们再次考虑具有多个工作人员的情况。假设我们使用了二进制指数退避,现在,长时间等待的速率限制问题已得到解决。但是,我们将向服务发送同步请求。
该服务的请求数/秒图表(仅限我们的请求)如下所示:
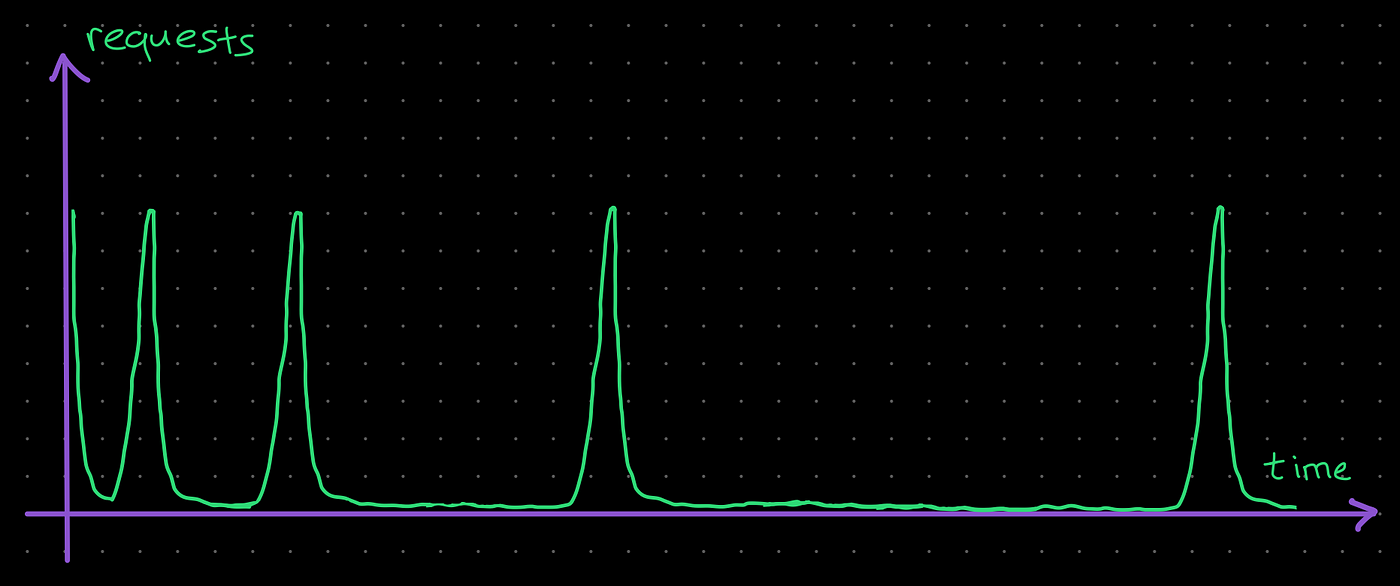
拥有太多具有相同重试计划的工作人员并不是我们想要的,特别是如果我们不试图对远程服务执行DOS攻击。最好为每个工作人员的重试计划引入一些随机性以扩散这些峰值。这种随机性称为“抖动”。
让我们将抖动添加到NewLinearBackoff和NewBinaryExponentialBackoff中:
func NewLinearBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(trial+1))
if d > cap {
return cap
}
dMax := time.Duration(backoff.Nanoseconds() * int64(trial+2))
return time.Duration(randRange(d.Nanoseconds(), dMax.Nanoseconds()))
}
}
func NewBinaryExponentialBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(1<<trial))
if d > cap {
return cap
}
dMax := time.Duration(backoff.Nanoseconds() * int64(1<<(trial+1)))
return time.Duration(randRange(d.Nanoseconds(), dMax.Nanoseconds()))
}
}
func randRange(min int64, max int64) int64 {
rand.Seed(time.Now().UnixNano())
return rand.Int63n(max-min+1) + min
}
进行此更新后,每秒请求数图表将如下所示:

结论
总之,在构建云原生服务时,使用重试模式以处理短暂故障是一个好的实践。此外,退避和抖动算法可以提高重试操作的鲁棒性并防止压倒远程服务。
译自:https://betterprogramming.pub/cloud-native-patterns-illustrated-retry-pattern-c13ba0aa9486










评论(0)