
缺失数据是指在数据集中对于感兴趣的变量没有存储数据。根据其数量,缺失数据可能会影响任何数据分析的结果或机器学习模型的稳健性。
在使用Python处理缺失数据时,可以使用Pandas中的dropna()函数。我们可以使用它来删除包含空值的行和列。它还具有几个参数,例如axis用于定义是删除行还是列,how用于确定是否在任何行/列中发生缺失值,subset用于选择要应用删除函数的一组列或标签。
df.dropna(axis=0, how='any', subset=None, inplace=False)
然而,还有其他可能更好的方法来处理缺失数据。在本文中,我们将看到如何使用简单和高级技术进行缺失数据的插补(替换)。首先,我们将介绍简单的单变量技术,例如均值和模式插补。然后,我们将看到时间序列数据的前向和后向填充,我们将探索线性、多项式或二次插值等插值方法以填充缺失值。之后,我们将探索高级多变量技术,并学习如何使用KNN和MICE进行机器学习来插补缺失值。
在阅读本文时,我鼓励你查看我的GitHub上的Jupyter Notebook,以获取完整的分析和代码。
坚定不移,让我们开始吧!🦾
数据
在本文中,我们将使用来自OpenMV.net的旅行时间数据集。使用以下代码,我们将通过解析Date和StartTime列并将随机值转换为MaxSpeed列的缺失值来加载数据。
# Read the original dataset
df = pd.read_csv('travel-times.csv', parse_dates=[['Date', 'StartTime']], index_col='Date_StartTime')
# Generate random missing values on column MaxSpeed
mask = np.random.choice([True, False], size=df['MaxSpeed'].shape, p=[0.1, 0.9])
mask[mask.all(),-1] = 0
df['MaxSpeed'] = df['MaxSpeed'].mask(mask)
让我们打印数据的前5行:

数据的前五行
检测缺失值
我们可以使用isna()或isnull()方法检测数据中的缺失值。我们可以使用sum()获取每列中缺失值的总数,或使用mean()获取平均数。
df.isnull().sum()
DayOfWeek: 0
GoingTo: 0
Distance: 0
MaxSpeed: 22
AvgSpeed: 0
AvgMovingSpeed: 0
FuelEconomy: 17
TotalTime: 0
MovingTime: 0
Take407All: 0
Comments: 181
df.isnull().mean()*100
DayOfWeek: 0.00%
GoingTo: 0.00%
Distance: 0.00%
MaxSpeed: 10.73%
AvgSpeed: 0.00%
AvgMovingSpeed: 0.00%
FuelEconomy: 8.29%
TotalTime: 0.00%
MovingTime: 0.00%
Take407All: 0.00%
Comments: 88.29%
由于我们随机替换了MaxSpeed列中10%的值为np.nan,因此它具有约10%的缺失值。
我们还可以使用missingno包在数据中生成缺失值的可视化表示。如果你正在尝试检测缺失值之间的关系,例如与其他列一起缺失或在特定周、月等期间缺失,则这是一个非常有用的工具。
在下面的矩阵视图中,我们可以看到缺失值的空白行和不缺失值的黑色行。正如我们预期的那样,我们的缺失值在MaxSpeed列中是随机的。
import missingno as msno
msno.matrix(df)

使用missingno生成的缺失值
1.基本插补技术
1.1. 均值和模式插补
我们可以使用scikit-learn中的SimpleImputer函数将缺失值替换为填充值。SimpleImputer函数有一个名为strategy的参数,它提供了四种选择来选择插补方法:
strategy='mean'使用列的平均值替换缺失值。strategy='median'使用列的中位数替换缺失值。strategy='most_frequent'使用列的最频繁(或模式)替换缺失值。strategy='constant'使用定义的填充值替换缺失值。
下面我们将在具有10%随机缺失值的MaxSpeed列上使用SimpleImputer转换器。我们首先定义strategy=mean的平均值插补器,然后对该列应用fit_transform。
# Mean Imputation
df_mean = df.copy()
mean_imputer = SimpleImputer(strategy='mean')
df_mean['MaxSpeed'] = mean_imputer.fit_transform(df_mean['MaxSpeed'].values.reshape(-1,1))
让我们绘制一个散点图,x轴为AvgSpeed,y轴为MaxSpeed。由于我们知道AvgSpeed列没有缺失值,并且我们将MaxSpeed列中的缺失值替换为列的平均值。在下面的图中,绿色点是转换后的数据,蓝色点是原始的非缺失数据。
# Scatter plot
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_mean.plot(x="AvgSpeed", y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='Mean Imputation', colorbar=False)
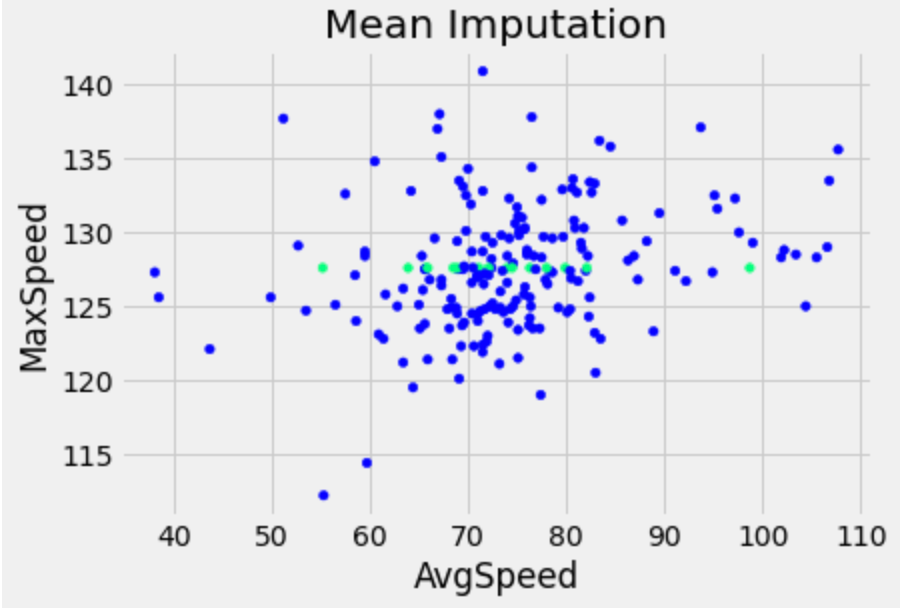
绿色点表示使用最大速度的平均值(约127)进行插补的数据点。
我们也可以使用中位数、最频繁值或常量值重复相同的操作。🌀这是使用最频繁值(mode)进行插补的示例。
# Mode Imputation
df_mode = df.copy()
mode_imputer = SimpleImputer(strategy='most_frequent')
df_mode['MaxSpeed'] = mode_imputer.fit_transform(df_mode['MaxSpeed'].values.reshape(-1,1))
# Scatter plot
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_mode.plot(x='AvgSpeed', y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='Mode Imputation', colorbar=False)

绿色点表示使用最小最频繁值(约124)进行插补的数据点。
注意:如果存在多个众数,则插补使用最小众数。
然而,均值插补可能会偏差标准误差,如果值不是随机缺失的,则也可能会偏差列的实际均值/众数。根据缺失量的大小,这种方式的插补也会影响列之间的真实关系。如果该列有许多离群值,则中位数插补应优于均值插补。
1.2. 时间序列插补
在加载数据集时,我们使用日期和开始时间列的组合定义了索引,如果不清楚,请参见上面的_数据_部分。☝️
在时间序列数据中插补缺失值的一种方法是使用前一个或下一个观察值进行填充。Pandas 有一个 fillna() 函数,其中有一个 method 参数,我们可以选择使用 “ffill” 来使用下一个观察值进行填充,或使用 “bfill” 来使用先前的观察值进行填充。
下面的图显示了按时间显示的 MaxSpeed 列的前 100 个数据点。
df['MaxSpeed'][:100].plot(title="MaxSpeed", marker="o")
这里可以看到缺失值。
如果我们想要使用下一个观察值填充缺失值,则应使用 method=“ffill”。
# Ffill imputation
ffill_imputation = df.fillna(method='ffill')
# Plot imputed data
ffill_imp['MaxSpeed'][:100].plot(color='red', marker='o', linestyle='dotted')
df['MaxSpeed'][:100].plot(title='MaxSpeed', marker='o')

缺失值已使用下一个观察值填充
如果我们想要使用先前的观察值填充缺失值,则应使用 method=“bfill”。
# Bfill imputation
bfill_imputation = df.fillna(method='bfill')
# Plot imputed data
bfill_imp['MaxSpeed'][:100].plot(color='red', marker='o', linestyle='dotted')
df['MaxSpeed'][:100].plot(title='MaxSpeed', marker='o')
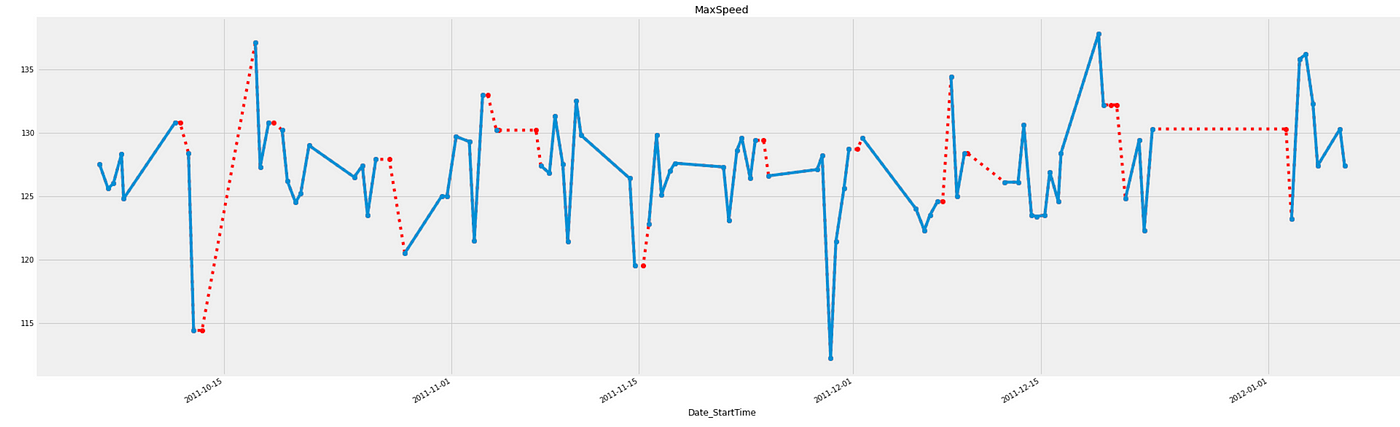
缺失值已使用先前的观察值填充
除了 bfill 和 ffill,我们还可以使用 Pandas 中的 interpolate() 函数,并选择 method=“linear” 来使用前一个和下一个观察值之间的递增顺序填充缺失值。需要注意的是,该函数将值视为等间距分布,忽略索引。
# Imputing with linear interpolation
linear_interpolation = df.interpolate(method='linear')
# Plot imputed data
linear_int['MaxSpeed'][:100].plot(color='red', marker='o', linestyle='dotted')
df['MaxSpeed'][:100].plot(title='MaxSpeed', marker='o')
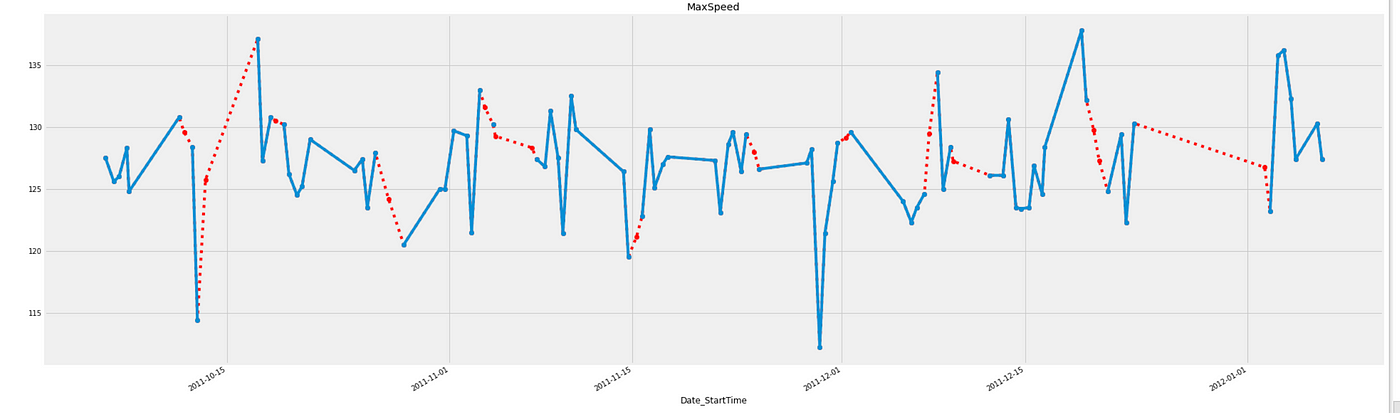
缺失值已使用线性插值填充
除了 linear 插值方法,我们还可以选择 polynomial、spline、nearest、quadratic 等。如果你对插值技术感兴趣,请查看 Pandas 文档。
2. 高级技术
2.1. K-最近邻(KNN)插补
一种替代插补缺失值的方法是预测它们。最近邻插补广泛使用并被证明是一种有效的缺失值插补方法。
我们可以使用 Scikit-learn 中的 KNNImputer ,其中缺失值使用在训练集中找到的 K- 最近邻的平均值进行插补。
from sklearn.impute import KNNImputerKNNImputer(missing_values=np.nan, n_neighbors=5, weights='uniform', metric='nan_euclidean')
KNNImputer 有几个参数,例如默认设置为 np.nan 的 missing_values,默认设置为 5 的用于插补的相邻样本数量的 n_neighbors,默认设置为“nan-euclidean”的用于搜索邻居的距离度量的 metric,但也可以使用用户定义的函数定义。
KNNImputer 可以处理连续、离散和分类数据类型,但无法处理文本数据。因此,我使用了选定的列子集 —— Distance、MaxSpeed、AvgSpeed 和 AvgMoovingSpeed 进行数据筛选。此外,我使用了 scikit-learn 中的 MinMaxScaler 将这些数值数据归一化到 0 到 1 之间。由于 KNNImputer 是一种基于距离的算法,因此缩放是管道中的重要步骤。
# Imputing with KNNImputer
from sklearn.impute import KNNImputer
from sklearn.preprocessing import MinMaxScaler
#Define a subset of the dataset
df_knn = df.filter(['Distance','MaxSpeed','AvgSpeed','AvgMovingSpeed'], axis=1).copy()
# Define scaler to set values between 0 and 1
scaler = MinMaxScaler(feature_range=(0, 1))
df_knn = pd.DataFrame(scaler.fit_transform(df_knn), columns = df_knn.columns)
# Define KNN imputer and fill missing values
knn_imputer = KNNImputer(n_neighbors=5, weights='uniform', metric='nan_euclidean')
df_knn_imputed = pd.DataFrame(knn_imputer.fit_transform(df_knn), columns=df_knn.columns)
在定义 KNNImputer 后,我们使用 fit_transform 保存新的(插补的)数据。下面是散点图,显示了插补后的数据与原始数据,绿色表示 MaxSpeed 的插补值。
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_knn_imputed.plot(x='AvgSpeed', y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='KNN Imputation', colorbar=False)
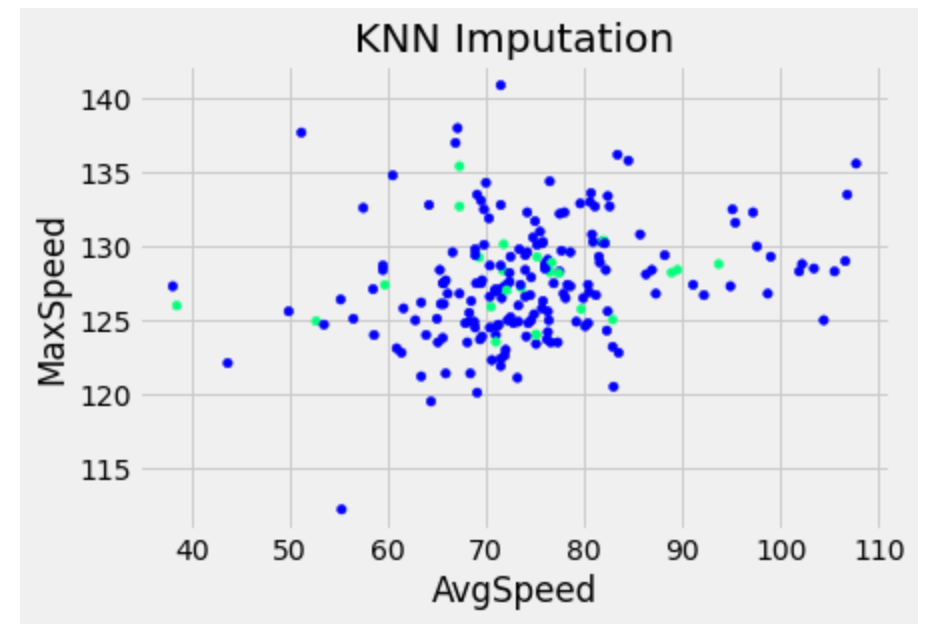
绿色点表示使用 KNN 插补进行插补的数据点
KNNImputer 具有许多优点,例如易于实现以及能够同时处理数值和分类数据类型。但是,定义邻居数 k 可能很棘手,因为它引入了鲁棒性和速度之间的折衷。如果选择小的 k,则计算速度快但结果不够稳健。相反,如果选择大的 k,则计算速度慢但结果更加稳健。
2.2. 多元插补方程 —— MICE
MICE 算法可能是最常用的插补技术之一,也是一个流行的面试问题。😈
MICE首先计算每个存在缺失值的列的均值,并将其作为占位符。然后,它运行一系列回归模型(链式方程)来顺序地填充每个缺失值。与任何回归模型一样,MICE使用特征矩阵和目标变量进行训练,而在这种情况下,目标变量是存在缺失值的列。 MICE预测并更新目标列上的缺失值。迭代地,MICE通过不断地使用来自先前迭代的预测来更改占位符变量来多次重复此过程。最终,它达到了稳健的估计。
要应用MICE算法,我们将使用scikit-learn中的IterativeImputer。由于这个估计器仍处于实验阶段,因此我们必须导入enable_iterative_imputer。
IterativeImputer(estimator=None, missing_values=np.nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy=’mean’, imputation_order=’ascending’)
# Imputing with MICE
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn import linear_model
df_mice = df.filter(['Distance','MaxSpeed','AvgSpeed','AvgMovingSpeed'], axis=1).copy()
# Define MICE Imputer and fill missing values
mice_imputer = IterativeImputer(estimator=linear_model.BayesianRidge(), n_nearest_features=None, imputation_order='ascending')
df_mice_imputed = pd.DataFrame(mice_imputer.fit_transform(df_mice), columns=df_mice.columns)
下面是填充后数据与原始数据的散点图。
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_mice_imputed.plot(x='AvgSpeed', y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='MICE Imputation', colorbar=False)
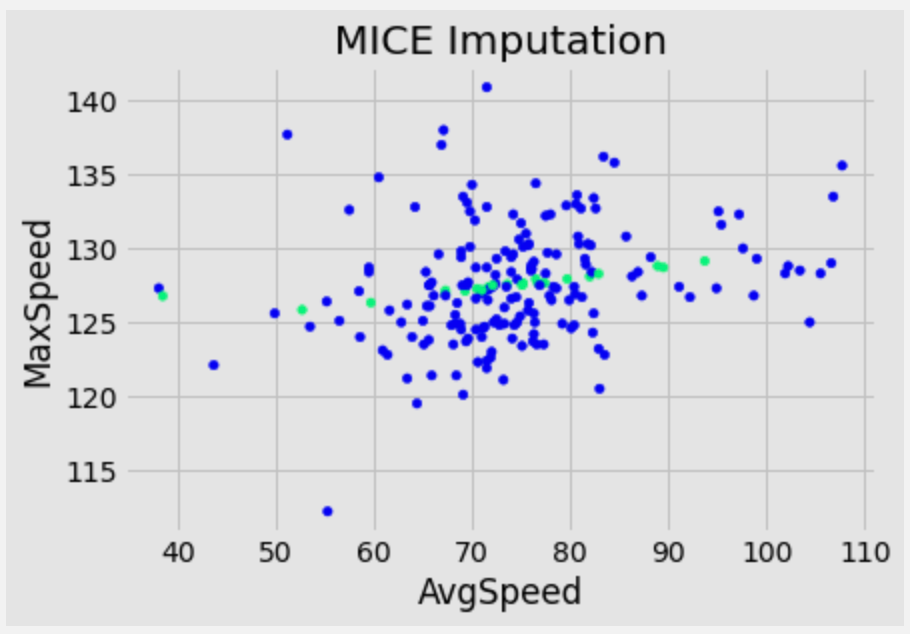
绿色表示使用MICE填充的数据点。
结论
在本文中,我们探讨了在数据集中填充缺失值的不同方法。我们首先使用missingno包检测缺失数据。然后,我们使用简单的填充器使用缺失数据列的平均值和最常见值。由于我们数据中存在时间元素,我们还讨论了使用时间序列进行向后填充、向前填充和线性插值来填充缺失值。最后,我们转向了更高级的技术;K-最近邻插补(KNN)和多元插补链式方程(MICE),它们使用机器学习来填充缺失值。
参考文献
- 旅行时间数据集:©Kevin Dunn,learnche.org
- 页眉照片由Alessio Roversi提供,来自Unsplash
- 所有其他图片均由作者提供


评论(0)