
如果你刚开始学习深度学习,可能会很难理解Transformer架构(我有亲身经历)。
我还没有看到(至少目前为止)一个易于理解的Transformer解释。大多数解释都假设你有很好的深度学习背景,并且他们会陷入一些对于架构并不重要的细节。
我会尝试给出关于Transformer如何以及为什么成为一种很好的架构的最基本的解释。
为此,我将展示Transformer的一种变体:极简Transformer。你只需要了解神经网络的基础知识和一些基本的线性代数就可以理解它。
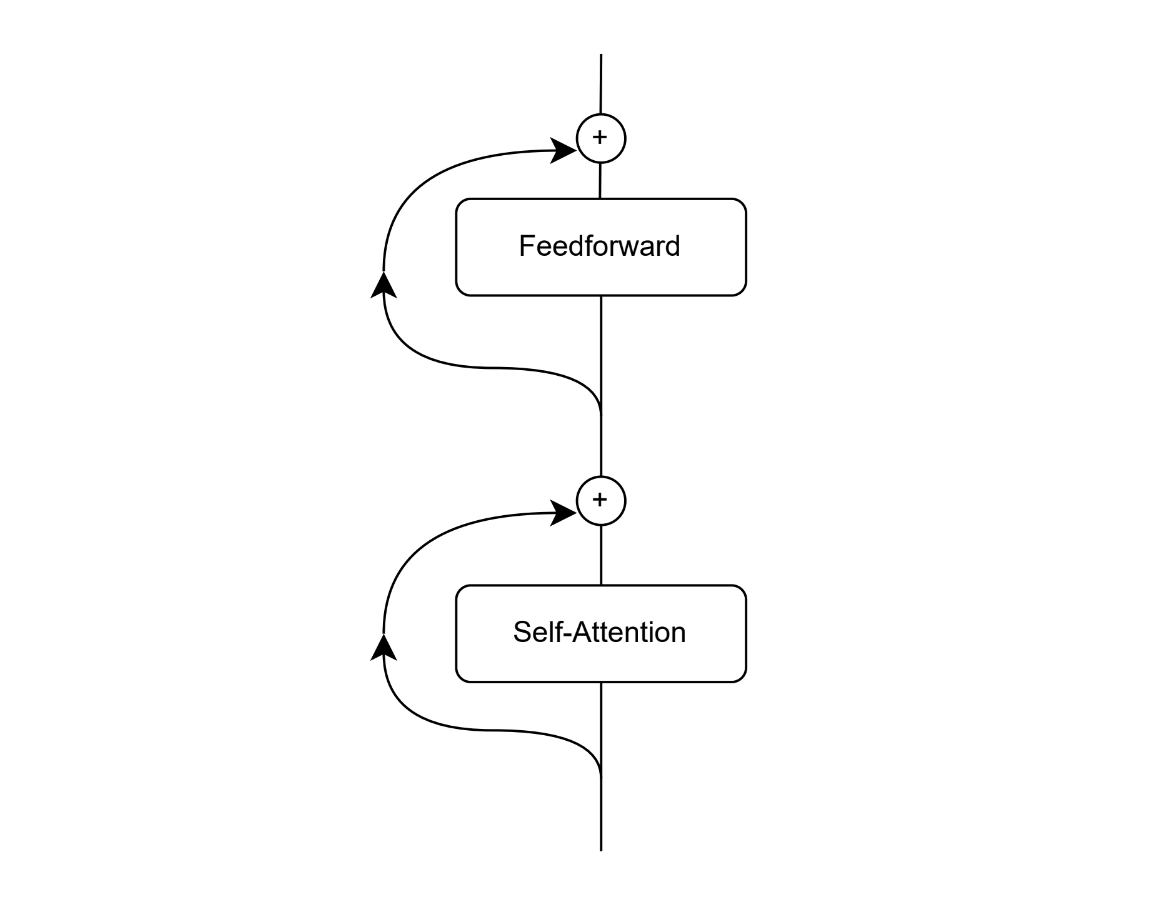
极简Transformer架构图
然而,这种架构会省略一些架构的细节。这些细节很重要,但是不影响理解Transformer的核心功能。
但首先,让我们了解为什么需要Transformer。
在Transformer之前
这是2017年。NLP(自然语言处理)中的深度学习模型很糟糕。你还记得2017年的Google翻译吗?它很糟糕。
用于NLP任务的架构大多是LSTM(长短时记忆架构)的变体,存在两个大问题:
- 顺序执行:LSTM一次“读取”一个单词。假设我们想要阅读整个维基百科(290亿个单词),并且每个单词需要0.01秒。那将总计超过200,000天。
- 糟糕的长期依赖性:LSTM被设计为“记住”它们阅读的所有内容,而不会回溯。这意味着,如果单词“John”在文本开头被提到,而仅在很久以后再次提到,LSTM可能会很难识别它是同一个人。
认识到这些问题后,许多论文尝试实现一种“注意力”的概念。我们将注意力视为在不同时间集中注意文本的不同部分的概念。

注意力在解决数学问题中的应用示例
注意力是忽略不重要的细节,关注我们目标中真正重要的内容的概念。Transformer利用了这个概念,通过使用自注意力。
自注意力
自注意力意味着输入的每个单词都关注同一输入的其他单词。对于自然语言来说,这非常有用,因为在看到其上下文时,单词可能会获得实质性的含义。
例如,“spring”一词在不同的上下文中有不同的含义。因此,“spring”在关注“力学”或“力量”这些词语时可能意味着不同的事情,而在看到“冬天”或“夏天”这些词语时可能意味着其他含义。
为了理解实现方法,最好使用与数据库的类比。你只需要了解一点线性代数(和注意力)。
键值数据库
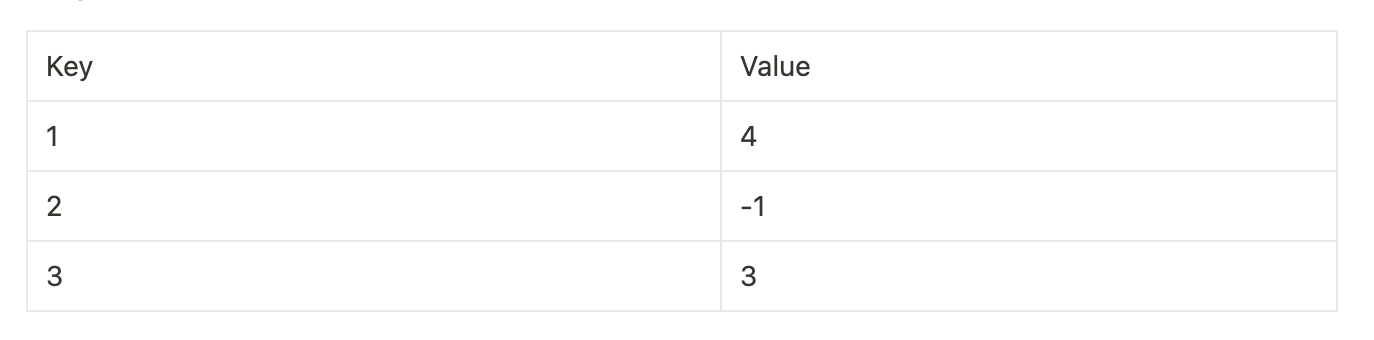
假设我们想要查询这个数据库。假设我们查询值1(Q=1)。然后,关联的值将为4,因为存在键3,其值为4。
如果我们查询值_Q=1.1_会发生什么?该键不存在,因此不会返回任何值。但是,我们可能希望返回4和-1之间的某些内容,因为1.1在它们各自的键(1和2)之间存在。
更好的是,假设键和值不再是整数,而是向量。
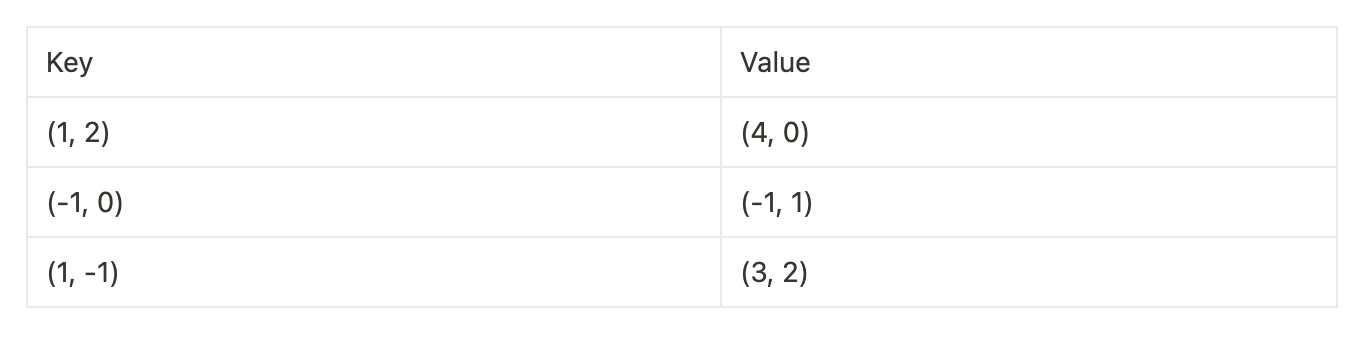
我们可能希望使用另一个向量(例如_Q =(1,0))查询此表。如果我们将该向量与每个键进行比较并知道该键是否相似,那就太好了。
如果你记得你的线性代数,你可能会想起点积实际上就是这样做的。两个长度相同的向量的点积在向量具有相似方向时更大。
让我们来计算一下。
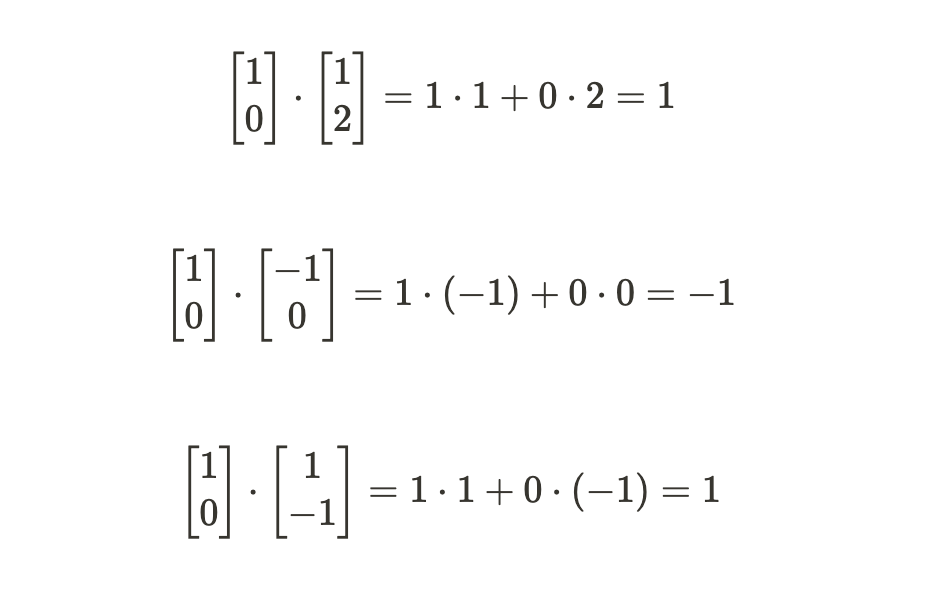
所以我们现在有了哪个向量与查询向量更相似的概念。但是,确定要返回什么值并不简单。我们希望每个值都在0到1之间,并且值的总和为1。这样就可以将其解释为比例。
为此,我们使用Softmax。Softmax将一系列值映射为概率分布。

因此,我们现在可以将每个值与其相应的概率相乘。
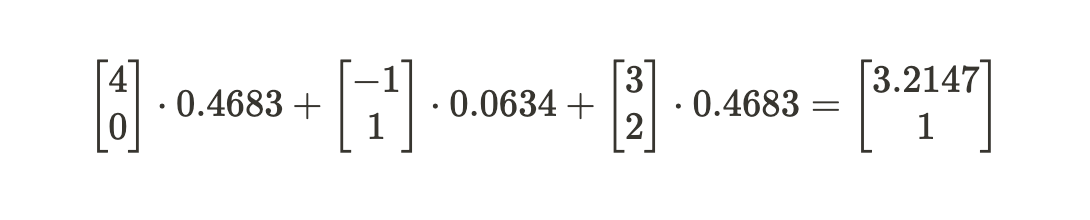
因此,我们计算出_Q =(1,0)的查询关联的值为(3.2147,1)。
现在想象我们不仅要进行单个查询,而是要同时进行多个查询。然后,我们可以将其表示为查询数组。例如,如果我们要查询(1,0)和(0,1),我们会说:(我们通过与之前相同的过程计算了查询(0,1)的结果)
通过管理矩阵,而不是逐个查询并计算其值,将会更好。实际上,我们可以做到。
现在,我们按以下方式重新排列查询、键和值。
现在,为了计算与之前完全相同的概念,我们必须执行:
请注意,Q乘以K的转置实际上与每对查询值进行点乘是相同的。
因此,在沿着这个新矩阵的垂直轴应用Softmax之后,我们只需乘以值即可计算最终矩阵。
这就是自注意力背后的概念。对于输入,我们将计算三个矩阵:查询、键和值。输入中的每个单词将计算一个查询向量、一个键向量和一个值向量。这些向量的数组将是Q、K和V矩阵。
这样,每个单词将与每个单词的键进行比较。如果比较显示它们与另一个单词的键相似,则该键的值向量将在输出中得到强烈的表示。
我们可以通过以下简单的代码实现这一点:
现在,这些结果通过一个前馈层传递。如果你不记得这个层,它基本上只是两个线性层,由激活函数分隔。
这些层增加了在自我注意模块的输出之间计算的能力。现在,单词可以一起使用,形成新的向量,代表输入的更丰富的理解。
有了这个,我们就可以把我们的“极简Transformer”组合起来了。
我们注意到我们使用了残差连接(花哨的说法是我们将输入与层的输出相加)。这是有用的,因为层不必试图“记住”输入,这可能在以后有用,而是试图通过额外的信息增强输入。在实践中,它的效果非常好。
还记得Transformer被创建的两个问题吗?
- 顺序执行:由于每个操作都使用矩阵乘法,因此Transformer可以并行执行所有操作。这样,可以并行处理大量的文本。
- 可怕的长期依赖:Transformer可以在自我注意模块中识别长期依赖关系。无论单词相隔多远,它们仍然会在Q by K^T矩阵中计算这些单词之间的注意力的地方。
但最伟大的成就只在实践中显示。在深度学习中,正如大多数事情一样,结果很难预测。Transformer所做的最伟大的事情是在数据中继续保持一致的表现。如果这种架构无法扩展,GPT、DALL-E、LLaMa将不会存在。
但正如我之前所说,这种架构并不完全是Transformer架构。如果你已经阅读并理解了“极简Transformer”的所有内容,我不建议阅读真正的Transformer架构。
另一方面,如果你理解了这种架构的想法,你可能想要研究以下内容:
- 位置编码:它们在第一个Transformer层之前添加有关单词/输入位置的信息。这样,注意力模型可能会理解单词顺序的重要性。
- 编码器/解码器: 我们可能不希望每个单词都能够关注任何其他单词。这是编码器和解码器之间的区别所利用的。
- 多头注意力: 我们实际上可以为单个单词计算多个查询、键、值向量。
- 归一化层和dropout层: 它们倾向于提高网络的泛化性,并防止过拟合。
\


评论(0)