
作者:Roy Schor,Zane Hankin,Ethan Glazer

本文旨在分享我们研究、创建和测试股票价格神经网络的思路和实际步骤,以便最终预测未来的股票价值。
在这里查看包含所有代码的GitHub链接:https://github.com/eglazer02/Stock-Neural-Network
目录
我们的动机
自股票市场问世以来,人们一直被其波动所困扰,无论是机器还是人类,都无法有效地预测其未来。由于名为Aladdin的AI网络进行投资并控制着全球金融资产的7%,几乎相当于美国的总GDP,我们想,为什么不尝试一下呢?
此外,还有什么能比市场上的货币不断波动更能吸引投资者的注意力呢?这是我们尝试使用神经网络来学习股票市场中的某种模式并超过市场每年平均增长率10%的尝试。
我们成功了吗?我想你需要继续阅读以找出答案...
我们的方法
首先,我们在Google文档中制定了一个粗略的路线图和目标(纸张的时代已经过去了)。我们决定以LSTM(长短期记忆)神经网络模型为基础进行我们的项目。
在这里,我们将提供一些基本的指导信息;但是,你可以搜索大量网站、书籍和视频来深入研究这些主题;我们使用的许多内容将在引用文献部分底部列出!
那么什么是LSTM?
这是一个很好的问题。
LSTM代表长短期记忆,是一种适用于处理顺序数据的循环神经网络。这些网络在其选择性存储、更新和删除数据的过程中更有效地处理长期信息的能力是独特的。LSTM通过使用可以存储数据更长时间的“内存单元”来实现这一点。还通过使用控制哪些信息进入这些内存单元(输入门)、哪些信息允许出去并被遗忘(遗忘门)以及最后,哪些信息传播到下一个阶段(输出门)的门来实现这一点。
我们的目标是采用这种类型的模型并在特定股票的一组收盘价上对其进行训练。然后,我们将要求该模型基于前4天的数据预测第5天的收盘价。
例如,该模型应该预测周五的收盘价,给定周一、周二、周三和周四的阿尔法股票收盘价。
不同的方法:
我们经历了两种主要方法;第一种初始方法失败得非常惨。这导致我们花费了更多时间深入研究该主题,最终创造了第二种成功的方法。
像往常一样,我们将从失败的第一种方法开始。
初始方法、数据设置和神经网络
数据,数据,数据
每个好的神经网络都依赖于一个巨大的数据库。如果一台机器的实力取决于它所学习的数据,那么你最好使用尽可能深的数据网络。至少,这是我们的想法;我们将在后面理解为什么这只是有时的情况。
我们在Kaggle上搜索,直到我们找到适合我们的股票数据集,有很多可供选择。我们最终选择了Boris Marjanovic创建的数据集,非常感谢他。
数据按照CSV文件的方式布置。每个文件都包含一支股票的完整历史记录,直到2017年。CSV文件按日期排序,其中包括日期、开盘价、收盘价、最高价、最低价、收盘价和交易量。我们的第一步是处理和清理数据。

下面你可以看到我们清理之前的原始数据长什么样子:
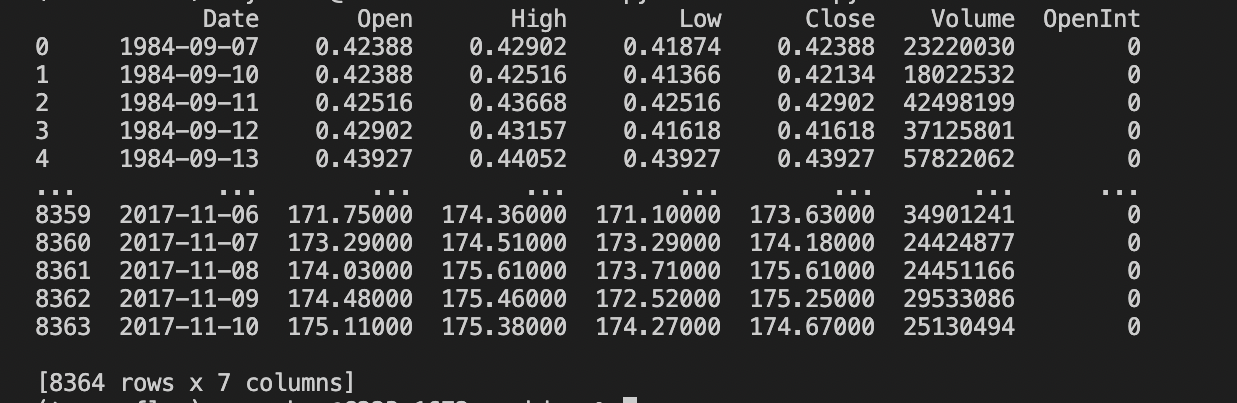
经过一些编码魔法:
# Start and end date of the data we will reading in - interchangeable
start_date_1 = '2013-12-31'
end_date_1 = '2016-01-01'
# File we read in, we only read the Date and Close values from the CSV
stockDataFrame = pd.read_csv('/Users/royschor/Desktop/Core Course/archive/aapl.us.txt', usecols=['Date', 'Close'], dtype={'Date': 'str', 'Close': 'float'}, parse_dates=['Date'], index_col='Date')
# Reads in all the data, then slices it to only take the data after the start date
stockDataFrame = stockDataFrame.loc[start_date_1:end_date_1]
我们最终得到了这个:
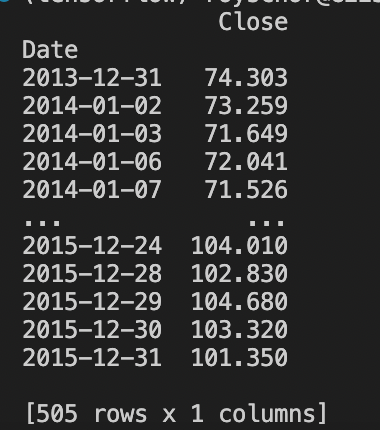
现在我们正在取得进展。
我们的目标仅是获取股票的日期和收盘价,其中一个关键目标是使用易于传输到任何文件或放在循环中的文件的代码。我们只获取日期和收盘价,删除所有其他数据,因为我们认为它对我们的目的毫无意义。
需要注意的是,日期列仅用于我们的图形目的,而网络将仅使用收盘价。此外,每个收盘价表示一天的交易。
以下是我们选择的股票Apple Inc.的表现情况:
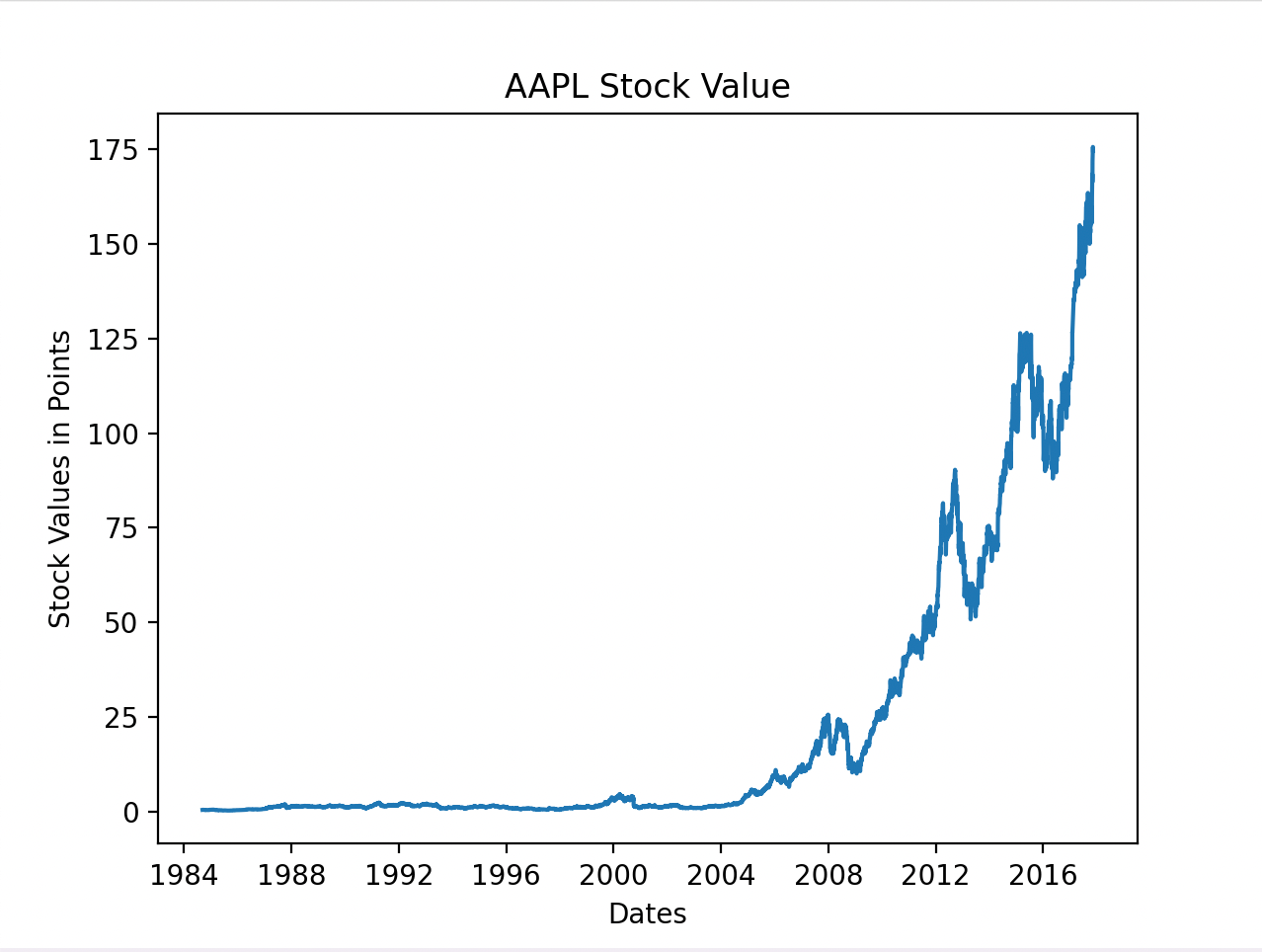 经过更多头脑风暴,我们将数据分成了窗口子集,就像之前提到的4和1的组合一样。这是我们的网络接收四天的数据来预测第五天股票数据的地方。
经过更多头脑风暴,我们将数据分成了窗口子集,就像之前提到的4和1的组合一样。这是我们的网络接收四天的数据来预测第五天股票数据的地方。
创建网络
现在我们已经正确地格式化了数据,我们知道了如何将其馈送到我们的网络中,唯一剩下的就是构建网络了。
我们保持基础设施相当简单:一个具有四个输入和一个输出、一个LSTM层和一个密集层的顺序模型。
- 四个输入神经元是为四个输入日而设计的,对应一个输出神经元。
model = Sequential()
model.add(LSTM(64, input_shape=(4, 1)))
model.add(Dense(1, activation='relu'))
此外,我们使用了Adam优化器来编译模型,并将均方误差最小化作为我们的损失。然而,我们使用平均绝对误差作为度量标准,以更好地衡量我们的预测准确度与历史数据的比较。
这就是我们模型所需要的全部!(至少我们当时是这么认为的)
馈送网络并获得结果(近似)
我们将数据分成了80%和20%的比例来进行馈送。80%是我们的训练数据,20%是我们的测试数据。
然后,我们通过创建两个数组来创建我们的x_train和y_train,其中x_train是前四天的数据,我们的第五天是我们的y_train值。这就是我们所信奉的4-1哲学。
raw_training_data.append(x_train_vals)
raw_training_data.append(y_train_vals, 0, 0, 0)
运行模型得到了非常奇怪、无法解释的结果。我们陷入了停滞状态。我们不知道发生了什么,尽管我们付出了很多努力,但我们需要帮助来解决问题。

这时我们停止了编码。在接下来的几天里,我们处于研究模式;计算机科学家中的“科学家”处于前沿。
我们不会过多地介绍研究或我们所学到的内容。然而,如果你查看本文的结尾,你可以找到我们所有的参考文献,并附有对主要内容的简短描述。
第二种方法——成功的方法
对研究和发现的评论
我们寻找了其他类似项目和如何调整它们的方法。有两篇文章帮助我们纠正了错误。第一篇是这篇文章。感谢作者Jason Brownlee,他更好地阐述了如何使用LSTM预测时间序列数据点。由于这篇文章,我们退后一步,重新思考了我们最初的LSTM模型计划:为我们的RNN构建短期记忆。推动我们进步的来源是这个Youtube视频,它为我们提供了一种更理想的数据分割方法。我们学会了将数据存储在Pandas DataFrame中,而不是将数据排列成x和y的数组。
通过挑选信息、大量研究和新获得的知识引领我们,我们感到准备好应对这个挑战了。
数据格式化
一切都回到了数据...
我们不仅保留了“日期”和“收盘价”,还将过去四天的数据附加到了同一行的预测日期中:

如上所示,每个日期都有5个相应的股票值。每个“目标-X”都是前4个股票日之一,而“目标”是当前股票日和我们网络的预测目标日。
现在我们可以在四天的分割之间向前滑动一天,并训练我们的模型输出整个数据集的第五天。我们称之为“滑动窗口”方法。这样做可以更容易地可视化、组织和访问数据,同时扩大我们的数据量。我们不再只使用5个数据点,然后转移到下一个五个,而是可以每次滑动一天,如下所示:
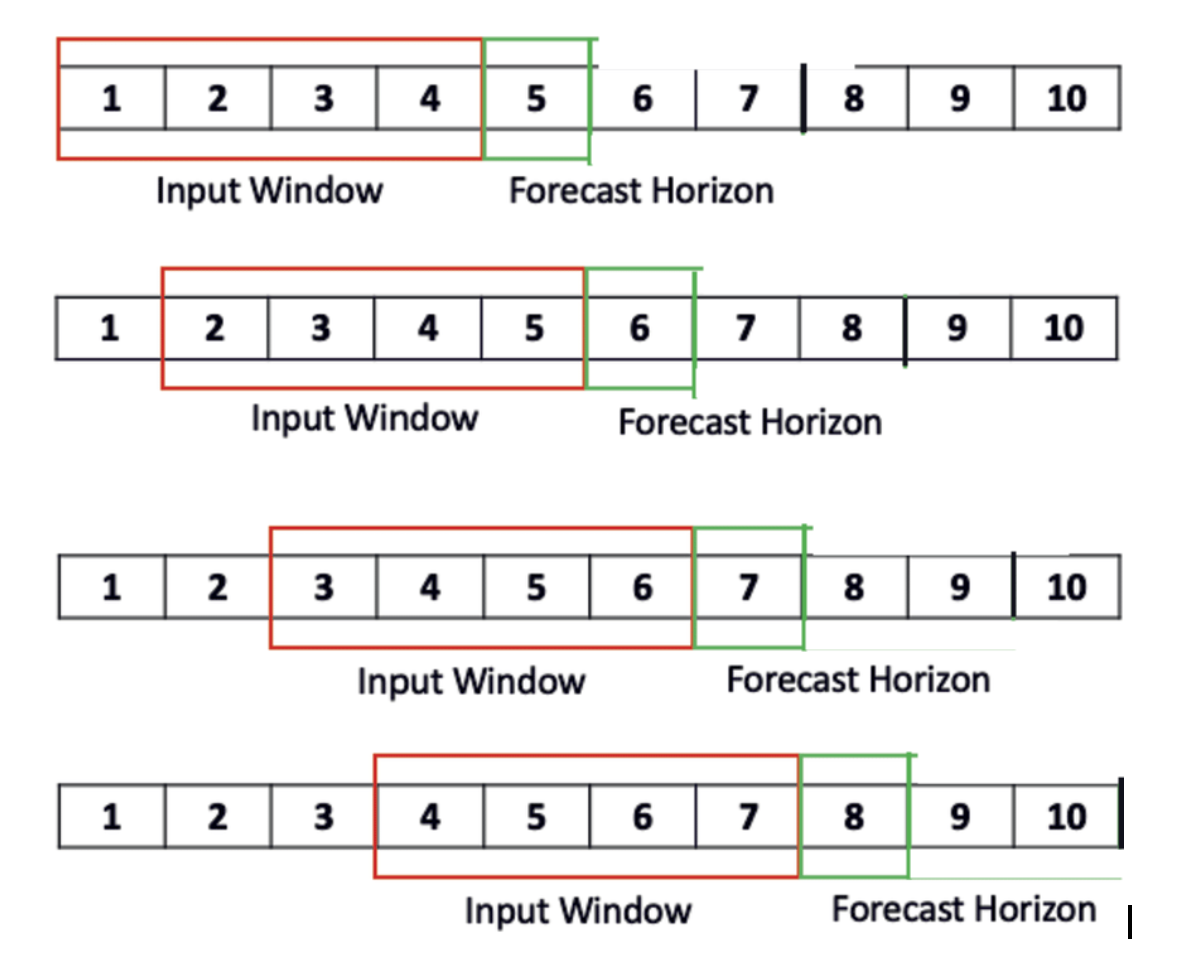
我们使用以下代码来完成这个过程,还有两个辅助函数;如果你阅读代码的注释,应该可以很好地了解正在发生的事情:
def main():
# File we read in
stock_data_frame = pd.read_csv('AAPL.csv')
# we only take in the Date and Close values from the CSV
stock_data_frame = stock_data_frame[['Date', 'Close']]
# Converts all Dates of type string to type Datetime
stock_data_frame['Date'] = stock_data_frame['Date'].apply(convert_to_date)
# need to remove the first column (index column) as its useless data
stock_data_frame.index = stock_data_frame.pop('Date')
windowed_df = split_df_to_windowed_df(stock_data_frame, window_size=4)
# Here we slice the windowed dataframe greatly
# We believe that the network training all the data actually harms its predictions
# as it is not training on the most volatile part (the recent history),
# thus we are now trying to only train on recent history (past 3 years not all 30+)
start_date = "1983-01-01"
end_date = "2023-05-03"
windowed_df = windowed_df.loc[start_date:end_date]
windowed_df = windowed_df.reset_index()
# This function splits the dataframe into windows to feed into the network
# Each row now includes a date, followed by previous 4 days, and final column is prediction day's data
def split_df_to_windowed_df(data, window_size=4):
# Creates our temporary datafram
windowed_df = pd.DataFrame()
for index in range(window_size, 0, -1):
# appends to each row in df past 4 days of data, one day at a time and shifts the entire data doing so
windowed_df[f'Target-{index}'] = data['Close'].shift(index)
windowed_df['Target'] = data['Close']
# Removes all rows that are missing some data - any incomplete windows that would mess up training
return windowed_df.dropna()
# Each date in the dataframe is a string but we want it as a Date object
# thus this function converts a string to Datetime object
def convert_to_date(stringDate):
# splits based on hyphen as the string of date is seperated by hyphen
split_value = stringDate.split('-')
year, month, day = int(split_value[0]), int(split_value[1]), int(split_value[2])
return datetime.datetime(year=year, month=month, day=day)
现在,我们的数据框已经被格式化成了滑动窗口,我们需要将数据重塑,以便LSTM可以接受它。重塑的过程看起来有点像这样:
# Now need to fix data to be numpy and reshape it to fit in LSTM
df_npied = windowed_df.to_numpy()
# grab only all the dates, first column is dates
dates = df_npied[:, 0]
# takes all past data points exluding date and target date data, so first and last
middle_data_segment = df_npied[:, 1:-1]
# reshaped by length of dates, the size of the middle part, and 1 for us as this is a univariate problem
total_x_data = middle_data_segment.reshape((len(dates), middle_data_segment.shape[1], 1))
total_y_data = df_npied[:, -1]
# this fixed a bug adding float32 conversion
total_x_data = total_x_data.astype(np.float32)
total_y_data = total_y_data.astype(np.float32)
# dates.shape = (8360), total_x_data.shape = (8360,4,1) (4 steps in past) (1 float variable), total_y_data.shape = (8360)
创建训练、验证和测试数据
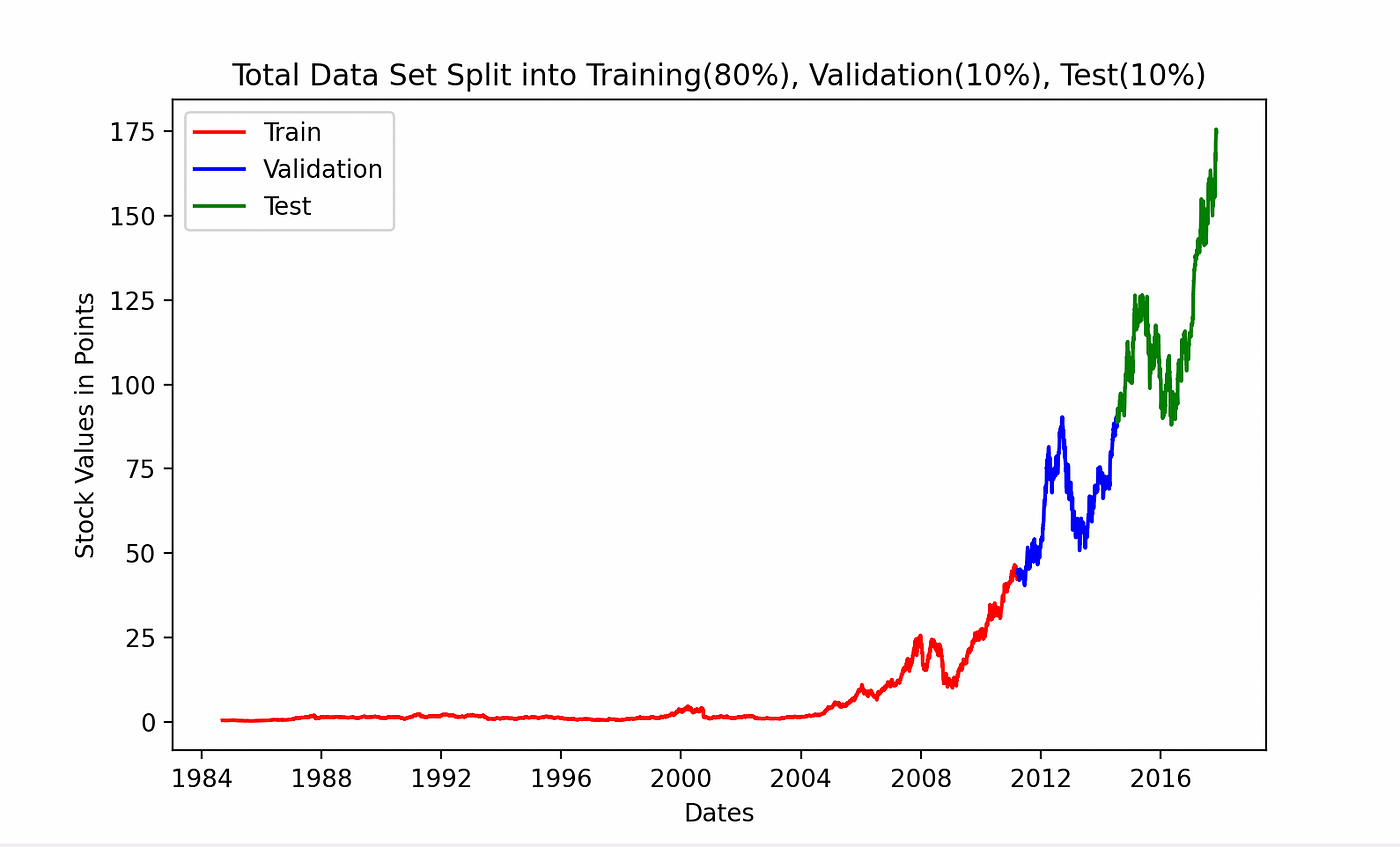
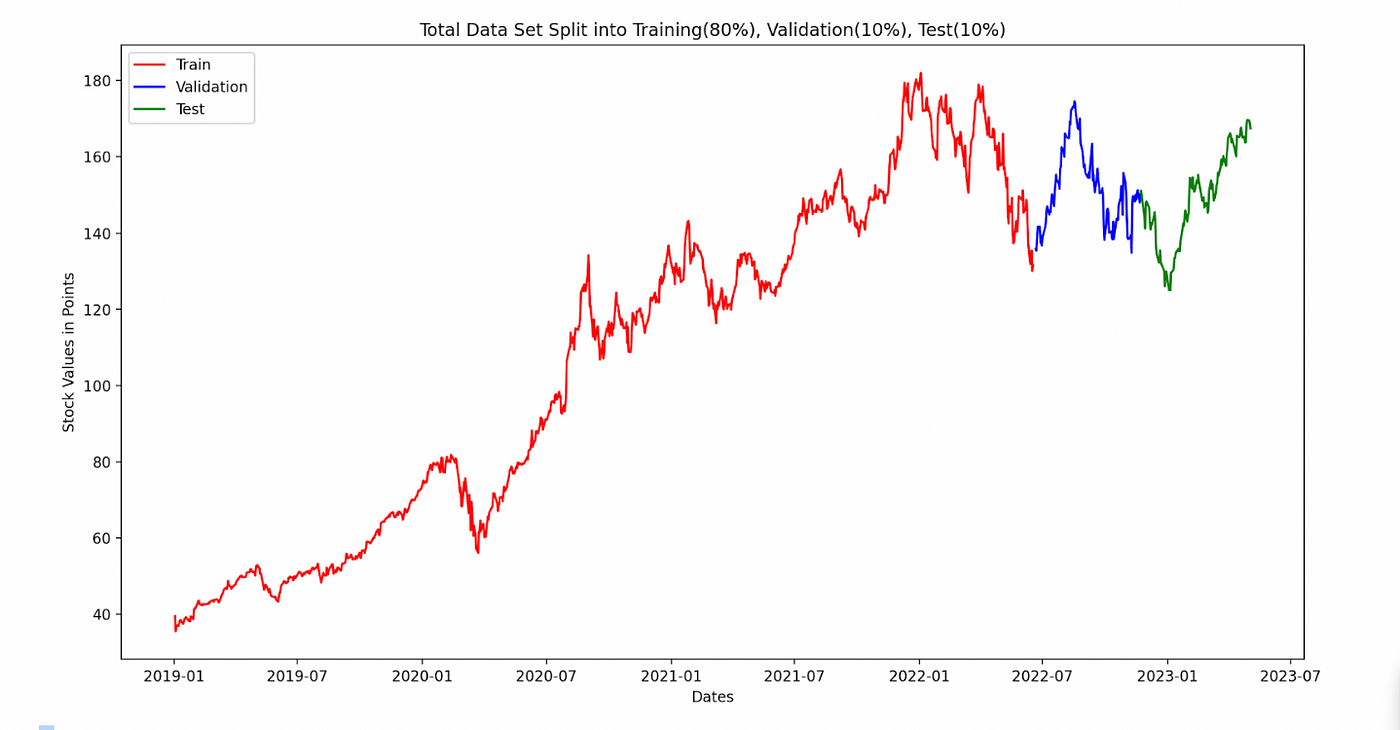
我们采用了第一种方法相同的策略。80-10-10的比例。80%的数据现在被重塑后用于训练,10%用于验证以调整网络,10%用于测试数据。
这是一个相当简单的切片过程:
# Now we create training, testing, and validation data
# We will do 80% training, the remaining 20% is split 10-10 into validation and testing
eighty_split = int(len(dates) * .8)
ninety_split = int(len(dates) * .9)
# Up until 80%
dates_train, x_train, y_train = dates[:eighty_split], total_x_data[:eighty_split], total_y_data[:eighty_split]
# between 80% - 90%
dates_validation, x_validation, y_validation = dates[eighty_split:ninety_split], total_x_data[eighty_split:ninety_split], total_y_data[eighty_split:ninety_split]
# 90% - end
dates_test, x_test, y_test = dates[ninety_split:], total_x_data[ninety_split:], total_y_data[ninety_split:]
下面你可以看到数据的分割可视化:
创建和适配网络
为了创建网络,我们采用了第一种方法所采用的相同构建,但是更加复杂。来自Greg Hogg的Youtube视频和Jason Brownlee的文章的技巧非常有帮助。
我们的模型具有一个形状为4-1的LSTM层,用于输出1个预测日期的4个输入日期。然后我们添加了2个密集层,并使用Adam优化器。大量的调整使我们将learning_rate设置为0.001;最初它是0.01,但从研究中我们得知最佳值是特定于案例的,需要试错。我们的损失和度量标准与第一种方法中相同。
# Creating the Network 4,1 for 4 inputs dates one output
model = Sequential()
model.add(layers.LSTM(64, input_shape=(4,1)))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1, activation='relu'))
model.compile(optimizer=Adam(learning_rate=0.001), loss='mean_squared_error', metrics=['mean_absolute_error'])
fits = model.fit(x_train, y_train, validation_data=(x_validation, y_validation), epochs=20, callbacks=[history])
training_predictions = model.predict(x_train).flatten()
validation_predictions = model.predict(x_validation).flatten()
test_predictions = model.predict(x_test).flatten()
我们还决定添加一个回调。模型的回调是在一定时间段内调用的函数,该时间段是可根据编码者设置进行调整的。我们想在每个时期结束时获取损失和度量数据,并将其附加到相应的数组中。我们创建了一个类来实现这一点:
class Histories(Callback):
def on_train_begin(self, logs={}):
self.losses = []
self.val_mean_absolute_error = []
self.validation_loss = []
def on_epoch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
self.validation_loss.append(logs.get('val_loss'))
self.val_mean_absolute_error.append(logs.get('val_mean_absolute_error'))
现在我们真正准备好了。准备好看看我们所创建的内容,以及它在视觉上是什么样子。## 准备好预测
最初,我们考虑使用全年股票数据来训练模型。数据越多,效果越好,对吗?
事实并非如此。我们发现最初,大多数股票的价格都非常低迷。直到如果它们成为一家成功的公司,股票才会飙升,然后非常不稳定但总体上在增长。然而,由于股票一开始非常低迷,并且保持这种状态很长一段时间,因此我们的模型是在这种低迷的增长上进行训练的。因此,它认为这种模式将会继续,导致对实际股票的繁荣和萧条的预测出现偏差。以下是不同的预测(模型创建的数据)与观察值(真实数据)。
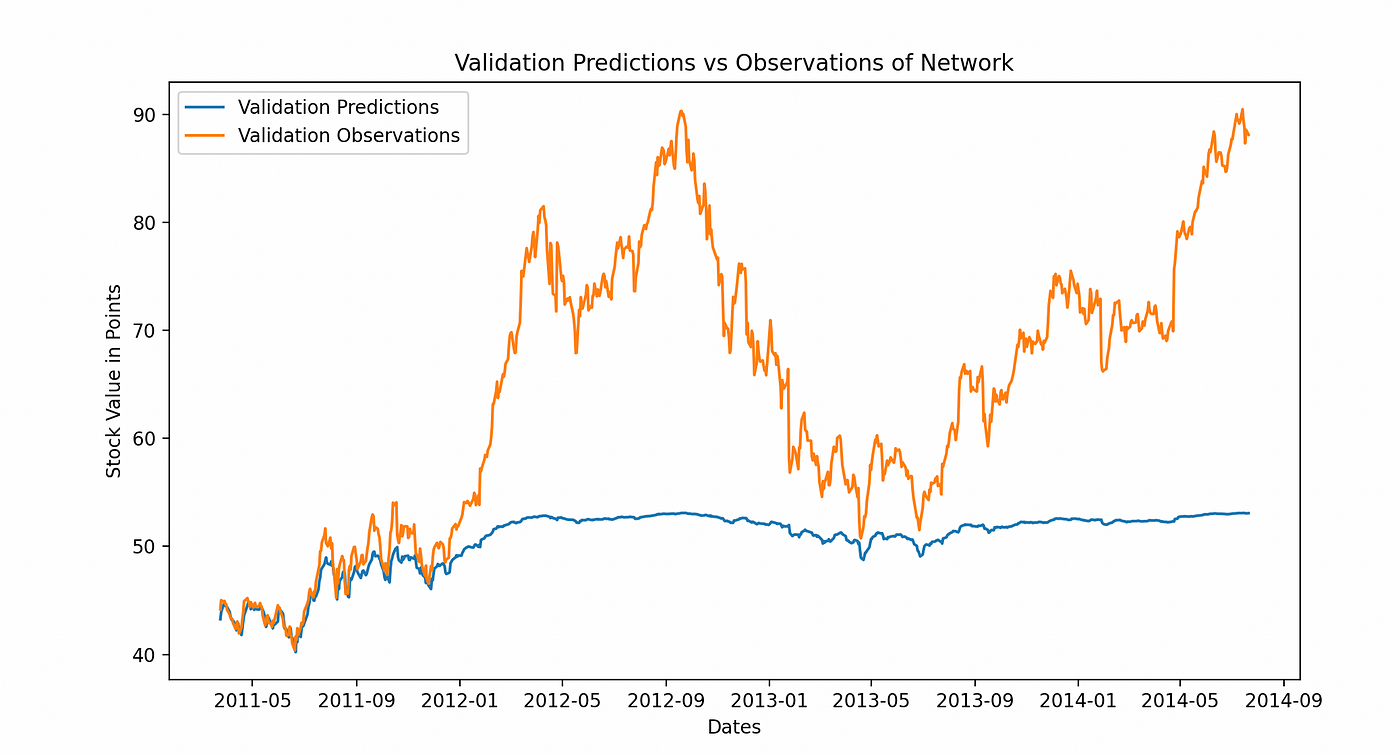
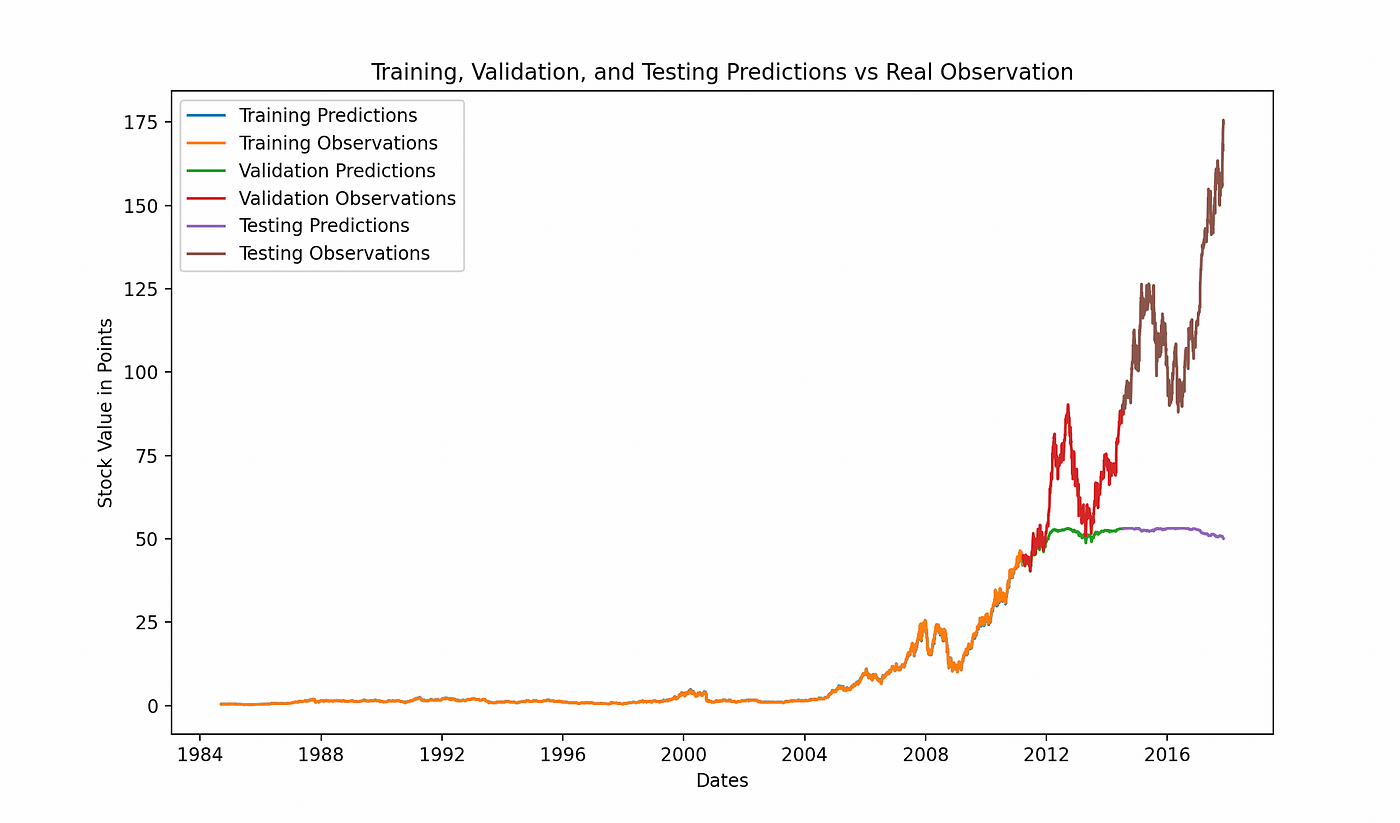
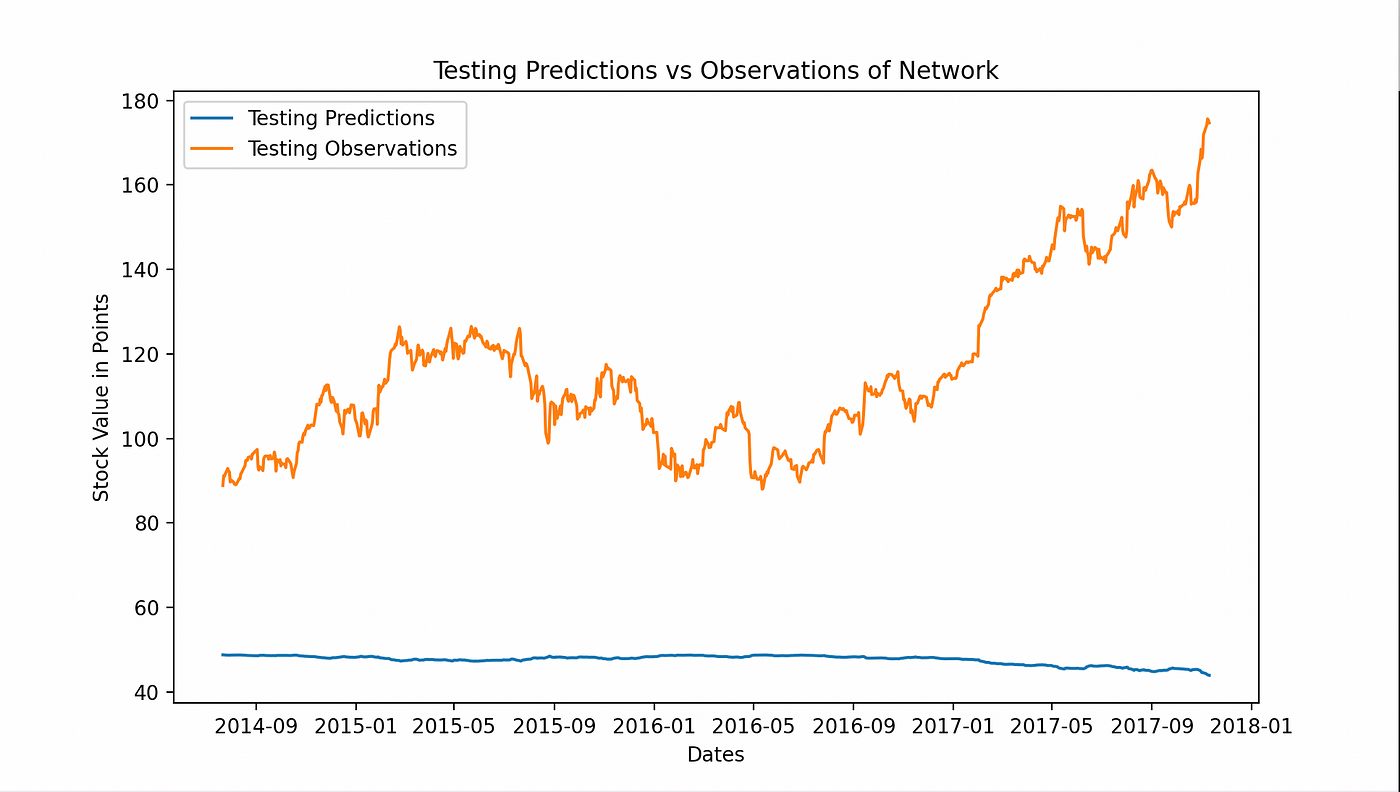
每个图表都显示了我们网络猜测与真实股票价值的比较。第一个显示了整体验证预测与验证观察值或实际数据点。我们的网络无法跟随初始跳跃,保留了过去缓慢增长的模式。
这在第二个图表中再次出现,我们展示了所有三种预测与实际数据点的比较。网络的预测与观察非常接近,直到停滞点为止。
正如我们所看到的,它未能跟随股票在繁荣后的关键模式。两年前的数据导致其预测在某一点之后停滞不前。
缩减数据
因此,我们决定将更少的数据提供给网络。我们选择了一年,因为我们只想检测可以帮助预测明天股票价格的模式。
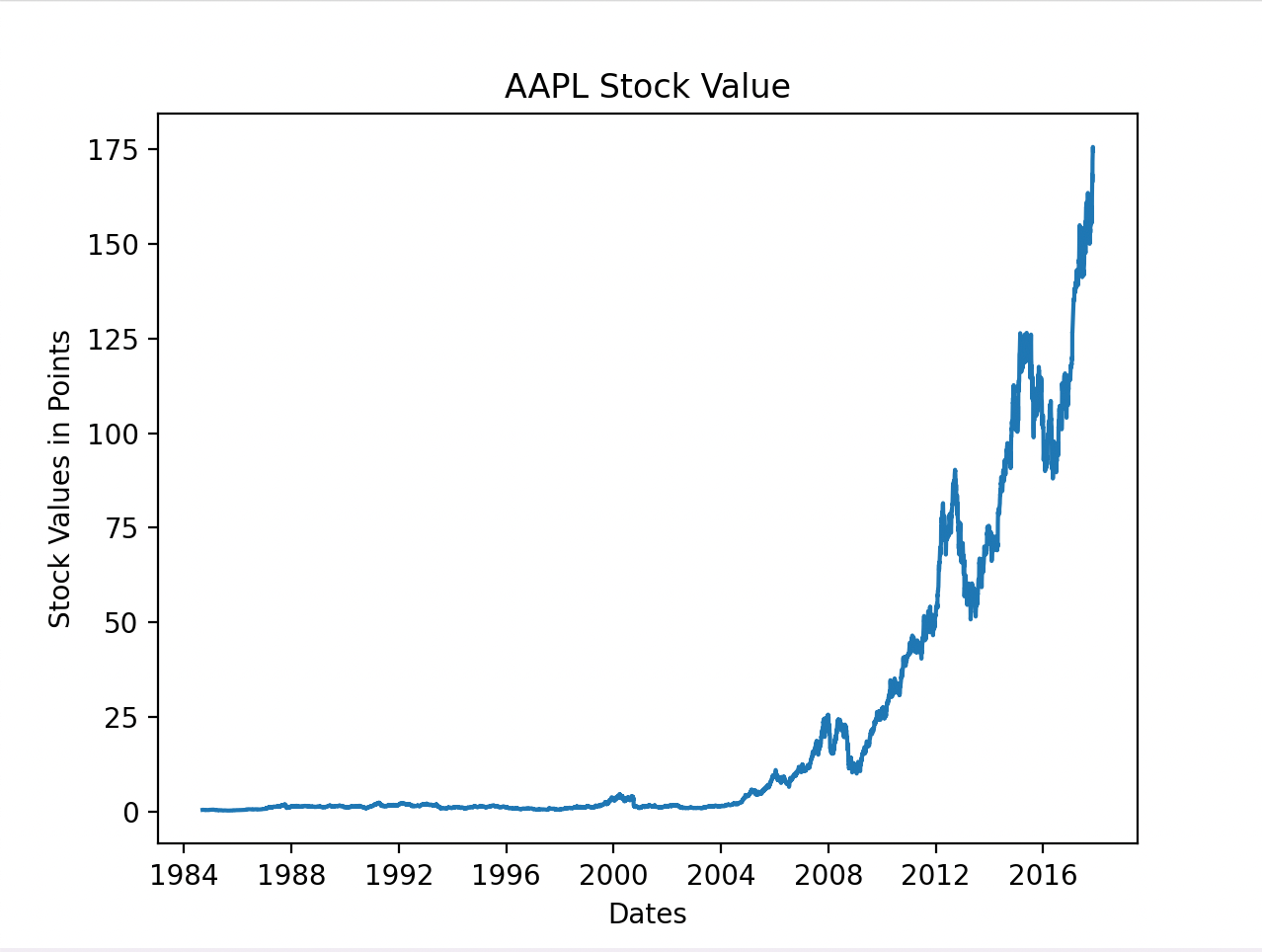
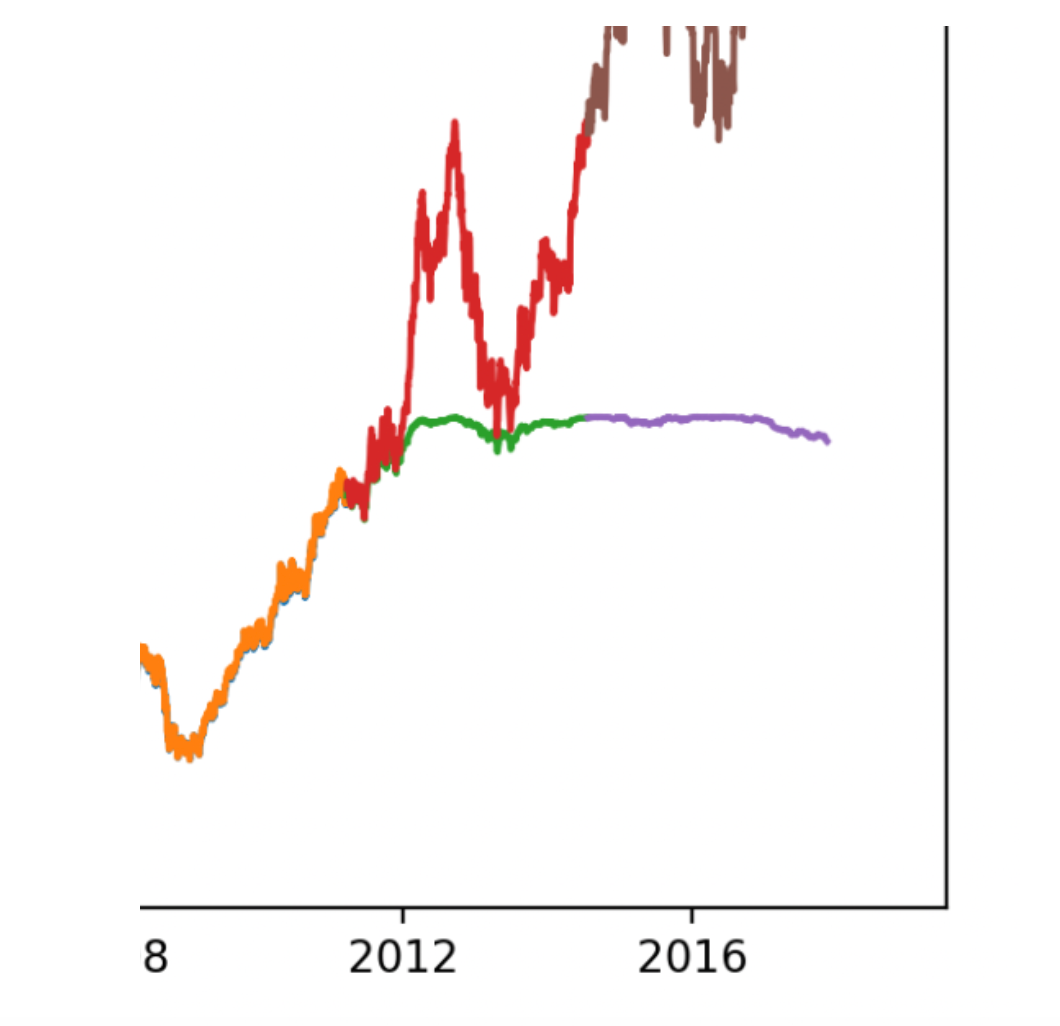
以上是AAPL股票从1984年到2017年的所有数据。我们最初使用这些数据来训练我们的模型,但在意识到我们需要训练更小的数据集以获得最佳结果后,我们削减了约31年的数据,重点关注2015年至2017年之间的两年。我们的表现更好了。
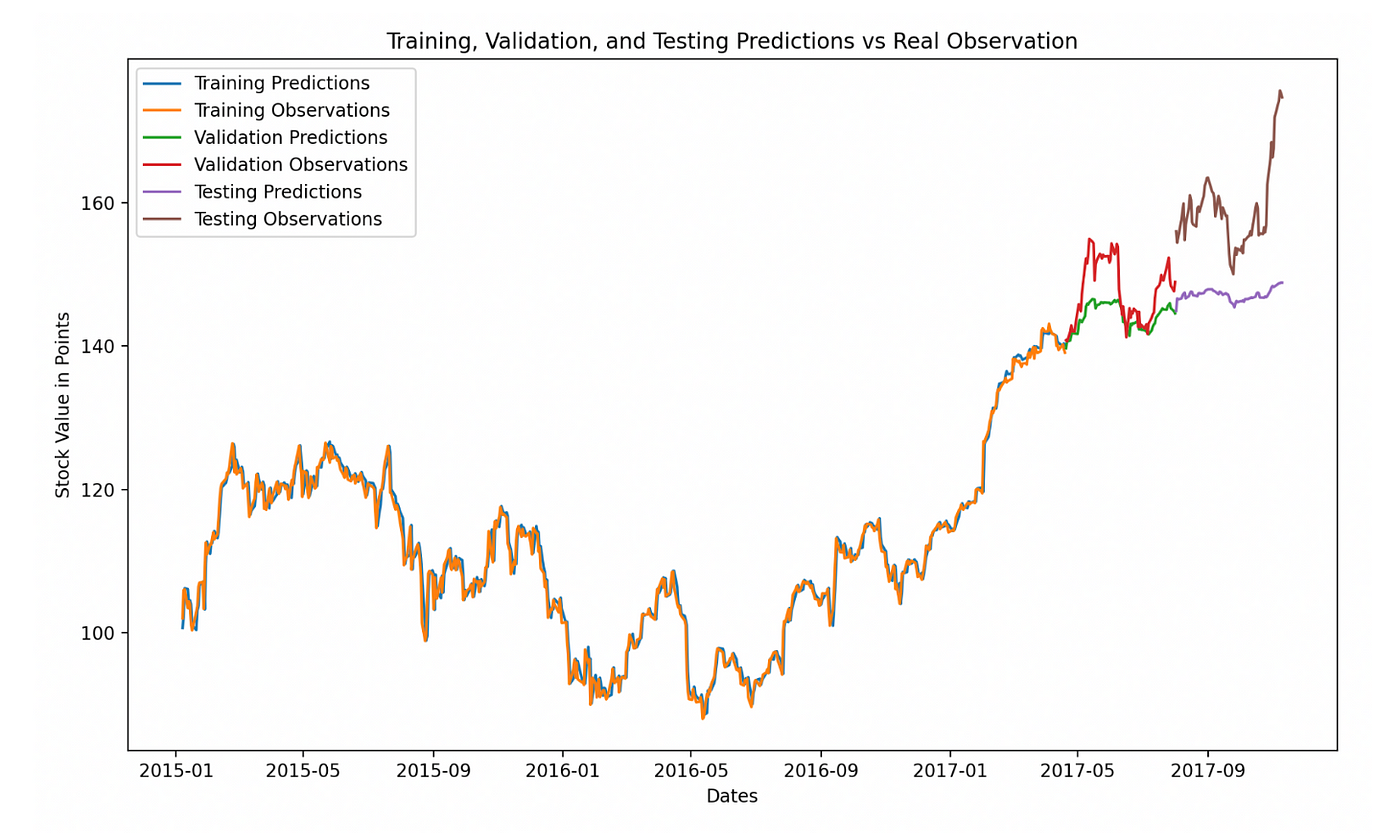
你可以看到我们的验证预测(绿色)和测试预测(紫色)与我们的验证观察值(红色)和测试观察值(棕色)的表现要比我们之前的模型好得多。停滞更好了。
进一步观察图表后,我们注意到数据中的空缺。我们认为我们的来源在信息存储方面存在空缺。这不好,空缺将导致我们的网络在此之后无法进行良好的预测。我们决定使用雅虎财经,这为我们提供了更完整的历史数据来下载和访问。
下载了这个数据集之后,我们使用各种日期重新训练了我们的模型。
首先,我们使用整个数据集运行我们的模型。以下是我们收到的预期结果,具有相当快的停滞/下降,这在被训练为逐步增加的收盘价后是有道理的。

缩小训练规模
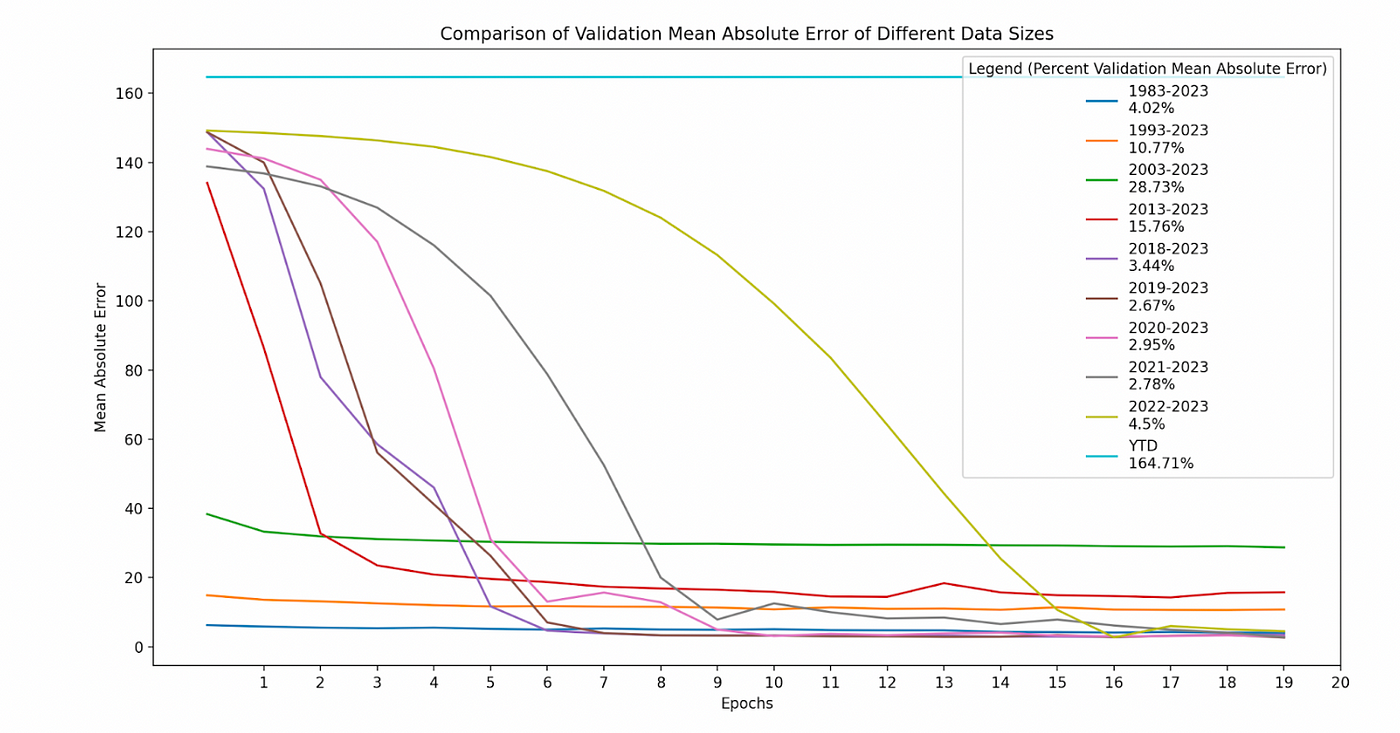
使用我们的新方法将时间窗口大小缩小到较小的年份跨度,我们决定找出哪个数据窗口大小是我们的“金发女孩”。我们在几个时间段上对我们的模型进行了20个时期的训练,并确定了具有最低验证平均绝对误差的窗口大小是从2019年1月1日至2023年5月3日。请参见下面我们比较的图表:
注意:当我们训练从2023年1月1日到5月3日(本年度,或YTD)的数据时,我们的模型无法确定足够特定的模式。我们认为这是太短的一个时期。这意味着太多或太少的数据都会损害网络。关键是找到最佳结果的确切数量。
然后,我们进一步研究了在训练数据后的预测,特别是在2019年1月1日至2023年5月3日之间的数据上。
使用AAPL的以下切片股票:
start_date = "2019-01-01"
end_date = "2023-05-03"
windowed_df = windowed_df.loc[start_date:end_date]
我们将数据拆分为以下80%的训练,10%的验证和10%的测试:
最终结果
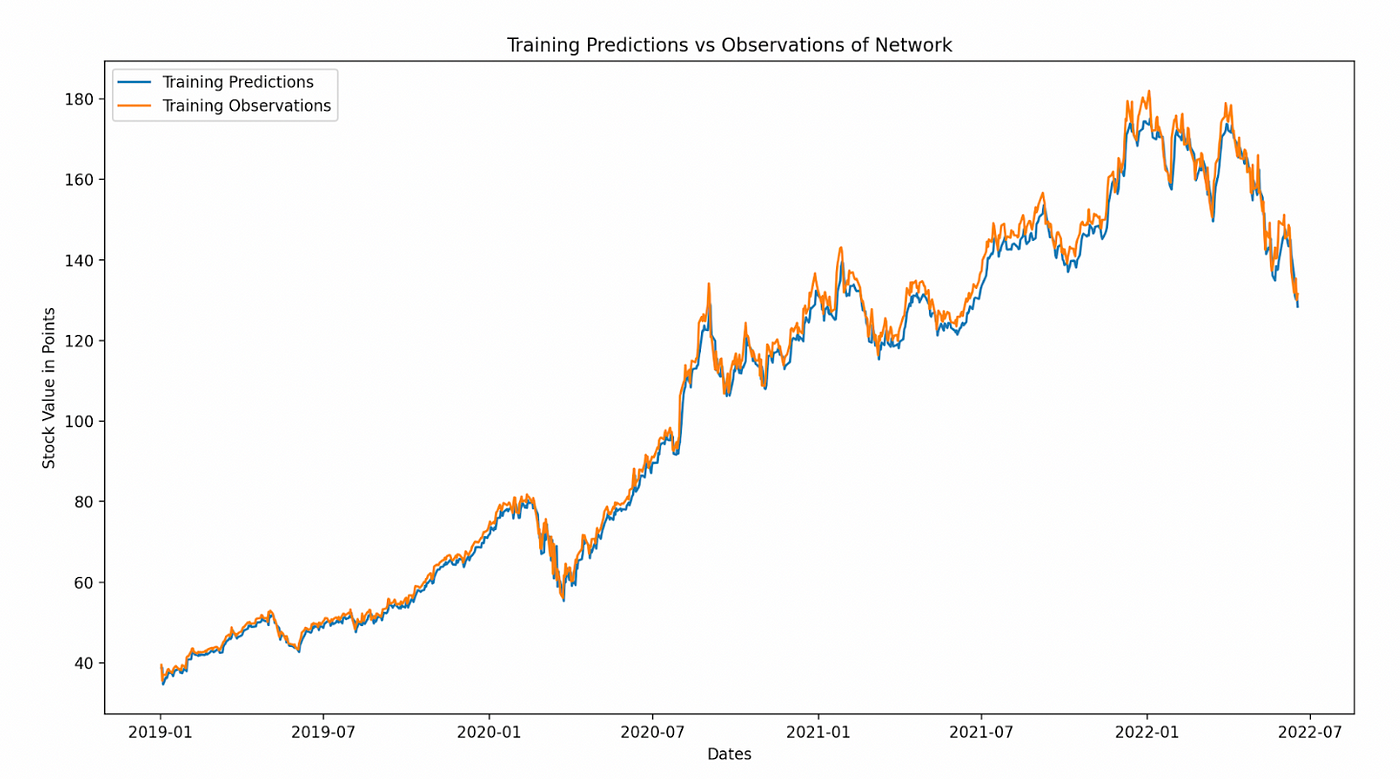
一旦我们将数据发送到我们的模型中运行,我们打印出实际股票价格和我们模型的预测股票价格的比较。看起来很不错,尽管我们高估了一些价格,但平均预测非常接近。
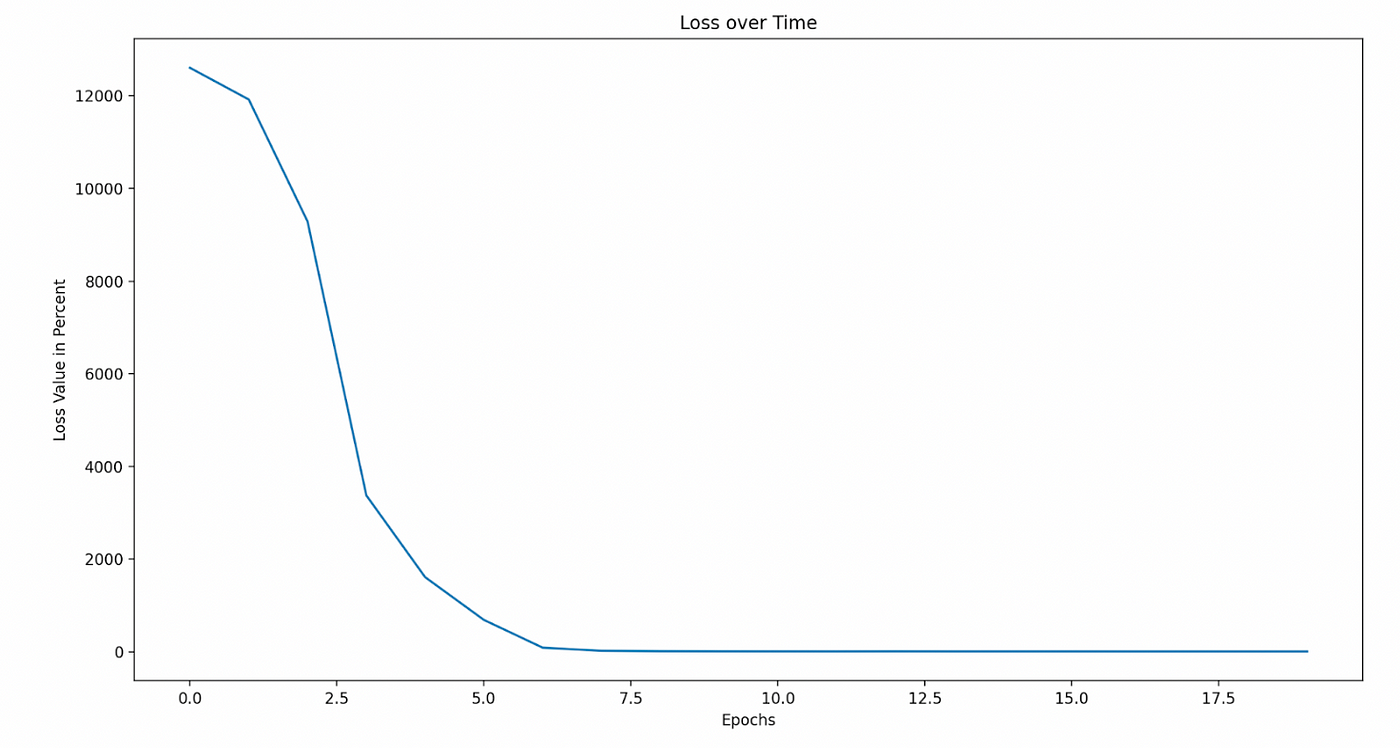
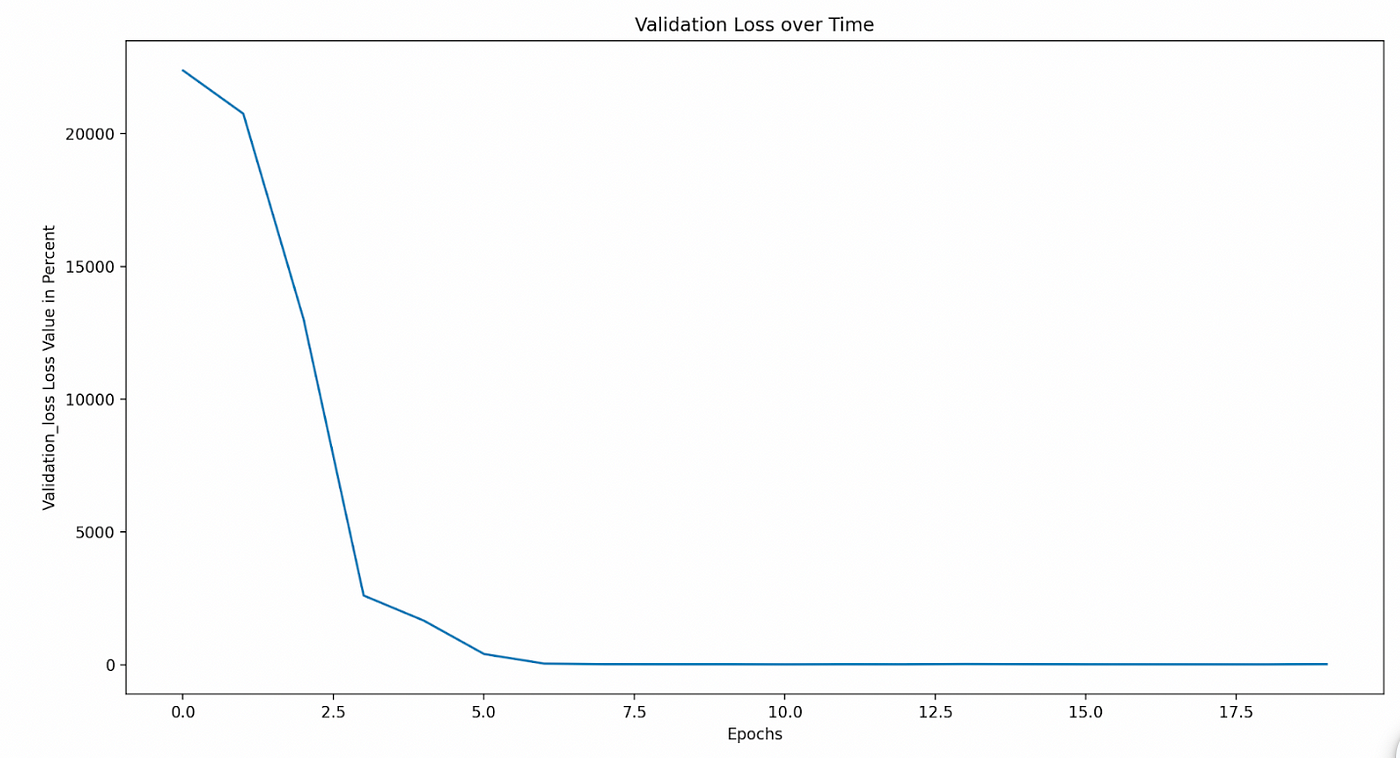
 为了更好地可视化我们的模型所面临的损失,我们尝试创建了一些图表:
为了更好地可视化我们的模型所面临的损失,我们尝试创建了一些图表:
请注意许多图表的比例尺;线条似乎偏离得很远,可能会误导。对于一些图表,股票点数的比例尺处于微观级别!
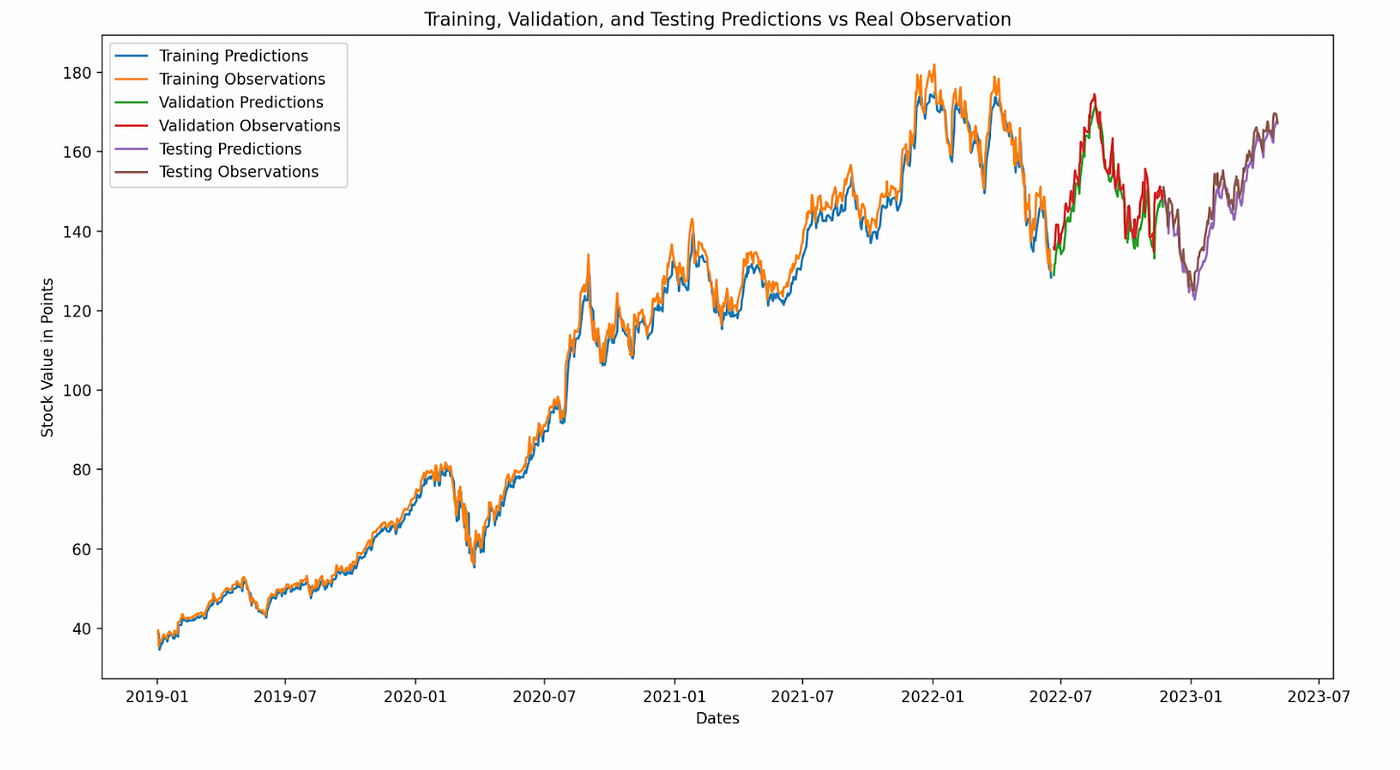

结论和收获
最终,我们能够构建一个模型,根据AAPL股票,能够将股票价格外推X天。由于我们使用的是历史数据,我们可以确定我们的成功率很高——这个成功率会随着时间段和股票而改变。这意味着网络可以在短期内预测股票价值,并且存在一定的模式。
扩展
我们希望在将来添加到这个项目中的一些内容包括:
- 能够通过简单地使用给定的股票代码和其API自动从Yahoo Finance抓取股票数据。
- 通过输入X金额并模拟其在给定期间内在股市中的增长或下降,使其与道琼斯工业平均指数的年度10%的收益率保持不劣。
- 通过抓取新闻媒体来改进我们的预测,以帮助微小地影响股票价格的变化/下跌,这将影响我们网络的权重和偏差。
关键术语
训练数据
我们训练模型的数据。这是我们从数据集中选择的80%的数据所表示的。我们对这些数据应用“窗口滑动”方法,以使模型学习第5天的收盘价格应该是多少。
验证数据
我们验证模型的数据。这是我们从数据集中选择的接下来的10%的数据所表示的。我们对这些数据应用“窗口滑动”方法,以使模型学习第5天的收盘价格应该是多少。
测试数据
这是我们用来测试模型的数据。这是我们从数据集中选择的最后10%的数据所表示的。训练后,我们向模型提供四天的时间窗口,要求其预测第五天的结果。
训练、验证和测试预测
对于训练和测试,这是我们的模型预测的每个4天滑动时间框架的“第五天”数据。对于验证,我们的模型根据其预测与实际观察值进行微调,以调整网络的参数。
训练、验证和测试观察值
这些是我们选择的实际收盘价格数据。它是公司在这个时间窗口内的实际股票价格,用作比较值。
训练损失
指训练预测与观察值相比的糟糕程度。如果完美,则训练损失为零。随着模型表现越来越差,训练损失会增加。
验证损失
指验证预测与观察值相比的糟糕程度。
验证平均绝对误差
评估验证观察值和验证预测之间的误差。它是通过绝对误差之和除以样本大小计算的。因此对于我们来说,它是验证预测和观察之间的绝对误差之和,除以我们选择的窗口大小中的数据点数(天数)。
引用文献
第二个完整数据集-
最初的数据集-
关于任何Keras相关内容的每个子页面都用于大量研究信息-
关于人工智能和股票的研究文章-
https://www.linkedin.com/pulse/can-artificial-intelligence-used-improve-stock-trading-bernard-marr/
说明如何使用LSTMs预测时间序列数据点的文章-
Pandas文档中心-
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
**与Blackrock的Aladdin及其功能相关的文章-**以下是三个链接:
-
介绍了由跨国投资公司 BlackRock 开发的强大 AI Aladdin 的文章:https://www.thinkpolnews.com/the-powerful-ai-shaping-the-world-meet-aladdin-from-blackrock/#:~:text=An%20AI%20that%20is%20much,by%20multinational%20investment%20firm%20BlackRock。
-
介绍了 Adam 优化器及其优点的文章:https://towardsdatascience.com/adam-latest-trends-in-deep-learning-optimization-6be9a291375c。
-
一个类似的股票预测项目的视频链接:https://www.youtube.com/watch?v=CbTU92pbDKw&ab_channel=GregHogg。


评论(0)