
探索 PyCaret 3.0 的最新增强和功能

由 Moez Ali 使用 Midjourney 生成
本文内容:
- 简介
- 稳定的时间序列预测模块
- 新的面向对象 API
- 更多实验记录选项
- 重构的预处理模块
- 兼容最新的 sklearn 版本
- 分布式并行模型训练
- 加速 CPU 上的模型训练
- 不再支持的 NLP 和 Arules 模块
- 更多信息
- 贡献者
简介
PyCaret 是一个开源的、低代码的 Python 机器学习库,可以自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,可以大大加速实验周期并提高你的生产力。
与其他开源机器学习库相比,PyCaret 是一种备选的低代码库,可以用几行代码替换数百行代码。这使得实验的速度和效率成倍增加。PyCaret 实质上是围绕 Python 中的几个机器学习库和框架的 Python 包装器。
PyCaret 的设计和简洁性受到了 Gartner 首次使用的“公民数据科学家”角色的影响。公民数据科学家是能够执行简单和中等复杂的分析任务的高级用户,这些任务以前需要更多的技术专业知识。

要了解更多关于 PyCaret 的信息,请查看我们的 GitHub 或 官方文档。
查看我们完整的 PyCaret 3.0 发布说明
📈 稳定的时间序列预测模块
PyCaret 的时间序列模块现在已经稳定,并在 3.0 版本中提供。目前,它支持预测任务,但计划在未来提供时间序列异常检测和聚类算法。
# load dataset
from pycaret.datasets import get_data
data = get_data('airline')
# init setup
from pycaret.time_series import *
s = setup(data, fh = 12, session_id = 123)
# compare models
best = compare_models()
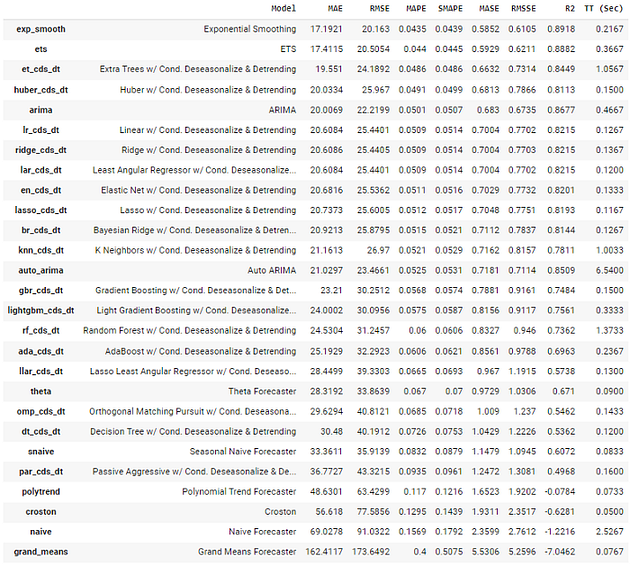
# forecast plot
plot_model(best, plot = 'forecast')
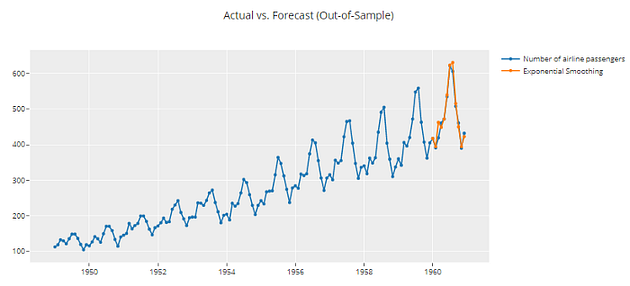
# forecast plot 36 days out in future
plot_model(best, plot = 'forecast', data_kwargs = {'fh' : 36})
💻 新的面向对象 API
尽管 PyCaret 是一个很棒的工具,但它并不遵循 Python 开发人员使用的典型面向对象编程实践。为了解决这个问题,我们不得不重新思考一些最初的设计决策,这是一个需要大量努力来实现的重大改变。现在,让我们看看这会对你产生什么影响。
# Functional API (Existing)
# load dataset
from pycaret.datasets import get_data
data = get_data('juice')
# init setup
from pycaret.classification import *
s = setup(data, target = 'Purchase', session_id = 123)
# compare models
best = compare_models()

在同一个 notebook 中做实验很好,但如果你想用不同的设置函数参数运行不同的实验,这可能是一个问题。虽然这是可能的,但以前实验的设置将被替换。
然而,通过我们的新的面向对象 API,你可以在同一个 notebook 中轻松地进行多个实验,并进行比较,没有任何困难。这是因为参数与对象相关联,可以与各种建模和预处理选项相关联。
# load dataset
from pycaret.datasets import get_data
data = get_data('juice')
# init setup 1
from pycaret.classification import ClassificationExperiment
exp1 = ClassificationExperiment()
exp1.setup(data, target = 'Purchase', session_id = 123)
# compare models init 1
best = exp1.compare_models()
# init setup 2
exp2 = ClassificationExperiment()
exp2.setup(data, target = 'Purchase', normalize = True, session_id = 123)
# compare models init 2
best2 = exp2.compare_models()
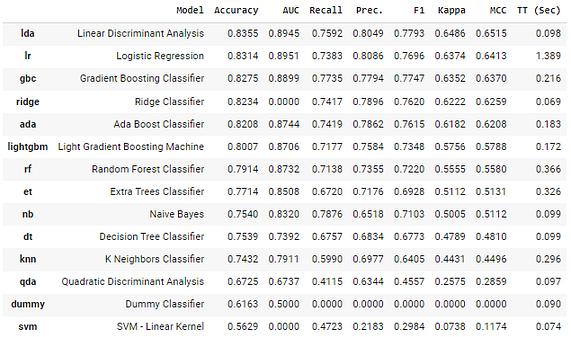
exp1.compare_models
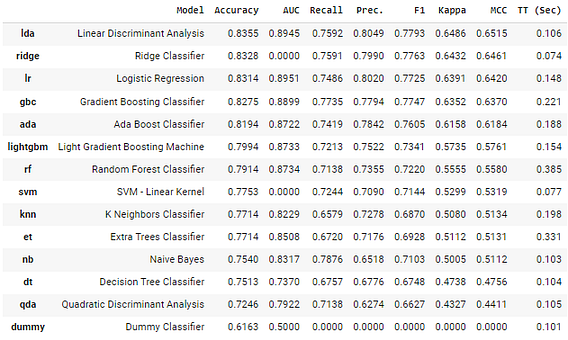
exp2.compare_models
进行实验后,你可以使用 get_leaderboard 函数为每个实验创建排行榜,更容易进行比较。
import pandas as pd
# generate leaderboard
leaderboard_exp1 = exp1.get_leaderboard()
leaderboard_exp2 = exp2.get_leaderboard()
lb = pd.concat([leaderboard_exp1, leaderboard_exp2])

输出被截断
# print pipeline steps
print(exp1.pipeline.steps)
print(exp2.pipeline.steps)

📊 更多实验记录选项
PyCaret 2 可以使用 MLflow 自动记录实验。虽然它仍然是默认值,但在 PyCaret 3 中有更多的实验记录选项。最新版本中新增加的选项有 <a class="af ma" href="https://wandb.ai/" rel="noopener ugc nofollow" target="_blank">wandb</a>、<a class="af ma" href="https://www.comet.com/site/" rel="noopener ugc nofollow" target="_blank">cometml</a> 和 <a class="af ma" href="https://www.dagshub.com" rel="noopener ugc nofollow" target="_blank">dagshub</a>。
要将记录器从默认的 MLflow 更改为其他可用选项,只需在 log_experiment 参数中传递以下之一:'mlflow'、'wandb'、'cometml'、'dagshub'。
🧹 重构的预处理模块
预处理模块经过完全的重新设计,以提高其效率和性能,同时确保与最新版本的Scikit-Learn兼容。
PyCaret 3包括了几种新的预处理功能,例如创新的分类编码技术,支持机器学习建模中的文本特征,新颖的异常值检测方法以及高级特征选择技术。
一些新特性包括:
- 新的分类编码方法
- 用于机器学习建模的文本特征处理
- 新的异常值检测方法
- 新的特征选择方法
- 保证避免目标泄漏,因为整个管道现在是在折叠级别上拟合的。
✅ 与最新的sklearn版本兼容
PyCaret 2严重依赖于scikit-learn 0.23.2,这使得不可能在同一个环境中同时使用最新的scikit-learn版本(1.X)和PyCaret。
PyCaret现在与最新版本的scikit-learn兼容,我们希望保持这种状态。
🔗 分布式并行模型训练
为了在大型数据集上进行扩展,你可以在分布式模式下在群集上运行compare_models函数。为此,你可以在compare_models函数中使用parallel参数。
这是因为Fugue的存在而变得可能,它是一个开源的统一接口,用于在Spark、Dask和Ray上执行Python、Pandas和SQL代码,最小化重写
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable', n_jobs = 1)
# create pyspark session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# import parallel back-end
from pycaret.parallel import FugueBackend
# compare models
best = compare_models(parallel = FugueBackend(spark))
🚀 在CPU上加速模型训练
你可以应用英特尔优化来进行机器学习算法,并加速你的工作流程。要使用Intel优化训练模型,需要安装Intel sklearnex库:
# install sklearnex
pip install scikit-learn-intelex
要使用英特尔优化,只需在create_model函数中传递engine = 'sklearnex'。
# Functional API (Existing)
# load dataset
from pycaret.datasets import get_data
data = get_data('bank')
# init setup
from pycaret.classification import *
s = setup(data, target = 'deposit', session_id = 123)
没有英特尔加速的模型训练:
%%time
lr = create_model('lr')
有英特尔加速的模型训练:
%%time
lr2 = create_model('lr', engine = 'sklearnex')
在模型性能上存在一些差异(在大多数情况下是微不足道的),但在时间上的改进约为30K行数据集的60%。在处理更大的数据集时,收益要高得多。
⚰️ ️RIP:NLP和Arules模块
NLP正在快速发展,有许多专门致力于解决端到端NLP任务的库和公司。由于缺乏资源,团队中的现有专业知识以及愿意维护和支持NLP和Arules的新贡献者,我们决定从PyCaret中删除它们。 PyCaret 3.0没有nlp和arules模块。它也已从文档中删除。你仍然可以使用旧版本的PyCaret。
ℹ️ 更多信息
📚 文档 开始使用PyCaret
📝 API参考 详细的API文档
⭐ 教程 如果你是PyCaret的新手,请查看我们的官方笔记本
📋 笔记本 由社区创建和维护
📙 博客 由贡献者提供的教程和文章
📺 视频 视频教程和活动
🎥 YouTube 订阅我们的YouTube频道
🤗 Slack 加入我们的Slack社区
💻 LinkedIn 关注我们的LinkedIn页面
📢 讨论 与社区和贡献者互动
🛠️ 发布说明
贡献者
感谢所有参与PyCaret 3的贡献者。
@ngupta23@Yard1@tvdboom@jinensetpal@goodwanghan@Alexsandruss@daikikatsuragawa@caron14@sherpan@haizadtarik@ethanglaser@kumar21120@satya-pattnaik@ltsaprounis@sayantan1410@AJarman@drmario-gh@NeptuneN@Abonia1@LucasSerra@desaizeeshan22@rhoboro@jonasvdd@PivovarA@ykskks@chrimaho@AnthonyA1223@ArtificialZeng@cspartalis@vladocodes@huangzhhui@keisuke-umezawa@ryankarlos@celestinoxp@qubiit@beckernick@napetrov@erwanlc@Danpilz@ryanxjhan@wkuopt@TremaMiguel@IncubatorShokuhou@moezali1```

评论(0)